





文件上传uploadfile问题记录
问题1:文件上传多个图片,只返回一个

问题2:视频app上传,只支持mp4,mov上传,data返回空
场景介绍:页面1选择视频(uni.chooseVideo)返回临时文件url,传值给页面2上传(uni.uploadFile),data返回空,statusCode":500
尝试1:页面1选择视频直接上传,仍然data返回空,statusCode":500,无效
尝试2:页面1选择视频改为plus(plus.gallery.pick),再上传 。 无效
最终解决:控制上传视频大小,不能超过1M,res.size<=1048576,与视频格式无关
问题1:文件上传多个图片,只返回一个
问题2:视频app上传,只支持mp4,mov上传,data返回空
场景介绍:页面1选择视频(uni.chooseVideo)返回临时文件url,传值给页面2上传(uni.uploadFile),data返回空,statusCode":500
尝试1:页面1选择视频直接上传,仍然data返回空,statusCode":500,无效
尝试2:页面1选择视频改为plus(plus.gallery.pick),再上传 。 无效
最终解决:控制上传视频大小,不能超过1M,res.size<=1048576,与视频格式无关
收起阅读 »uniapp中拿到base64转blob对象,或base64转bytes字节数组,io操作写入字节流文件bytes
**1. uniAPP中拿到附件的base64如何操作,如word文件
/**
- 实现思路:
- 通过native.js的io操作创建文件,拿到平台绝对路径
- 再通过原生类进行base64解码,拿到字节流bytes数组
- 在通过java类FileOutputStream进行文件写入bytes返回文件路径path
- 在通过plus.runtime.openFile(path);用第三方程序打开文件
- */**
//文件的写入操作传入要写入文件名,base64 function lzFileWriter(base64,fileName) { return new Promise((result,reject)=>{ // PRIVATE_WWW:本地文件系统常量,Number类型,固定值1。应用运行资源目录,仅本应用可访问。 为了确保应用资源的安全性,此目录只可读。 // PRIVATE_DOC 本地文件系统常量,Number类型,固定值2。应用私有文档目录,仅本应用可读写。 plus.io.requestFileSystem(plus.io.PRIVATE_DOC, function(fs) { /* fs.root是根目录操作对象DirectoryEntry getFile(path,flag,succesCB,errorCB)创建或打开文件 path: ( DOMString ) 必选 要操作文件相对于当前目录的地址 flag: ( Flags ) 可选 要操作文件或目录的参数 create: (Boolean 类型 )是否创建对象标记 指示如果文件或目录不存在时是否进行创建,默认值为false succesCB: ( EntrySuccessCallback ) 可选 创建或打开文件成功的回调函数 errorCB: ( FileErrorCallback ) 可选 创建或打开文件失败的回调函数 */ // 创建或打开文件 fs.root.getFile(fileName,{create:true},function(fileEntry) { // 获得平台绝对路径 var fullPath = fileEntry.fullPath; console.log('平台绝对路径',fullPath); // 引入安卓原生类 var Base64 = plus.android.importClass("android.util.Base64"); var FileOutputStream = plus.android.importClass("java.io.FileOutputStream"); //如果文件不存在则创建文件,如果文件存在则删除文件后重新创建文件 var out = new FileOutputStream(fullPath); /** * 此处需要把base64前缀去除,在写入字节流数组 * 去除头部data:image/jpg;base64,留下base64编码后的字符串 **/ let index=base64.indexOf(',') let base64Str=base64.slice(index+1,base64.length) console.log(base64Str.slice(0,55)); //base64解密得到字节流bytes; var bytes = Base64.decode(base64Str,0); try{ console.log(bytes); out.write(bytes); // byte 数组写入此文件输出流中。 out.flush(); //刷新写入文件中去。 out.close(); //关闭此文件输出流并释放与此流有关的所有系统资源。 result(fullPath) }catch(e){ console.log(e.message); reject(e.message) } // 下面的方法只能写入字符串,无法写入字节流bytes // fileEntry文件系统中的文件对象,用于管理特定的本地文件 // fileEntry.file(function(file) { // /*createWriter获取文件关联的写文件操作对象FileWriter // abort: 终止文件写入操作 // seek: 定位文件操作位置 // truncate: 按照指定长度截断文件 // write: 向文件中写入数据 // */ // fileEntry.createWriter(function(FileWriter) { // FileWriter.write(base64); // FileWriter.onwriteend=function(res){ // console.log(res.target.fileName); // result(res.target.fileName) // } // FileWriter.onerror=function(error){ // console.log(error); // reject(error) // } // }, function(e) { // console.log(e); // }); // }); }); }); }) }2.拿到视频,音频,图片的base64如何操作?
/**
- 实现思路:
- 视频和音频拿到base64,可通过h5方式将base64转成blob对象
- 再通过URL.createObjectURL(blob)生成指向File对象或Blob对象的URL,
- 此url可以放到大部分标签下的src中进行渲染,如img,video,audio
-
*/
第一步:新建一个vue页面传入base64,创建webviewcreate(){ let that=this var currentWebview = this.$scope.$getAppWebview() //创建Webview窗口,用于加载新的HTML页面,可通过styles设置Webview窗口的样式,创建完成后需要调用show方法才能将Webview窗口显示出来。 let wv = plus.webview.create("/hybrid/html/pages/filePlay.html","/hybrid/html/pages/filePlay.html",{ 'uni-app': 'none', //不加载uni-app渲染层框架,避免样式冲突 top: 0, height: '100%', background: 'transparent' },{ base64:that.base64,//传参 type:that.type//文件类型 }); // 在Webview窗口中添加子窗口// ${that}.bbb(objecturl) currentWebview.append(wv); },第二步:在filePlay.html中拿到base64
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>文件播放系统</title> <style type="text/css"> html, body { padding: 0; margin: 0; } #App { background: transparent; width: 100vw; height: 100vh; display: flex; flex-direction: column; } #App .video { width: 100%; height: 100%; } #App .audio { margin: auto; } </style> </head> <body> <div id="App"> <video :src="videoSrc" autoplay v-if="videoSrc" controls class="video"></video> <!-- <img :src="imgSrc" v-if="imgSrc"/> --> <audio id="myAudio" controls v-if="audioSrc" class="audio"> <source :src="audioSrc" type="audio/ogg"> <source :src="audioSrc" type="audio/mpeg"> 暂不支持播放此类型 </audio> <iframe :src='wordSrc' width='100%' height='100%' frameborder='1' v-if="wordSrc"></iframe> </div> <!-- uni 的 SDK --> <script type="text/javascript" src="https://js.cdn.aliyun.dcloud.net.cn/dev/uni-app/uni.webview.1.5.2.js"></script> <script type="text/javascript" src="../js/vue.js"></script> <script type="text/javascript" src="../js/global.js"></script> <script type="text/javascript" src="../js/file-saver/dist/FileSaver.js"></script> <!-- <script type="text/javascript" src="../js/wps/web-office-sdk-v1.1.2.umd.js"></script> --> <script type="text/javascript"> // import { saveAs } from '../js/file-saver/dist/FileSaver.js'; document.addEventListener('UniAppJSBridgeReady', function() { let that //webview传参到html5网页 let { base64, type } = plus.webview.currentWebview(); console.log(base64.slice(0, 50)); new Vue({ el: '#App', data: { videoSrc: '', imgSrc: '', audioSrc: '', wordSrc: '', aHref: "" }, async mounted() { that = this let blob = that.dataURLtoBlob(base64) /** * URL对象用于生成指向File对象或Blob对象的URL。 * 这个URL可以放置于任何通常可以放置URL的地方,比如img标签的src属性 **/ var blobUrl = URL.createObjectURL(blob); console.log(blobUrl); console.log(type); if (type == 'video') { that.videoSrc = blobUrl } else if (type == 'audio') { that.audioSrc = blobUrl } else if (type == 'word') { } // 在每次调用createObjectURL()方法时,都会创建一个新的URL对象,即使你已经用相同的对象作为参数创建过。当不再需要这些URL对象时,每个对象必须通过调用URL.revokeObjectURL()方法来释放 setTimeout(() => { window.URL.revokeObjectURL(objecturl); //释放createObjectURL创建得对象 }, 2000) }, methods: { //base64转成blob对象第一种方式 dataURLtoBlob(dataurl) { var arr = dataurl.split(','), mime = arr[0].match(/:(.*?);/)[1], bstr = atob(arr[1]), n = bstr.length, u8arr = new Uint8Array(n);//8位无符号整数,长度1个字节 console.log(mime) while (n--) { u8arr[n] = bstr.charCodeAt(n); } // console.log(JSON.stringify(u8arr)); return new Blob([u8arr], { type: mime }); }, } }) }); </script> </body> </html>
**1. uniAPP中拿到附件的base64如何操作,如word文件
/**
- 实现思路:
- 通过native.js的io操作创建文件,拿到平台绝对路径
- 再通过原生类进行base64解码,拿到字节流bytes数组
- 在通过java类FileOutputStream进行文件写入bytes返回文件路径path
- 在通过plus.runtime.openFile(path);用第三方程序打开文件
- */**
//文件的写入操作传入要写入文件名,base64 function lzFileWriter(base64,fileName) { return new Promise((result,reject)=>{ // PRIVATE_WWW:本地文件系统常量,Number类型,固定值1。应用运行资源目录,仅本应用可访问。 为了确保应用资源的安全性,此目录只可读。 // PRIVATE_DOC 本地文件系统常量,Number类型,固定值2。应用私有文档目录,仅本应用可读写。 plus.io.requestFileSystem(plus.io.PRIVATE_DOC, function(fs) { /* fs.root是根目录操作对象DirectoryEntry getFile(path,flag,succesCB,errorCB)创建或打开文件 path: ( DOMString ) 必选 要操作文件相对于当前目录的地址 flag: ( Flags ) 可选 要操作文件或目录的参数 create: (Boolean 类型 )是否创建对象标记 指示如果文件或目录不存在时是否进行创建,默认值为false succesCB: ( EntrySuccessCallback ) 可选 创建或打开文件成功的回调函数 errorCB: ( FileErrorCallback ) 可选 创建或打开文件失败的回调函数 */ // 创建或打开文件 fs.root.getFile(fileName,{create:true},function(fileEntry) { // 获得平台绝对路径 var fullPath = fileEntry.fullPath; console.log('平台绝对路径',fullPath); // 引入安卓原生类 var Base64 = plus.android.importClass("android.util.Base64"); var FileOutputStream = plus.android.importClass("java.io.FileOutputStream"); //如果文件不存在则创建文件,如果文件存在则删除文件后重新创建文件 var out = new FileOutputStream(fullPath); /** * 此处需要把base64前缀去除,在写入字节流数组 * 去除头部data:image/jpg;base64,留下base64编码后的字符串 **/ let index=base64.indexOf(',') let base64Str=base64.slice(index+1,base64.length) console.log(base64Str.slice(0,55)); //base64解密得到字节流bytes; var bytes = Base64.decode(base64Str,0); try{ console.log(bytes); out.write(bytes); // byte 数组写入此文件输出流中。 out.flush(); //刷新写入文件中去。 out.close(); //关闭此文件输出流并释放与此流有关的所有系统资源。 result(fullPath) }catch(e){ console.log(e.message); reject(e.message) } // 下面的方法只能写入字符串,无法写入字节流bytes // fileEntry文件系统中的文件对象,用于管理特定的本地文件 // fileEntry.file(function(file) { // /*createWriter获取文件关联的写文件操作对象FileWriter // abort: 终止文件写入操作 // seek: 定位文件操作位置 // truncate: 按照指定长度截断文件 // write: 向文件中写入数据 // */ // fileEntry.createWriter(function(FileWriter) { // FileWriter.write(base64); // FileWriter.onwriteend=function(res){ // console.log(res.target.fileName); // result(res.target.fileName) // } // FileWriter.onerror=function(error){ // console.log(error); // reject(error) // } // }, function(e) { // console.log(e); // }); // }); }); }); }) }2.拿到视频,音频,图片的base64如何操作?
/**
- 实现思路:
- 视频和音频拿到base64,可通过h5方式将base64转成blob对象
- 再通过URL.createObjectURL(blob)生成指向File对象或Blob对象的URL,
- 此url可以放到大部分标签下的src中进行渲染,如img,video,audio
-
*/
第一步:新建一个vue页面传入base64,创建webviewcreate(){ let that=this var currentWebview = this.$scope.$getAppWebview() //创建Webview窗口,用于加载新的HTML页面,可通过styles设置Webview窗口的样式,创建完成后需要调用show方法才能将Webview窗口显示出来。 let wv = plus.webview.create("/hybrid/html/pages/filePlay.html","/hybrid/html/pages/filePlay.html",{ 'uni-app': 'none', //不加载uni-app渲染层框架,避免样式冲突 top: 0, height: '100%', background: 'transparent' },{ base64:that.base64,//传参 type:that.type//文件类型 }); // 在Webview窗口中添加子窗口// ${that}.bbb(objecturl) currentWebview.append(wv); },第二步:在filePlay.html中拿到base64
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>文件播放系统</title> <style type="text/css"> html, body { padding: 0; margin: 0; } #App { background: transparent; width: 100vw; height: 100vh; display: flex; flex-direction: column; } #App .video { width: 100%; height: 100%; } #App .audio { margin: auto; } </style> </head> <body> <div id="App"> <video :src="videoSrc" autoplay v-if="videoSrc" controls class="video"></video> <!-- <img :src="imgSrc" v-if="imgSrc"/> --> <audio id="myAudio" controls v-if="audioSrc" class="audio"> <source :src="audioSrc" type="audio/ogg"> <source :src="audioSrc" type="audio/mpeg"> 暂不支持播放此类型 </audio> <iframe :src='wordSrc' width='100%' height='100%' frameborder='1' v-if="wordSrc"></iframe> </div> <!-- uni 的 SDK --> <script type="text/javascript" src="https://js.cdn.aliyun.dcloud.net.cn/dev/uni-app/uni.webview.1.5.2.js"></script> <script type="text/javascript" src="../js/vue.js"></script> <script type="text/javascript" src="../js/global.js"></script> <script type="text/javascript" src="../js/file-saver/dist/FileSaver.js"></script> <!-- <script type="text/javascript" src="../js/wps/web-office-sdk-v1.1.2.umd.js"></script> --> <script type="text/javascript"> // import { saveAs } from '../js/file-saver/dist/FileSaver.js'; document.addEventListener('UniAppJSBridgeReady', function() { let that //webview传参到html5网页 let { base64, type } = plus.webview.currentWebview(); console.log(base64.slice(0, 50)); new Vue({ el: '#App', data: { videoSrc: '', imgSrc: '', audioSrc: '', wordSrc: '', aHref: "" }, async mounted() { that = this let blob = that.dataURLtoBlob(base64) /** * URL对象用于生成指向File对象或Blob对象的URL。 * 这个URL可以放置于任何通常可以放置URL的地方,比如img标签的src属性 **/ var blobUrl = URL.createObjectURL(blob); console.log(blobUrl); console.log(type); if (type == 'video') { that.videoSrc = blobUrl } else if (type == 'audio') { that.audioSrc = blobUrl } else if (type == 'word') { } // 在每次调用createObjectURL()方法时,都会创建一个新的URL对象,即使你已经用相同的对象作为参数创建过。当不再需要这些URL对象时,每个对象必须通过调用URL.revokeObjectURL()方法来释放 setTimeout(() => { window.URL.revokeObjectURL(objecturl); //释放createObjectURL创建得对象 }, 2000) }, methods: { //base64转成blob对象第一种方式 dataURLtoBlob(dataurl) { var arr = dataurl.split(','), mime = arr[0].match(/:(.*?);/)[1], bstr = atob(arr[1]), n = bstr.length, u8arr = new Uint8Array(n);//8位无符号整数,长度1个字节 console.log(mime) while (n--) { u8arr[n] = bstr.charCodeAt(n); } // console.log(JSON.stringify(u8arr)); return new Blob([u8arr], { type: mime }); }, } }) }); </script> </body> </html>

uniapp web-view 加载本地HTML链接时候,页面setNavigationBarTitle会被HTML的title替代
HTML页面中的title标签内容这么写: <title>'</title>
这样可以隐藏HTML中的title,setNavigationBarTitle也能正常使用
HTML页面中的title标签内容这么写: <title>'</title>
这样可以隐藏HTML中的title,setNavigationBarTitle也能正常使用

记录下自定义ios基座
为了测试推送,试下自定义基座 - iOS下遇到的坑 ;
官方文档
遇到的几个问题
1.product ->archive 为灰色 ;将选择设备(iphone11)的处 切换成 generic iOS device;


- 证书报错

HBuilder is automatically signed for development, but a conflicting code signing identity iPhone Distribution has been manually specified. Set the code signing identity value to "iPhone Developer" in the build settings editor, or switch to manual signing in the Signing & Capabilities editor.添加账号下证书,未添加的需要新增accout 苹果开发账号下的

debug 改好后,release 下也会报错,按下图修改

暂时这么多,再碰到问题以此添加,做个记录
为了测试推送,试下自定义基座 - iOS下遇到的坑 ;
官方文档
遇到的几个问题
1.product ->archive 为灰色 ;将选择设备(iphone11)的处 切换成 generic iOS device;
- 证书报错
HBuilder is automatically signed for development, but a conflicting code signing identity iPhone Distribution has been manually specified. Set the code signing identity value to "iPhone Developer" in the build settings editor, or switch to manual signing in the Signing & Capabilities editor.添加账号下证书,未添加的需要新增accout 苹果开发账号下的
debug 改好后,release 下也会报错,按下图修改
暂时这么多,再碰到问题以此添加,做个记录
收起阅读 »
修改胶囊按钮样式
作为一个强迫症患者,小程序sdk不能修改胶囊按钮样式,不能忍!
查看源码发现,按钮样式是这样设置的
uniMPSDK-release.aar ->io.dcloud.WebviewActivity ->onCreate
Typeface var3 = Typeface.createFromAsset(this.getAssets(), "fonts/dcloud_iconfont.ttf");
this.a.setText("\ue601");
this.a.setTypeface(var3);
this.a.getPaint().setTextSize((float)var2);
this.b.setText("\ue650");
this.b.setTypeface(var3);
this.b.getPaint().setTextSize((float)var2);
this.b.setVisibility(4);
this.e.setText("\ue606");
this.e.setTypeface(var3);
this.e.getPaint().setTextSize((float)var2);
this.d.setText("\ue606");
this.d.setTypeface(var3);最终通过加载 assets -> fonts/dcloud_iconfont.ttf 字体文件来设置
so!!!
利用android的资源overlay机制,将dcloud_iconfont.ttf文件进行修改,放入自己工程的assets/fonts中来覆盖默认样式
作为一个强迫症患者,小程序sdk不能修改胶囊按钮样式,不能忍!
查看源码发现,按钮样式是这样设置的
uniMPSDK-release.aar ->io.dcloud.WebviewActivity ->onCreate
Typeface var3 = Typeface.createFromAsset(this.getAssets(), "fonts/dcloud_iconfont.ttf");
this.a.setText("\ue601");
this.a.setTypeface(var3);
this.a.getPaint().setTextSize((float)var2);
this.b.setText("\ue650");
this.b.setTypeface(var3);
this.b.getPaint().setTextSize((float)var2);
this.b.setVisibility(4);
this.e.setText("\ue606");
this.e.setTypeface(var3);
this.e.getPaint().setTextSize((float)var2);
this.d.setText("\ue606");
this.d.setTypeface(var3);最终通过加载 assets -> fonts/dcloud_iconfont.ttf 字体文件来设置
so!!!
利用android的资源overlay机制,将dcloud_iconfont.ttf文件进行修改,放入自己工程的assets/fonts中来覆盖默认样式
【HbuilerX-Bug】终端无法显示打印信息,也无法输入
修改 powershell.exe的路径为绝对路径:
C:/Windows/System32/WindowsPowerShell/v1.0/powershell.exe

修改 powershell.exe的路径为绝对路径:
C:/Windows/System32/WindowsPowerShell/v1.0/powershell.exe

分享苹果内购requestPayment没有任何返回
是不是在沙盒模式下支付一次成功后,requestPayment没有任何返回,这种情况,可以卸载APP重新编译安装测试,应该就可以了
接苹果内购经验,这里说的不好,不好喷
按官网苹果内购支付按钮里,然后就是后端要做订单核验,如果不核验,就不会返回的,所以接内购的时候,需要后端配合核验订单,如果自己调试,那就支付一次之后就卸载重新编译安装应该会再次回调requestPayment的几个函数了。
流程:
1、将金额资料发送到服务端,生成一个订单号
2、收到订单号后执行uni.requestPayment这个方法
3、在success回调中再次请问后端核验订单,这个时候可以将transactionReceipt和订单号传过去,进行订单修改状态操作
是不是在沙盒模式下支付一次成功后,requestPayment没有任何返回,这种情况,可以卸载APP重新编译安装测试,应该就可以了
接苹果内购经验,这里说的不好,不好喷
按官网苹果内购支付按钮里,然后就是后端要做订单核验,如果不核验,就不会返回的,所以接内购的时候,需要后端配合核验订单,如果自己调试,那就支付一次之后就卸载重新编译安装应该会再次回调requestPayment的几个函数了。
流程:
1、将金额资料发送到服务端,生成一个订单号
2、收到订单号后执行uni.requestPayment这个方法
3、在success回调中再次请问后端核验订单,这个时候可以将transactionReceipt和订单号传过去,进行订单修改状态操作
收起阅读 »Hbuildx打包失败
信息:* What went wrong:
Execution failed for task ':app:transformClassesWithMultidexlistForRelease'.
> com.android.build.api.transform.TransformException: Error while generating the main dex list.
- Try:
Run with --debug option to get more log output. Run with --scan to get full insights.
解决方案:如图
信息:* What went wrong:
Execution failed for task ':app:transformClassesWithMultidexlistForRelease'.
> com.android.build.api.transform.TransformException: Error while generating the main dex list.
- Try:
Run with --debug option to get more log output. Run with --scan to get full insights.
解决方案:如图
收起阅读 »iOS 提交App Store 审核被拒2.3.10和解决记录
在苹果的上架平台上,版本信息出现安卓相关,修改上架版本信息(删除安卓俩字),重新提交审核即可
在苹果的上架平台上,版本信息出现安卓相关,修改上架版本信息(删除安卓俩字),重新提交审核即可

[分享]网易新闻WebApp模板源码下载及交互体验
BUI-163
大小: 6.27M
网易新闻
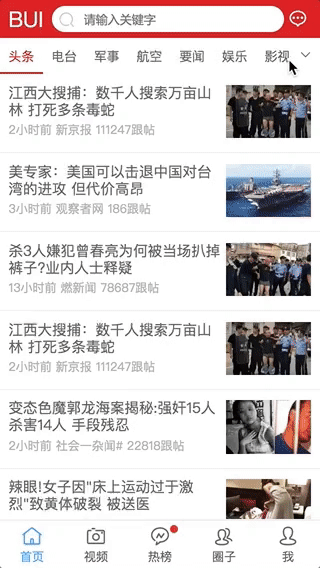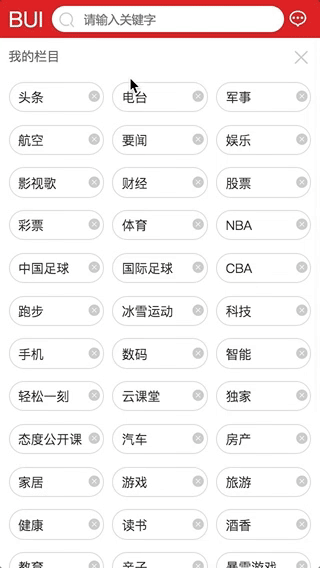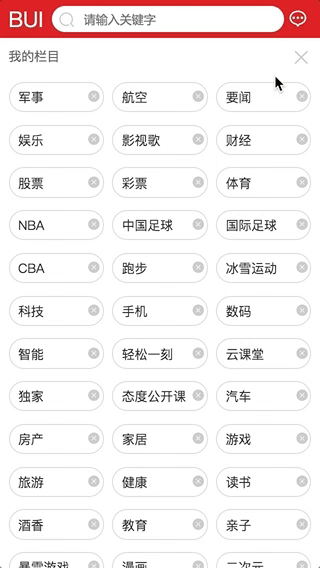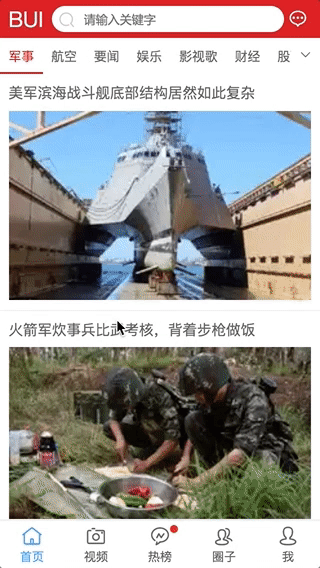
该App基于BUI Webapp框架+Dcloud构建. 仅供学习交流使用.
-
交互1: 下拉刷新, 加载分页

-
交互2: Tab嵌套交互

-
交互3: 栏目删减自动更新
-
交互4: 底部tab的交互, 每个Tab里面还有各自的交互




源码下载: https://github.com/imouou/BUI-163
App体验下载: http://d.firim.top/zcdj
BUI-163
大小: 6.27M
网易新闻
该App基于BUI Webapp框架+Dcloud构建. 仅供学习交流使用.
-
交互1: 下拉刷新, 加载分页
-
交互2: Tab嵌套交互
-
交互3: 栏目删减自动更新
-
交互4: 底部tab的交互, 每个Tab里面还有各自的交互
源码下载: https://github.com/imouou/BUI-163
App体验下载: http://d.firim.top/zcdj
收起阅读 »如何将经过处理的照片保存到本地呢?
照片处理之后,怎样保存到相册里,void plus.gallery.save( path, successCB, errorCB ); api只有这一句,这个path是保存路径,那么保存源是什么?
照片处理之后,怎样保存到相册里,void plus.gallery.save( path, successCB, errorCB ); api只有这一句,这个path是保存路径,那么保存源是什么?
