





记录下自定义ios基座
为了测试推送,试下自定义基座 - iOS下遇到的坑 ;
官方文档
遇到的几个问题
1.product ->archive 为灰色 ;将选择设备(iphone11)的处 切换成 generic iOS device;


- 证书报错

HBuilder is automatically signed for development, but a conflicting code signing identity iPhone Distribution has been manually specified. Set the code signing identity value to "iPhone Developer" in the build settings editor, or switch to manual signing in the Signing & Capabilities editor.添加账号下证书,未添加的需要新增accout 苹果开发账号下的

debug 改好后,release 下也会报错,按下图修改

暂时这么多,再碰到问题以此添加,做个记录
为了测试推送,试下自定义基座 - iOS下遇到的坑 ;
官方文档
遇到的几个问题
1.product ->archive 为灰色 ;将选择设备(iphone11)的处 切换成 generic iOS device;
- 证书报错
HBuilder is automatically signed for development, but a conflicting code signing identity iPhone Distribution has been manually specified. Set the code signing identity value to "iPhone Developer" in the build settings editor, or switch to manual signing in the Signing & Capabilities editor.添加账号下证书,未添加的需要新增accout 苹果开发账号下的
debug 改好后,release 下也会报错,按下图修改
暂时这么多,再碰到问题以此添加,做个记录
收起阅读 »
修改胶囊按钮样式
作为一个强迫症患者,小程序sdk不能修改胶囊按钮样式,不能忍!
查看源码发现,按钮样式是这样设置的
uniMPSDK-release.aar ->io.dcloud.WebviewActivity ->onCreate
Typeface var3 = Typeface.createFromAsset(this.getAssets(), "fonts/dcloud_iconfont.ttf");
this.a.setText("\ue601");
this.a.setTypeface(var3);
this.a.getPaint().setTextSize((float)var2);
this.b.setText("\ue650");
this.b.setTypeface(var3);
this.b.getPaint().setTextSize((float)var2);
this.b.setVisibility(4);
this.e.setText("\ue606");
this.e.setTypeface(var3);
this.e.getPaint().setTextSize((float)var2);
this.d.setText("\ue606");
this.d.setTypeface(var3);最终通过加载 assets -> fonts/dcloud_iconfont.ttf 字体文件来设置
so!!!
利用android的资源overlay机制,将dcloud_iconfont.ttf文件进行修改,放入自己工程的assets/fonts中来覆盖默认样式
作为一个强迫症患者,小程序sdk不能修改胶囊按钮样式,不能忍!
查看源码发现,按钮样式是这样设置的
uniMPSDK-release.aar ->io.dcloud.WebviewActivity ->onCreate
Typeface var3 = Typeface.createFromAsset(this.getAssets(), "fonts/dcloud_iconfont.ttf");
this.a.setText("\ue601");
this.a.setTypeface(var3);
this.a.getPaint().setTextSize((float)var2);
this.b.setText("\ue650");
this.b.setTypeface(var3);
this.b.getPaint().setTextSize((float)var2);
this.b.setVisibility(4);
this.e.setText("\ue606");
this.e.setTypeface(var3);
this.e.getPaint().setTextSize((float)var2);
this.d.setText("\ue606");
this.d.setTypeface(var3);最终通过加载 assets -> fonts/dcloud_iconfont.ttf 字体文件来设置
so!!!
利用android的资源overlay机制,将dcloud_iconfont.ttf文件进行修改,放入自己工程的assets/fonts中来覆盖默认样式
【HbuilerX-Bug】终端无法显示打印信息,也无法输入
修改 powershell.exe的路径为绝对路径:
C:/Windows/System32/WindowsPowerShell/v1.0/powershell.exe

修改 powershell.exe的路径为绝对路径:
C:/Windows/System32/WindowsPowerShell/v1.0/powershell.exe

分享苹果内购requestPayment没有任何返回
是不是在沙盒模式下支付一次成功后,requestPayment没有任何返回,这种情况,可以卸载APP重新编译安装测试,应该就可以了
接苹果内购经验,这里说的不好,不好喷
按官网苹果内购支付按钮里,然后就是后端要做订单核验,如果不核验,就不会返回的,所以接内购的时候,需要后端配合核验订单,如果自己调试,那就支付一次之后就卸载重新编译安装应该会再次回调requestPayment的几个函数了。
流程:
1、将金额资料发送到服务端,生成一个订单号
2、收到订单号后执行uni.requestPayment这个方法
3、在success回调中再次请问后端核验订单,这个时候可以将transactionReceipt和订单号传过去,进行订单修改状态操作
是不是在沙盒模式下支付一次成功后,requestPayment没有任何返回,这种情况,可以卸载APP重新编译安装测试,应该就可以了
接苹果内购经验,这里说的不好,不好喷
按官网苹果内购支付按钮里,然后就是后端要做订单核验,如果不核验,就不会返回的,所以接内购的时候,需要后端配合核验订单,如果自己调试,那就支付一次之后就卸载重新编译安装应该会再次回调requestPayment的几个函数了。
流程:
1、将金额资料发送到服务端,生成一个订单号
2、收到订单号后执行uni.requestPayment这个方法
3、在success回调中再次请问后端核验订单,这个时候可以将transactionReceipt和订单号传过去,进行订单修改状态操作
收起阅读 »Hbuildx打包失败
信息:* What went wrong:
Execution failed for task ':app:transformClassesWithMultidexlistForRelease'.
> com.android.build.api.transform.TransformException: Error while generating the main dex list.
- Try:
Run with --debug option to get more log output. Run with --scan to get full insights.
解决方案:如图
信息:* What went wrong:
Execution failed for task ':app:transformClassesWithMultidexlistForRelease'.
> com.android.build.api.transform.TransformException: Error while generating the main dex list.
- Try:
Run with --debug option to get more log output. Run with --scan to get full insights.
解决方案:如图
收起阅读 »iOS 提交App Store 审核被拒2.3.10和解决记录
在苹果的上架平台上,版本信息出现安卓相关,修改上架版本信息(删除安卓俩字),重新提交审核即可
在苹果的上架平台上,版本信息出现安卓相关,修改上架版本信息(删除安卓俩字),重新提交审核即可

[分享]网易新闻WebApp模板源码下载及交互体验
BUI-163
大小: 6.27M
网易新闻
该App基于BUI Webapp框架+Dcloud构建. 仅供学习交流使用.
-
交互1: 下拉刷新, 加载分页

-
交互2: Tab嵌套交互

-
交互3: 栏目删减自动更新
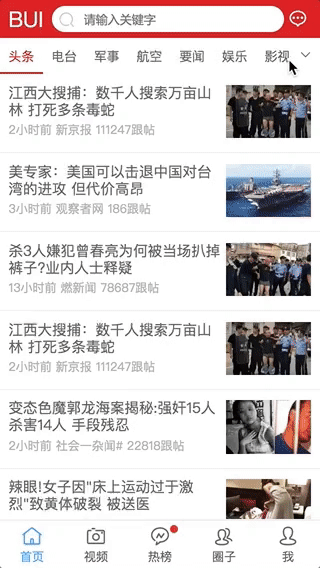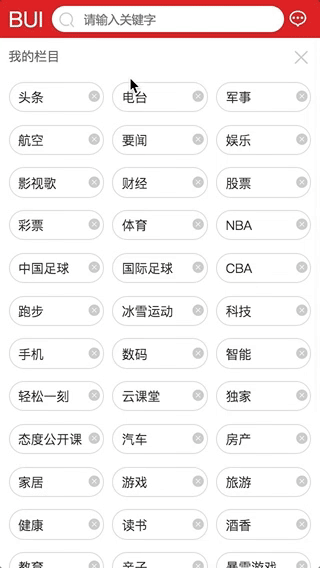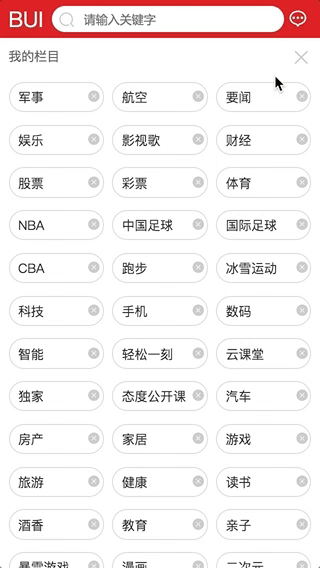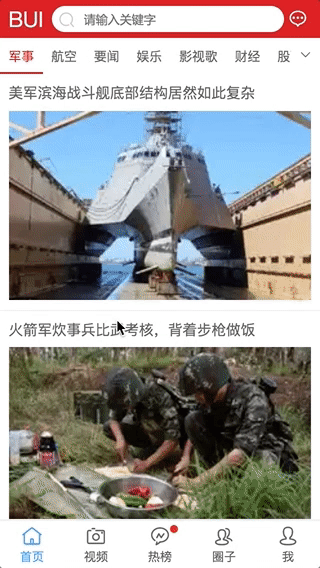
-
交互4: 底部tab的交互, 每个Tab里面还有各自的交互




源码下载: https://github.com/imouou/BUI-163
App体验下载: http://d.firim.top/zcdj
BUI-163
大小: 6.27M
网易新闻
该App基于BUI Webapp框架+Dcloud构建. 仅供学习交流使用.
-
交互1: 下拉刷新, 加载分页
-
交互2: Tab嵌套交互
-
交互3: 栏目删减自动更新
-
交互4: 底部tab的交互, 每个Tab里面还有各自的交互
源码下载: https://github.com/imouou/BUI-163
App体验下载: http://d.firim.top/zcdj
收起阅读 »如何将经过处理的照片保存到本地呢?
照片处理之后,怎样保存到相册里,void plus.gallery.save( path, successCB, errorCB ); api只有这一句,这个path是保存路径,那么保存源是什么?
照片处理之后,怎样保存到相册里,void plus.gallery.save( path, successCB, errorCB ); api只有这一句,这个path是保存路径,那么保存源是什么?
uniapp - 图片缩放 (平面图显示)
需求 因为要显示楼层平面图片,并且需要缩放,
不同于查看类型的,有时候需要显示 标记点。所以其他帖子上看的用不到,就自己写了个。
单纯uniapp + image + canvas(显示标记需要使用canvas) 实现;
遇到的坑 : 之前没主要看文档,没使用movable-area,纯canvas 实现,但是有时候一张图标记点会有几百个,并且canvas 在ios好像是有限制 大于1000px 不显示。标记多多时候,会出现卡的问题。
目前实现的代码 外部 使用movable-area ,需要显示标记点,在用canvas 。
图片缩放实现
因为多处使用,自定义了组件
附上代码
<template>
<view class="">
<!-- :style="{height:screenH+'upx'}" -->
<movable-area scale-area>
<movable-view :style="{width:baseInfo.width+'upx',height:baseInfo.height+'upx'}" direction="all" @scale="onScale"
@change="onChange" scale :scale-min="minScale" :scale-max="2" :scale-value="scale" >
<image :src="baseInfo.path" :style="{width:baseInfo.width+'upx',height:baseInfo.height+'upx'}"></image>
</movable-view>
</movable-area>
</view>
</template>
<script>
export default {
props: {
baseInfo: {
type: Object,
default: function(e) {
return {}
}
}
},
data() {
return {
minScale: 0.1,
x: 0,
y: 0,
scale: 0.5,// 定义缩放倍数
old: {
x: 0,
y: 0,
scale: 2
},
}
},
methods: {
onChange: function(e) {
// console.log(e)
this.old.x = e.detail.x
this.old.y = e.detail.y
},
onScale: function(e) {
// console.log(e)
this.old.scale = e.detail.scale;
this.x = this.old.x
this.y = this.old.y
this.$nextTick(function() {
this.x = 0
this.y = 0
})
},
// onLoad:function(){
// this.getStyle();
// },
}
}
</script>
<style lang="scss" scoped>
movable-view {
display: flex;
align-items: center;
justify-content: center;
top: 0;
left: 0;
// top:140upx;
// width:750upx;
// height:1476upx;
// background-color: #007AFF;
color: #fff;
}
movable-area {
height: calc(100vh);
width: 750upx;
background-color: #fff;
overflow: hidden;
}
</style>
使用代码
<view v-if='imageInfo !== ""'>
<view-img :baseInfo="imageInfo" :style="style"></view-img>
</view>
js
import viewImg from "./viewImg.vue"; //名字随意 引入使用
//就不附上全部js ,此处不知道看基础文档,没啥要说的
components: {
viewImg
},图片我这是url ,需要获取图片信息 ;因为防止 url重复不停等调用,我 本地缓存了 ,如果有这个需要,大家也可以这样。本地缓存这,ios/安卓 有点不太一样,我后面写到了就顺带提一下吧
imgInit() {
// var context = uni.createCanvasContext('firstCanvas')
var that = this;
//获取图片链接;
var pictureUrl = uni.getStorageSync("pictureUrl"); // 接口返回需要显示的url
var picFile = uni.getStorageSync("picFile"); // 存本地地址,不要的存本地 ,直接使用url 不用考虑 安卓和ios。的问题直接使用,
//这边就贴上 在线的吧;
uni.getImageInfo({
src: pictureUrl,
success: function(image) {
// uni.showLoading({
// title: "初次进入,请耐心等待..."
// });
that.imageInfo = image; // 使用
console.log(image)
uni.setStorageSync("picFile", image.path);
var s0 = Math.floor((that.screenW / image.width) * 100) / 100;
// console.log("s0:" + s0);
var s1 = Math.floor((that.screenH / image.height) * 100) / 100;
// console.log("s1:" + s1);
// that.scale = s0 < s1 ? s0 : s1;
that.minScale = s0 < s1 ? s0 : s1;
},
fail: function(image) {
console.log(3);
}
});
}
在此处说下 安卓和ios的问题吧 ;
如果需要本地存储,ios中需要将图片下载后,在使用;安卓可以直接 使用 getImageInfo ,为了保持一直不管安卓还是ios ,我这都下载保存了。
同时,此处因为图片下载了,所以如果图片进行了更换,记得删除下本地的图片;
贴上部分代码,官方文档都有
var imageUrl = "http://xxxxxx.jpg/png"
uni.downloadFile({ // ios 需要下载后,保存到本地 ,
url: imageUrl,
success: (res) => {
console.log("首次加载,下载成功");
console.log(res);
uni.saveFile({
tempFilePath: res.tempFilePath,
success: function(image) {
console.log("存储后,本地信息")
console.log(image);
that.insertFloor(image.savedFilePath);
that.imgInit2(image.savedFilePath)
that.hideLoading();
}
})
}
})
//删除本地图片代码
deleteImg(path) {
//删除已缓存 图片;
console.log("链接已更换,删除愿保存图片")
uni.removeSavedFile({
filePath: path,
complete: function(res) {
console.log(res)
}
})
},
比较简单 希望有用
canvas 仅用在 需要查看标记点的(后期有空写)
需求 因为要显示楼层平面图片,并且需要缩放,
不同于查看类型的,有时候需要显示 标记点。所以其他帖子上看的用不到,就自己写了个。
单纯uniapp + image + canvas(显示标记需要使用canvas) 实现;
遇到的坑 : 之前没主要看文档,没使用movable-area,纯canvas 实现,但是有时候一张图标记点会有几百个,并且canvas 在ios好像是有限制 大于1000px 不显示。标记多多时候,会出现卡的问题。
目前实现的代码 外部 使用movable-area ,需要显示标记点,在用canvas 。
图片缩放实现
因为多处使用,自定义了组件
附上代码
<template>
<view class="">
<!-- :style="{height:screenH+'upx'}" -->
<movable-area scale-area>
<movable-view :style="{width:baseInfo.width+'upx',height:baseInfo.height+'upx'}" direction="all" @scale="onScale"
@change="onChange" scale :scale-min="minScale" :scale-max="2" :scale-value="scale" >
<image :src="baseInfo.path" :style="{width:baseInfo.width+'upx',height:baseInfo.height+'upx'}"></image>
</movable-view>
</movable-area>
</view>
</template>
<script>
export default {
props: {
baseInfo: {
type: Object,
default: function(e) {
return {}
}
}
},
data() {
return {
minScale: 0.1,
x: 0,
y: 0,
scale: 0.5,// 定义缩放倍数
old: {
x: 0,
y: 0,
scale: 2
},
}
},
methods: {
onChange: function(e) {
// console.log(e)
this.old.x = e.detail.x
this.old.y = e.detail.y
},
onScale: function(e) {
// console.log(e)
this.old.scale = e.detail.scale;
this.x = this.old.x
this.y = this.old.y
this.$nextTick(function() {
this.x = 0
this.y = 0
})
},
// onLoad:function(){
// this.getStyle();
// },
}
}
</script>
<style lang="scss" scoped>
movable-view {
display: flex;
align-items: center;
justify-content: center;
top: 0;
left: 0;
// top:140upx;
// width:750upx;
// height:1476upx;
// background-color: #007AFF;
color: #fff;
}
movable-area {
height: calc(100vh);
width: 750upx;
background-color: #fff;
overflow: hidden;
}
</style>
使用代码
<view v-if='imageInfo !== ""'>
<view-img :baseInfo="imageInfo" :style="style"></view-img>
</view>
js
import viewImg from "./viewImg.vue"; //名字随意 引入使用
//就不附上全部js ,此处不知道看基础文档,没啥要说的
components: {
viewImg
},图片我这是url ,需要获取图片信息 ;因为防止 url重复不停等调用,我 本地缓存了 ,如果有这个需要,大家也可以这样。本地缓存这,ios/安卓 有点不太一样,我后面写到了就顺带提一下吧
imgInit() {
// var context = uni.createCanvasContext('firstCanvas')
var that = this;
//获取图片链接;
var pictureUrl = uni.getStorageSync("pictureUrl"); // 接口返回需要显示的url
var picFile = uni.getStorageSync("picFile"); // 存本地地址,不要的存本地 ,直接使用url 不用考虑 安卓和ios。的问题直接使用,
//这边就贴上 在线的吧;
uni.getImageInfo({
src: pictureUrl,
success: function(image) {
// uni.showLoading({
// title: "初次进入,请耐心等待..."
// });
that.imageInfo = image; // 使用
console.log(image)
uni.setStorageSync("picFile", image.path);
var s0 = Math.floor((that.screenW / image.width) * 100) / 100;
// console.log("s0:" + s0);
var s1 = Math.floor((that.screenH / image.height) * 100) / 100;
// console.log("s1:" + s1);
// that.scale = s0 < s1 ? s0 : s1;
that.minScale = s0 < s1 ? s0 : s1;
},
fail: function(image) {
console.log(3);
}
});
}
在此处说下 安卓和ios的问题吧 ;
如果需要本地存储,ios中需要将图片下载后,在使用;安卓可以直接 使用 getImageInfo ,为了保持一直不管安卓还是ios ,我这都下载保存了。
同时,此处因为图片下载了,所以如果图片进行了更换,记得删除下本地的图片;
贴上部分代码,官方文档都有
var imageUrl = "http://xxxxxx.jpg/png"
uni.downloadFile({ // ios 需要下载后,保存到本地 ,
url: imageUrl,
success: (res) => {
console.log("首次加载,下载成功");
console.log(res);
uni.saveFile({
tempFilePath: res.tempFilePath,
success: function(image) {
console.log("存储后,本地信息")
console.log(image);
that.insertFloor(image.savedFilePath);
that.imgInit2(image.savedFilePath)
that.hideLoading();
}
})
}
})
//删除本地图片代码
deleteImg(path) {
//删除已缓存 图片;
console.log("链接已更换,删除愿保存图片")
uni.removeSavedFile({
filePath: path,
complete: function(res) {
console.log(res)
}
})
},
比较简单 希望有用
canvas 仅用在 需要查看标记点的(后期有空写)
APP出现安卓拨打电话无反应
找到项目的manifest.json>APP权限配置,查看以下两项是否勾选,若没有勾选,请勾选上,重新打包测试,(若改变线上的app拨打电话功能,需重新打包上架)
<uses-permission android:name="android.permission.CALL_PHONE"/>
<uses-permission android:name="android.permission.MODIFY_PHONE_STATE"/>
找到项目的manifest.json>APP权限配置,查看以下两项是否勾选,若没有勾选,请勾选上,重新打包测试,(若改变线上的app拨打电话功能,需重新打包上架)
<uses-permission android:name="android.permission.CALL_PHONE"/>
<uses-permission android:name="android.permission.MODIFY_PHONE_STATE"/>
iOS 提交App Store 审核被拒2.3.10和解决记录
被拒原因:Guideline 2.3.10 - Performance - Accurate Metadata
We noticed that your app or its metadata includes irrelevant third-party platform information.
Specifically, your app is selling non-iOS devices.
Referencing third-party platforms in your app or its metadata is not permitted on the App Store unless there is specific interactive functionality.
Next Steps
To resolve this issue, please remove all instances of this information from your app and its metadata, including the app description, promotional text, What's New info, previews, and screenshots.
Please see attached screenshots for details.
被拒图片:https://iosapps-ssl.itunes.apple.com/itunes-assets/Purple124/v4/46/e8/c2/46e8c259-45d0-5fda-7925-bacac12347a8/attachment.Screenshot-0813-062022.png?accessKey=1597626616_1861666966954208641_Xvm00ihfaw8mFViluTUKpbyum9X5LwzQs%2BmuHHW0oqoBNYPlwiR2VaWFpYf5GQ7SWvq1fUh6jw3B%2B1oMJWNIAQIo7PYV0fWjLbPpi2fE7LbfomWUZ6Fu%2Fl10Hm8itG47oEfgAuaK7QhEAnLCi2%2B7yoTCBIttWPSzZ3zFZ5FYgHEeTpFY75uFNgJSFJcz7D6b
解决方案:在后台设置苹果手机搜索请求的数据到的数据尽量是ios的商品不要有安卓类的(我的解决方案,用搜索词在后台设置苹果手机请求到的数据是苹果的,例如:手机,电脑,平板,数据线耳机等,在苹果手机搜索出来的商品基本都是苹果的,等审核通过后,再改回之前的数据,此方法只是暂时的,利于苹果审核)
被拒原因:Guideline 2.3.10 - Performance - Accurate Metadata
We noticed that your app or its metadata includes irrelevant third-party platform information.
Specifically, your app is selling non-iOS devices.
Referencing third-party platforms in your app or its metadata is not permitted on the App Store unless there is specific interactive functionality.
Next Steps
To resolve this issue, please remove all instances of this information from your app and its metadata, including the app description, promotional text, What's New info, previews, and screenshots.
Please see attached screenshots for details.
被拒图片:https://iosapps-ssl.itunes.apple.com/itunes-assets/Purple124/v4/46/e8/c2/46e8c259-45d0-5fda-7925-bacac12347a8/attachment.Screenshot-0813-062022.png?accessKey=1597626616_1861666966954208641_Xvm00ihfaw8mFViluTUKpbyum9X5LwzQs%2BmuHHW0oqoBNYPlwiR2VaWFpYf5GQ7SWvq1fUh6jw3B%2B1oMJWNIAQIo7PYV0fWjLbPpi2fE7LbfomWUZ6Fu%2Fl10Hm8itG47oEfgAuaK7QhEAnLCi2%2B7yoTCBIttWPSzZ3zFZ5FYgHEeTpFY75uFNgJSFJcz7D6b
解决方案:在后台设置苹果手机搜索请求的数据到的数据尽量是ios的商品不要有安卓类的(我的解决方案,用搜索词在后台设置苹果手机请求到的数据是苹果的,例如:手机,电脑,平板,数据线耳机等,在苹果手机搜索出来的商品基本都是苹果的,等审核通过后,再改回之前的数据,此方法只是暂时的,利于苹果审核)
收起阅读 »关于热更新的实现
在App.vue文件里onLaunch: function () {}方法实现如下:
//判断客户端,根据业务来判断你是否需要传此参数 ,不要删掉即可
var clent=uni.getSystemInfoSync().platform
var client_category=2
if(clent=='android'){
client_category=2
}
if(clent=='ios'){
client_category=1
}
plus.runtime.getProperty(plus.runtime.appid, function(widgetInfo) {
// console.log("widgetInfo.version:"+widgetInfo.version)
uni.request({
url:'https://url/api/get_versions',
data: {
"version": widgetInfo.version,
"client_category":client_category
},
success: (result) => {
var data = result.data;
// is_update 是否热更新
//wgt_url 热更新包地址
if ((data.is_update==true) &&(data.wgt_url != '' ))) {
// uni.showLoading({
// title:'努力加载中...'
// })
// console.log("data.is_update :"+data.is_update)
// console.log("data.wgt_url :"+data.wgt_url )
uni.downloadFile({
url: data.wgt_url,
success: (downloadResult) => {
if (downloadResult.statusCode === 200) {
plus.runtime.install(downloadResult.tempFilePath, {
force: false
}, function() {
// uni.hideLoading()
plus.runtime.restart();
}, function(e) {
// console.log("热更新:"+JSON.stringify(e))
});
}
}
});
}
} ,
});
}); 在App.vue文件里onLaunch: function () {}方法实现如下:
//判断客户端,根据业务来判断你是否需要传此参数 ,不要删掉即可
var clent=uni.getSystemInfoSync().platform
var client_category=2
if(clent=='android'){
client_category=2
}
if(clent=='ios'){
client_category=1
}
plus.runtime.getProperty(plus.runtime.appid, function(widgetInfo) {
// console.log("widgetInfo.version:"+widgetInfo.version)
uni.request({
url:'https://url/api/get_versions',
data: {
"version": widgetInfo.version,
"client_category":client_category
},
success: (result) => {
var data = result.data;
// is_update 是否热更新
//wgt_url 热更新包地址
if ((data.is_update==true) &&(data.wgt_url != '' ))) {
// uni.showLoading({
// title:'努力加载中...'
// })
// console.log("data.is_update :"+data.is_update)
// console.log("data.wgt_url :"+data.wgt_url )
uni.downloadFile({
url: data.wgt_url,
success: (downloadResult) => {
if (downloadResult.statusCode === 200) {
plus.runtime.install(downloadResult.tempFilePath, {
force: false
}, function() {
// uni.hideLoading()
plus.runtime.restart();
}, function(e) {
// console.log("热更新:"+JSON.stringify(e))
});
}
}
});
}
} ,
});
}); 