






HTML中JS对于字符串的切割截取实现
在网站编程制作中,对于字符串的切割截取平时所用可能不是特别多,而且分的比较细,所以自备自查。有备无患。由于之前所有均在一个demo测试,下面就来跟大家分享一下成果。
1.函数:split()
功能:使用一个指定的分隔符把一个字符串分割存储到数组
例子: str=”jpg|bmp|gif|ico|png”; arr=str.split(”|”);
//arr是一个包含字符值”jpg”、”bmp”、”gif”、”ico”和”png”的数组
2.函数:join()
功能:使用您选择的分隔符将一个数组合并为一个字符串
例子: var delimitedString=myArray.join(delimiter);
var myList=new Array(”jpg”,”bmp”,”gif”,”ico”,”png”);
var portableList=myList.join(”|”);
//结果是jpg|bmp|gif|ico|png
3.函数:concat()
功能:将两个数组连接在一起;
例子:arr1=[1,2,3,4]
arr2=[5,6,7,8]
alert(arr1.concat(arr2)) //结果为[1,2,3,4,5,6,7,8]
4.函数:charAt()
功能:返回指定位置的字符。字符串中第一个字符的下标是 0。如果参数 index 不在 0 与 string.length 之间,该方法将返回一个空字符串。
例子:var str='a,g,i,d,o,v,w,d,k,p'
alert(str.charAt(2)) //结果为g
5:函数:charCodeAt()
功能:charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数。
方法 charCodeAt() 与 charAt() 方法执行的操作相似,只不过前者返回的是位于指定位置的字符的编码,而后者返回的是字符子串。
例子:var str='a,g,i,d,o,v,w,d,k,p'
alert(str.charCodeAt(2)) //结果为103。即g的Unicode编码为103
6.函数:slice()
功能:arrayObject.slice(start,end)
start:必需。规定从何处开始选取。如果是负数,那么它规定从数组尾部开始算起的位置。也就是说,-1 指最后一个元素,-2 指倒数第二个元素,以此类推。
end:可选。规定从何处结束选取。该参数是数组片断结束处的数组下标。如果没有指定该参数,那么切分的数组包含从 start 到数组结束的所有元素。如果这个参数是负数,那么它规定的是从数组尾部开始算起的元素。
返回一个新的数组,包含从start到end(不包括该元素)的arrayobject中的元素。
例子:var str='ahji3o3s4e6p8a0sdewqdasj'
alert(str.slice(2,5)) //结果ji3
7.函数:substring()
定义和用法 substring 方法用于提取字符串中介于两个指定下标之间的字符。
语法 stringObject.substring(start,stop)
start 必需。一个非负的整数,规定要提取的子串的第一个字符在 stringObject 中的位置。
stop 可选。一个非负的整数,比要提取的子串的最后一个字符在 stringObject 中的位置多 1。
如果省略该参数,那么返回的子串会一直到字符串的结尾。
返回 一个新的字符串,该字符串值包含 stringObject 的一个子字符串,其内容是从 start 处到 stop-1 处的所有字符,其长度为 stop 减 start。 说明 substring 方法返回的子串包括 start 处的字符,但不包括 end 处的字符。 如果 start 与 end 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。 如果 start 比 end 大,那么该方法在提取子串之前会先交换这两个参数。 如果 start 或 end 为负数,那么它将被替换为 0。
例子:var str='ahji3o3s4e6p8a0sdewqdasj'
alert(str.substring(2,6)) //结果为ji3o3
8.函数:substr
定义和用法 substr 方法用于返回一个从指定位置开始的指定长度的子字符串。
语法 stringObject.substr(start [, length ])
参数 start 必需。所需的子字符串的起始位置。字符串中的第一个字符的索引为 0。
length 可选。在返回的子字符串中应包括的字符个数。 说明 如果 length 为 0 或负数,将返回一个空字符串。 如果没有指定该参数,则子字符串将延续到stringObject的最后。
举例: var str = "0123456789";
alert(str.substring(0));------------"0123456789"
alert(str.substring(5));------------"56789"
alert(str.substring(10));-----------""
alert(str.substring(12));-----------""
alert(str.substring(-5));-----------"0123456789"
alert(str.substring(-10));----------"0123456789"
alert(str.substring(-12));----------"0123456789"
alert(str.substring(0,5));----------"01234"
alert(str.substring(0,10));---------"0123456789"
alert(str.substring(0,12));---------"0123456789"
alert(str.substring(2,0));----------"01"
alert(str.substring(2,2));----------""
alert(str.substring(2,5));----------"234"
alert(str.substring(2,12));---------"23456789"
alert(str.substring(2,-2));---------"01"
alert(str.substring(-1,5));---------"01234"
alert(str.substring(-1,-5));--------""
好了,到这里就跟大家分享完成了,如果大家还是不知道是怎么实现的,或者还存在有不理解的地方,都是可以留言咨询。
本文由专业的郑州app开发公司燚轩科技整理发布,原创不易,如需转载请注明出处!
在网站编程制作中,对于字符串的切割截取平时所用可能不是特别多,而且分的比较细,所以自备自查。有备无患。由于之前所有均在一个demo测试,下面就来跟大家分享一下成果。
1.函数:split()
功能:使用一个指定的分隔符把一个字符串分割存储到数组
例子: str=”jpg|bmp|gif|ico|png”; arr=str.split(”|”);
//arr是一个包含字符值”jpg”、”bmp”、”gif”、”ico”和”png”的数组
2.函数:join()
功能:使用您选择的分隔符将一个数组合并为一个字符串
例子: var delimitedString=myArray.join(delimiter);
var myList=new Array(”jpg”,”bmp”,”gif”,”ico”,”png”);
var portableList=myList.join(”|”);
//结果是jpg|bmp|gif|ico|png
3.函数:concat()
功能:将两个数组连接在一起;
例子:arr1=[1,2,3,4]
arr2=[5,6,7,8]
alert(arr1.concat(arr2)) //结果为[1,2,3,4,5,6,7,8]
4.函数:charAt()
功能:返回指定位置的字符。字符串中第一个字符的下标是 0。如果参数 index 不在 0 与 string.length 之间,该方法将返回一个空字符串。
例子:var str='a,g,i,d,o,v,w,d,k,p'
alert(str.charAt(2)) //结果为g
5:函数:charCodeAt()
功能:charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数。
方法 charCodeAt() 与 charAt() 方法执行的操作相似,只不过前者返回的是位于指定位置的字符的编码,而后者返回的是字符子串。
例子:var str='a,g,i,d,o,v,w,d,k,p'
alert(str.charCodeAt(2)) //结果为103。即g的Unicode编码为103
6.函数:slice()
功能:arrayObject.slice(start,end)
start:必需。规定从何处开始选取。如果是负数,那么它规定从数组尾部开始算起的位置。也就是说,-1 指最后一个元素,-2 指倒数第二个元素,以此类推。
end:可选。规定从何处结束选取。该参数是数组片断结束处的数组下标。如果没有指定该参数,那么切分的数组包含从 start 到数组结束的所有元素。如果这个参数是负数,那么它规定的是从数组尾部开始算起的元素。
返回一个新的数组,包含从start到end(不包括该元素)的arrayobject中的元素。
例子:var str='ahji3o3s4e6p8a0sdewqdasj'
alert(str.slice(2,5)) //结果ji3
7.函数:substring()
定义和用法 substring 方法用于提取字符串中介于两个指定下标之间的字符。
语法 stringObject.substring(start,stop)
start 必需。一个非负的整数,规定要提取的子串的第一个字符在 stringObject 中的位置。
stop 可选。一个非负的整数,比要提取的子串的最后一个字符在 stringObject 中的位置多 1。
如果省略该参数,那么返回的子串会一直到字符串的结尾。
返回 一个新的字符串,该字符串值包含 stringObject 的一个子字符串,其内容是从 start 处到 stop-1 处的所有字符,其长度为 stop 减 start。 说明 substring 方法返回的子串包括 start 处的字符,但不包括 end 处的字符。 如果 start 与 end 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。 如果 start 比 end 大,那么该方法在提取子串之前会先交换这两个参数。 如果 start 或 end 为负数,那么它将被替换为 0。
例子:var str='ahji3o3s4e6p8a0sdewqdasj'
alert(str.substring(2,6)) //结果为ji3o3
8.函数:substr
定义和用法 substr 方法用于返回一个从指定位置开始的指定长度的子字符串。
语法 stringObject.substr(start [, length ])
参数 start 必需。所需的子字符串的起始位置。字符串中的第一个字符的索引为 0。
length 可选。在返回的子字符串中应包括的字符个数。 说明 如果 length 为 0 或负数,将返回一个空字符串。 如果没有指定该参数,则子字符串将延续到stringObject的最后。
举例: var str = "0123456789";
alert(str.substring(0));------------"0123456789"
alert(str.substring(5));------------"56789"
alert(str.substring(10));-----------""
alert(str.substring(12));-----------""
alert(str.substring(-5));-----------"0123456789"
alert(str.substring(-10));----------"0123456789"
alert(str.substring(-12));----------"0123456789"
alert(str.substring(0,5));----------"01234"
alert(str.substring(0,10));---------"0123456789"
alert(str.substring(0,12));---------"0123456789"
alert(str.substring(2,0));----------"01"
alert(str.substring(2,2));----------""
alert(str.substring(2,5));----------"234"
alert(str.substring(2,12));---------"23456789"
alert(str.substring(2,-2));---------"01"
alert(str.substring(-1,5));---------"01234"
alert(str.substring(-1,-5));--------""
好了,到这里就跟大家分享完成了,如果大家还是不知道是怎么实现的,或者还存在有不理解的地方,都是可以留言咨询。
本文由专业的郑州app开发公司燚轩科技整理发布,原创不易,如需转载请注明出处!
收起阅读 »uni-app自定义返回逻辑教程
自 HBuilderX v1.1.0 起,uni-app 的页面新增 onBackPress(event) 生命周期函数。
onBackPress(event) 返回 event ={from: backbutton | navigateBack}
说明
当用户进行以下操作时,会触发该函数:
- Android 实体返回键 (
from = backbutton) - 顶部导航栏左边的返回按钮 (
from = backbutton) - 返回 API,即
uni.navigateBack()(from = navigateBack)
注意事项:
- 只有在该函数中返回值为 true 时,才表示不执行默认的返回,自行处理此时的业务逻辑。
- 当不阻止页面返回却直接调用页面路由相关接口(如:uni.switchTab)时,可能会导致页面显示异常,可以通过延迟调用路由相关接口解决。
- 不返回或返回其它值,均会执行默认的返回行为。
- H5 平台,顶部导航栏返回按钮支持
onBackPress(),浏览器默认返回按键及Android手机实体返回键不支持onBackPress() - 暂不支持直接在自定义组件中配置该函数,目前只能是在页面中来处理。
场景示例
页面返回
场景说明:
页面中的遮罩处于显示状态时,点击返回不希望直接关闭页面,而是隐藏掉遮罩。遮罩隐藏后,继续点击返回再执行默认的逻辑。
自定义遮罩
通常自定义的遮罩/弹出层,都会做成组件,这样方便复用。
新建 uni-app 项目->components->mask.vue 文件,代码如下:
<template>
<view>
<view class="cpt-mask">
</view>
</view>
</template>
<script>
export default {}
</script>
<style>
.cpt-mask {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-color: #000000;
opacity: 0.5;
z-index: 99;
}
</style>引用遮罩组件
在页面中引入 mask 自定义组件后,通过一个状态值来控制其隐藏/显示。
<mask v-if="showMask"></mask>这里用 v-if,不要用 v-show,自定义组件存在一些问题待优化。
处理返回逻辑
在 onBackPress 中,判定当前遮罩是否处于显示状态。如果显示,则关闭遮罩并返回 true。
onBackPress() {
if(this.showMask) {
this.showMask = false;
return true;
}
},多级返回
部分业务场景下,返回的逻辑中需要返回多级页面。
由于 uni.navigateBack() 同样会触发 onBackPress 函数。因此在 onBackPress 中直接调用 uni.navigateBack() 并始终返回 true 会引发死循环。
此时,需要根据 onBackPress 的回调对象中的 from 值来做处理,当来源是 'navigateBack' 时,返回 false。
<template>
<view>
</view>
</template>
<script>
export default {
data() {
return {};
},
onBackPress(options) {
if (options.from === 'navigateBack') {
return false;
}
this.back();
return true;
},
methods: {
back() {
uni.navigateBack({
delta: 2
});
}
},
}
</script>
<style>
</style>应用退出
场景说明:
若在App首页,点击手机物理返回键,此时无返回页面可关闭,uni-app默认会提示“再按一次退出应用”;若想自定义退出信息,如修改为:出现一个拟态窗口提示我们是否退出应用,点击确定退出应用。点击取消,不做操作。
实现方案:
在 onBackPress 中,遮罩不显示的状态下,点击返回键将弹出拟态窗。
onBackPress() {
if(this.showMask) {
this.showMask = false;
return true;
}else{
uni.showModal({
title: '提示',
content: '是否退出uni-app?',
success: function(res) {
if (res.confirm) {
// 退出当前应用,改方法只在App中生效
plus.runtime.quit();
} else if (res.cancel) {
console.log('用户点击取消');
}
}
});
return true
}
},实现效果如下图:
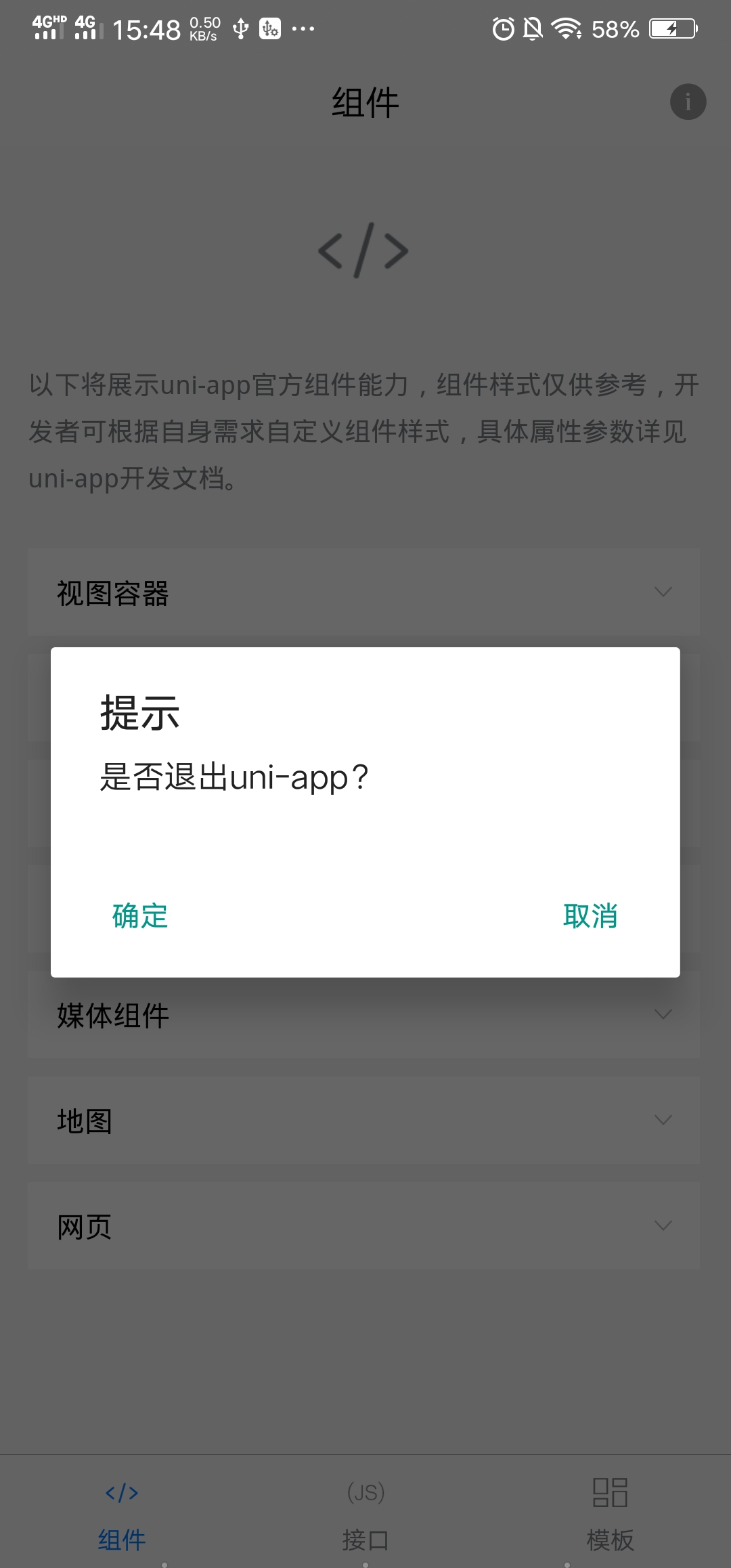
运行体验
完整的示例代码,见附件。解压后,拖至 HBuilderX 运行即可。
自 HBuilderX v1.1.0 起,uni-app 的页面新增 onBackPress(event) 生命周期函数。
onBackPress(event) 返回 event ={from: backbutton | navigateBack}
说明
当用户进行以下操作时,会触发该函数:
- Android 实体返回键 (
from = backbutton) - 顶部导航栏左边的返回按钮 (
from = backbutton) - 返回 API,即
uni.navigateBack()(from = navigateBack)
注意事项:
- 只有在该函数中返回值为 true 时,才表示不执行默认的返回,自行处理此时的业务逻辑。
- 当不阻止页面返回却直接调用页面路由相关接口(如:uni.switchTab)时,可能会导致页面显示异常,可以通过延迟调用路由相关接口解决。
- 不返回或返回其它值,均会执行默认的返回行为。
- H5 平台,顶部导航栏返回按钮支持
onBackPress(),浏览器默认返回按键及Android手机实体返回键不支持onBackPress() - 暂不支持直接在自定义组件中配置该函数,目前只能是在页面中来处理。
场景示例
页面返回
场景说明:
页面中的遮罩处于显示状态时,点击返回不希望直接关闭页面,而是隐藏掉遮罩。遮罩隐藏后,继续点击返回再执行默认的逻辑。
自定义遮罩
通常自定义的遮罩/弹出层,都会做成组件,这样方便复用。
新建 uni-app 项目->components->mask.vue 文件,代码如下:
<template>
<view>
<view class="cpt-mask">
</view>
</view>
</template>
<script>
export default {}
</script>
<style>
.cpt-mask {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-color: #000000;
opacity: 0.5;
z-index: 99;
}
</style>引用遮罩组件
在页面中引入 mask 自定义组件后,通过一个状态值来控制其隐藏/显示。
<mask v-if="showMask"></mask>这里用 v-if,不要用 v-show,自定义组件存在一些问题待优化。
处理返回逻辑
在 onBackPress 中,判定当前遮罩是否处于显示状态。如果显示,则关闭遮罩并返回 true。
onBackPress() {
if(this.showMask) {
this.showMask = false;
return true;
}
},多级返回
部分业务场景下,返回的逻辑中需要返回多级页面。
由于 uni.navigateBack() 同样会触发 onBackPress 函数。因此在 onBackPress 中直接调用 uni.navigateBack() 并始终返回 true 会引发死循环。
此时,需要根据 onBackPress 的回调对象中的 from 值来做处理,当来源是 'navigateBack' 时,返回 false。
<template>
<view>
</view>
</template>
<script>
export default {
data() {
return {};
},
onBackPress(options) {
if (options.from === 'navigateBack') {
return false;
}
this.back();
return true;
},
methods: {
back() {
uni.navigateBack({
delta: 2
});
}
},
}
</script>
<style>
</style>应用退出
场景说明:
若在App首页,点击手机物理返回键,此时无返回页面可关闭,uni-app默认会提示“再按一次退出应用”;若想自定义退出信息,如修改为:出现一个拟态窗口提示我们是否退出应用,点击确定退出应用。点击取消,不做操作。
实现方案:
在 onBackPress 中,遮罩不显示的状态下,点击返回键将弹出拟态窗。
onBackPress() {
if(this.showMask) {
this.showMask = false;
return true;
}else{
uni.showModal({
title: '提示',
content: '是否退出uni-app?',
success: function(res) {
if (res.confirm) {
// 退出当前应用,改方法只在App中生效
plus.runtime.quit();
} else if (res.cancel) {
console.log('用户点击取消');
}
}
});
return true
}
},实现效果如下图:
运行体验
完整的示例代码,见附件。解压后,拖至 HBuilderX 运行即可。
收起阅读 »
HBuilderX 在server 2008 64x中使用中,突然闪退 代码消失找不回
HBuilderX 在server 2008 64x中使用中,突然闪退 代码消失找不回
当前编辑代码消盟,直接找不回,大家小心使用本软件!
HBuilderX 在server 2008 64x中使用中,突然闪退 代码消失找不回
当前编辑代码消盟,直接找不回,大家小心使用本软件!

vue h5+app蓝牙打印小票
参考网址:
链接蓝牙:https://blog.csdn.net/cxgasd/article/details/78208708
蓝牙打印机指令:https://www.jianshu.com/p/c0b6d1a4823b
1,打印出来的文本是字节流,平常的换行,样式都用不了
2,一行字母有32个字符,一行全部 中文有16个字符 ,1中文=2字母 ,js判断字符串个数
strLen: function(val) {
var len = 0;
for (var i = 0; i < val.length; i++) {
var a = val.charAt(i);
if (a.match(/[^\x00-\xff]/ig) != null) {
len += 1;
} else {
len += 0.5;
}
}
return len;
}实现字符串 拼接的方法: 左右对齐是中间填空格,隔行是一行32个空格
-
蓝牙打印机指令 可以实现 文字放大,图案
btOutStream.write(0x1B);
btOutStream.write(0x40);
//或者
// btOutStream.write([0x1B,0x40]);
//打印小票
printComponent:{
//字符个数
strLen:function(val) {
var len = 0;
for (var i = 0; i < val.length; i++) {
var a= val.charAt(i);
if (a.match(/[^\x00-\xff]/ig) != null) {
len += 1;
}else {
len += 0.5;
}
}
return len;
},
//空格
spacing:function(str){
var blank="";
var row=Math.ceil(this.strLen(str)/16); //行数
var len=(16*row-this.strLen(str))*2;
for(var i=0;i<len;i++){
blank+=' ';
}
console.log((str+blank).length);
return str+blank;
},
//左右对齐
justify:function(str1,str2){
var blank="";
var len=(16-this.strLen(str1)-this.strLen(str2))*2;
for(var i=0;i<len;i++){
blank+=' ';
}
return str1+blank+str2;
},
//分割线
newline:function(){
var line="--------------------------------";
return line;
},
//打印(拣货单)
print3:function(_this){
var str='';
//str+=' —YOULENONG— ';
str+=this.spacing(' ');
str+=this.spacing('订单号:'+_this.order_no);
for(var i=0;i<_this.goodsArr.length;i++){
var v=_this.goodsArr[i];
str+=this.spacing(v.goods_name);
str+=this.justify('销价:'+v.goods_price+'/'+v.unit,'购买量:'+v.goods_num);
str+=this.spacing('货号:'+v.product_no);
//str+=this.justify('折扣:-xxx','折后:xxx');
str+=this.newline();
}
str+=this.spacing(new Date().Format('MM-dd hh:mm:ss'));
str+=this.spacing(' ');
str+=this.spacing(' ');
str+=this.spacing(' ');
_this.bluetoothTool.sendData(str); //把字符串 发给蓝牙,打印
} }
附件有代码,我删减了,不保证运行成功,得看懂vue
参考网址:
链接蓝牙:https://blog.csdn.net/cxgasd/article/details/78208708
蓝牙打印机指令:https://www.jianshu.com/p/c0b6d1a4823b
1,打印出来的文本是字节流,平常的换行,样式都用不了
2,一行字母有32个字符,一行全部 中文有16个字符 ,1中文=2字母 ,js判断字符串个数
strLen: function(val) {
var len = 0;
for (var i = 0; i < val.length; i++) {
var a = val.charAt(i);
if (a.match(/[^\x00-\xff]/ig) != null) {
len += 1;
} else {
len += 0.5;
}
}
return len;
}实现字符串 拼接的方法: 左右对齐是中间填空格,隔行是一行32个空格
-
蓝牙打印机指令 可以实现 文字放大,图案
btOutStream.write(0x1B);
btOutStream.write(0x40);
//或者
// btOutStream.write([0x1B,0x40]);
//打印小票
printComponent:{
//字符个数
strLen:function(val) {
var len = 0;
for (var i = 0; i < val.length; i++) {
var a= val.charAt(i);
if (a.match(/[^\x00-\xff]/ig) != null) {
len += 1;
}else {
len += 0.5;
}
}
return len;
},
//空格
spacing:function(str){
var blank="";
var row=Math.ceil(this.strLen(str)/16); //行数
var len=(16*row-this.strLen(str))*2;
for(var i=0;i<len;i++){
blank+=' ';
}
console.log((str+blank).length);
return str+blank;
},
//左右对齐
justify:function(str1,str2){
var blank="";
var len=(16-this.strLen(str1)-this.strLen(str2))*2;
for(var i=0;i<len;i++){
blank+=' ';
}
return str1+blank+str2;
},
//分割线
newline:function(){
var line="--------------------------------";
return line;
},
//打印(拣货单)
print3:function(_this){
var str='';
//str+=' —YOULENONG— ';
str+=this.spacing(' ');
str+=this.spacing('订单号:'+_this.order_no);
for(var i=0;i<_this.goodsArr.length;i++){
var v=_this.goodsArr[i];
str+=this.spacing(v.goods_name);
str+=this.justify('销价:'+v.goods_price+'/'+v.unit,'购买量:'+v.goods_num);
str+=this.spacing('货号:'+v.product_no);
//str+=this.justify('折扣:-xxx','折后:xxx');
str+=this.newline();
}
str+=this.spacing(new Date().Format('MM-dd hh:mm:ss'));
str+=this.spacing(' ');
str+=this.spacing(' ');
str+=this.spacing(' ');
_this.bluetoothTool.sendData(str); //把字符串 发给蓝牙,打印
} }
附件有代码,我删减了,不保证运行成功,得看懂vue
收起阅读 »
HTML编程之滚轮滑动监听效果的实现
在前端页面制作过程中,我们经常会发现有时候某些动作需要滚动滑轮来实现,那么对于初学者来说可能不明白是如何实现的,对于这个问题,下面就来跟大家分析一下,如何用滚轮滑动监听效果的实现。
源代码如下:
windowAddMouseWheel();
function windowAddMouseWheel() {
var scrollFunc = function (e) {
e = e || window.event;
if (e.wheelDelta) { //判断浏览器IE,谷歌滑轮事件
if (e.wheelDelta > 0) { //当滑轮向上滚动时
alert("滑轮向上滚动");
}
if (e.wheelDelta < 0) { //当滑轮向下滚动时
alert("滑轮向下滚动");
}
} else if (e.detail) { //Firefox滑轮事件
if (e.detail> 0) { //当滑轮向上滚动时
alert("滑轮向上滚动");
}
if (e.detail< 0) { //当滑轮向下滚动时
alert("滑轮向下滚动");
}
}
};
//给页面绑定滑轮滚动事件
if (document.addEventListener) {
document.addEventListener('DOMMouseScroll', scrollFunc, false);
}
//滚动滑轮触发scrollFunc方法
window.onmousewheel = document.onmousewheel = scrollFunc;
}
现在大家知道是如何控制实现的吧,如果还是有不明白的地方,或者不知道哪里出错了,都是可以留言咨询我们来寻求帮助和解答的。
本文由专业的郑州app开发公司燚轩科技整理发布,原创不易,如需转载请注明出处。
在前端页面制作过程中,我们经常会发现有时候某些动作需要滚动滑轮来实现,那么对于初学者来说可能不明白是如何实现的,对于这个问题,下面就来跟大家分析一下,如何用滚轮滑动监听效果的实现。
源代码如下:
windowAddMouseWheel();
function windowAddMouseWheel() {
var scrollFunc = function (e) {
e = e || window.event;
if (e.wheelDelta) { //判断浏览器IE,谷歌滑轮事件
if (e.wheelDelta > 0) { //当滑轮向上滚动时
alert("滑轮向上滚动");
}
if (e.wheelDelta < 0) { //当滑轮向下滚动时
alert("滑轮向下滚动");
}
} else if (e.detail) { //Firefox滑轮事件
if (e.detail> 0) { //当滑轮向上滚动时
alert("滑轮向上滚动");
}
if (e.detail< 0) { //当滑轮向下滚动时
alert("滑轮向下滚动");
}
}
};
//给页面绑定滑轮滚动事件
if (document.addEventListener) {
document.addEventListener('DOMMouseScroll', scrollFunc, false);
}
//滚动滑轮触发scrollFunc方法
window.onmousewheel = document.onmousewheel = scrollFunc;
}
现在大家知道是如何控制实现的吧,如果还是有不明白的地方,或者不知道哪里出错了,都是可以留言咨询我们来寻求帮助和解答的。
本文由专业的郑州app开发公司燚轩科技整理发布,原创不易,如需转载请注明出处。

hbuilder开发H5应用时,清除了ios的角标。但再次收到个推推送时角标还是原数字+1。
直接从应用setBadgeNumber(0),只是清除了应用本地的角标。但是个推对于当前clientid还有一个记录。再次推送的时候,会自己+1并把数字推过来。
所以,清除了本地的数字,还要通知个推也清除。
try{
plus.runtime.setBadgeNumber(0);
if(mui.os.ios){
var GeTuiSdk = plus.ios.importClass('GeTuiSdk');
GeTuiSdk.setBadge(0); }
console.log("清除角标")
}catch(e){
console.log("清除角标异常")
}
直接从应用setBadgeNumber(0),只是清除了应用本地的角标。但是个推对于当前clientid还有一个记录。再次推送的时候,会自己+1并把数字推过来。
所以,清除了本地的数字,还要通知个推也清除。
try{
plus.runtime.setBadgeNumber(0);
if(mui.os.ios){
var GeTuiSdk = plus.ios.importClass('GeTuiSdk');
GeTuiSdk.setBadge(0); }
console.log("清除角标")
}catch(e){
console.log("清除角标异常")
}
收起阅读 »HBuilderX如何保护程序员的身心健康
> 本帖已集成到: hx产品文档
键盘、椅子有人体工学,一个开发工具软件,有什么健不健康的概念呢?
当然有的。你的眼睛、手的健康,都与开发工具有很大关系。
DCloud是一家有匠心、有情怀的团队,在工具对人体的健康影响方面投入了大量精力财力研究。
护眼:绿柔环保主题
很多人误以为黑色主题最护眼,我们自己也曾长时间使用黑色主题,但感受不对劲,于是较真的研究了到底什么是健康护眼的主题。
其实参考电子书领域就知道,长时间盯着电脑屏幕或手机屏,背景绝不能是黑色,而应该是泛黄的颜色。如果一家做电子书的公司使用黑色背景的话,这公司肯定会被读者抛弃掉。
但是电子书行业为什么普遍采用泛黄色呢?是为了给读者制造看纸书的错觉?还是真有科学道理。我们需要仔细研究。
有一个误传的说法是:黑色背景,在液晶下发光量少,从而更护眼。
由于纯黑色背景很难看,实际上各个开发工具的背景色不是纯黑色,液晶面板上的粒子仍然在发光。
虽然液晶面板的暗色区光线量低,但就人眼肌肉的紧张度而言,高对比度的伤害大于光线量的伤害。
在阳光明媚的草原上,虽然光线量非常大,但人眼很舒适。
但在黑色屋子里,手机屏幕亮度调到最低,光线量远低于前者,但仍然刺眼。
这是对比度的影响造成的。
HBuilder的默认主题是绿柔,其特点是柔和、低对比度、强光下仍清晰、绿色感加强。对着这样的界面写一天代码,感受要比对着太亮或太暗的界面舒服很多。
绿柔是一个严谨的设计过程,包含色彩心理学和色彩生理学的很多知识,并且在北京国奥心理医院做过严谨的医学测试。
我们安排工程师在不同的配色主题下写代码,在医院检测他们的脑疲劳程度,最终调校出了绿柔配色方案,实验过程如下:
> 参与实验的2位程序员在充分休息后,分别使用绿柔和黑色主题的编程工具进行编码半小时,并监测脑电波的数据变化。
> 通过对实验者的脑电波产生的17万条数据的分析,利用医院仪器打印出的疲劳值、紧张度和注意力集中程度数值,发现实验结论如下:
> 半小时编码后2位测试者的疲劳度均上升,但,绿柔主题下工作的程序员疲劳值上升相对缓慢,紧张程度更低,注意力更集中。
> 使用黑色主题编码后疲劳值的上升幅度最高达到使用绿柔上升幅度的700%!
> 此实验进行多次,并有交叉测试,结论始终相同。

上图为在医院参与实验的程序员。
色彩方面有色彩生理学和色彩心理学。我们先从色彩生理学角度看看黑色主题的问题:
- 转场晕眩
当一个人眼睛长期看暗色系事物时,大脑会分泌激素强迫眼睛增强视力。
比如我们在一个黑屋子待一会就能看清东西,但回到阳光下时又会晕眩,这叫做暗适应。
同样,长期看黑色的代码区,此时切换到其他软件界面或看窗外就会晕眩。 - 夜盲症
长期的黑暗环境下眼球会分泌视紫红质,视紫红质消耗维生素A,并且会引发夜盲症,虽不是近视,但夜晚视力低于常人。
具体见百度百科视紫红质 - 对比度高
黑色背景往往对应高对比度的前景内容,而高对比度不适合长期观看。
其实就像糖和辣都不能多吃,但水可以多喝。
而过于柔和的画面,在强光照射或视力不佳时,可能无法保持足够的清晰度,绿柔反复调校参数才得到目前的结果。
我们查阅资料得知,人眼最喜欢的光是黄色和绿色
黄色和绿色的波长,是人眼最放松的波长。
绿柔的背景是暖黄色,界面中点缀不少绿色,前景的代码颜色,虽然多彩,但每种颜色的RGB中的G,即绿色值,都调大了。
另外从色彩心理学看,温暖的颜色比暗色更舒服。
人眼看到的景色,大脑会产生联想,并进而影响心情。
看到绿色就会联想到草原森林,心情不自觉的就好一点。
而看久了暗色或刺激性颜色,心情会压抑。
每天看8个小时屏幕不是小事,心情舒畅很重要。
"群体无小事,长期无小事",面对数百万开发者,我们必须下足功夫研究如何保护他们的健康。
结合了众多理论和实验,我们终于打磨出了绿柔主题。
有些产品的设计原则是漂亮优先,HX不是这个原则,是健康优先。HX可能不是最漂亮的编辑器,但肯定是最健康的编辑器。
护手:免拖动选择保护手指关节神经
鼠标手是程序员常见病,在鼠标操作时,什么操作劳损最严重?答案是拖选。
拖选过程是这样:食指按下鼠标左键,神经保持紧张,移动手腕带动鼠标移动,选择内容,松开食指。这个过程中,食指持续按下,相连的肌肉神经一直处于紧绷状态。
如果使用触摸板那更痛苦。
还是"偶尔无大事,长期无小事"的逻辑,偶尔拖选不觉得怎么样,但一天8小时写代码下来,手部劳损主因其实就是拖选。
为了减少拖选,HX提供了快捷键选择、智能双击选择、免选择直接操作等模式。
- 快捷键选择
Ctrl+=是以当前光标为初始点扩大选区,Ctrl+E是选择当前词或相同词,还有众多选择快捷键,具体见菜单-选择。 - 智能双击选择
HX在很多地方双击,会有特殊选择逻辑,在行首、行尾、函数块、等号、逗号、-号、括号、引号、行首列表符、<!-- -->等特殊语法符号处双击,都能快速选择相应内容。
掌握这套智能双击逻辑,即能极大的提高操作效率,又能减少手部劳损。
具体智能双击列表,见菜单选择。强烈建议认真研究掌握智能双击。 - 免选择直接操作
如果没有选内容,直接按Ctrl+C或X进行复制和剪切,可以对光标所在行复制剪切。
Ctrl+Insert重复选区、Ctrl+Shift+X交换选区等很多操作,也都在无选区时自动适配相应行操作。
Ctrl+D删除行、Ctrl+上下移动行、Shift+Del删除到行尾等操作也可以无选择直接操作文本内容。
更多功能见菜单编辑。
作为为开发者提供服务的公司,尤其是我们自己也是开发者,我们最重视的就是高效率和健康。
希望通过我们的努力,可以让中国数百万开发者的开发效率更高,身心更健康。
> 本帖已集成到: hx产品文档
键盘、椅子有人体工学,一个开发工具软件,有什么健不健康的概念呢?
当然有的。你的眼睛、手的健康,都与开发工具有很大关系。
DCloud是一家有匠心、有情怀的团队,在工具对人体的健康影响方面投入了大量精力财力研究。
护眼:绿柔环保主题
很多人误以为黑色主题最护眼,我们自己也曾长时间使用黑色主题,但感受不对劲,于是较真的研究了到底什么是健康护眼的主题。
其实参考电子书领域就知道,长时间盯着电脑屏幕或手机屏,背景绝不能是黑色,而应该是泛黄的颜色。如果一家做电子书的公司使用黑色背景的话,这公司肯定会被读者抛弃掉。
但是电子书行业为什么普遍采用泛黄色呢?是为了给读者制造看纸书的错觉?还是真有科学道理。我们需要仔细研究。
有一个误传的说法是:黑色背景,在液晶下发光量少,从而更护眼。
由于纯黑色背景很难看,实际上各个开发工具的背景色不是纯黑色,液晶面板上的粒子仍然在发光。
虽然液晶面板的暗色区光线量低,但就人眼肌肉的紧张度而言,高对比度的伤害大于光线量的伤害。
在阳光明媚的草原上,虽然光线量非常大,但人眼很舒适。
但在黑色屋子里,手机屏幕亮度调到最低,光线量远低于前者,但仍然刺眼。
这是对比度的影响造成的。
HBuilder的默认主题是绿柔,其特点是柔和、低对比度、强光下仍清晰、绿色感加强。对着这样的界面写一天代码,感受要比对着太亮或太暗的界面舒服很多。
绿柔是一个严谨的设计过程,包含色彩心理学和色彩生理学的很多知识,并且在北京国奥心理医院做过严谨的医学测试。
我们安排工程师在不同的配色主题下写代码,在医院检测他们的脑疲劳程度,最终调校出了绿柔配色方案,实验过程如下:
> 参与实验的2位程序员在充分休息后,分别使用绿柔和黑色主题的编程工具进行编码半小时,并监测脑电波的数据变化。
> 通过对实验者的脑电波产生的17万条数据的分析,利用医院仪器打印出的疲劳值、紧张度和注意力集中程度数值,发现实验结论如下:
> 半小时编码后2位测试者的疲劳度均上升,但,绿柔主题下工作的程序员疲劳值上升相对缓慢,紧张程度更低,注意力更集中。
> 使用黑色主题编码后疲劳值的上升幅度最高达到使用绿柔上升幅度的700%!
> 此实验进行多次,并有交叉测试,结论始终相同。
上图为在医院参与实验的程序员。
色彩方面有色彩生理学和色彩心理学。我们先从色彩生理学角度看看黑色主题的问题:
- 转场晕眩
当一个人眼睛长期看暗色系事物时,大脑会分泌激素强迫眼睛增强视力。
比如我们在一个黑屋子待一会就能看清东西,但回到阳光下时又会晕眩,这叫做暗适应。
同样,长期看黑色的代码区,此时切换到其他软件界面或看窗外就会晕眩。 - 夜盲症
长期的黑暗环境下眼球会分泌视紫红质,视紫红质消耗维生素A,并且会引发夜盲症,虽不是近视,但夜晚视力低于常人。
具体见百度百科视紫红质 - 对比度高
黑色背景往往对应高对比度的前景内容,而高对比度不适合长期观看。
其实就像糖和辣都不能多吃,但水可以多喝。
而过于柔和的画面,在强光照射或视力不佳时,可能无法保持足够的清晰度,绿柔反复调校参数才得到目前的结果。
我们查阅资料得知,人眼最喜欢的光是黄色和绿色
黄色和绿色的波长,是人眼最放松的波长。
绿柔的背景是暖黄色,界面中点缀不少绿色,前景的代码颜色,虽然多彩,但每种颜色的RGB中的G,即绿色值,都调大了。
另外从色彩心理学看,温暖的颜色比暗色更舒服。
人眼看到的景色,大脑会产生联想,并进而影响心情。
看到绿色就会联想到草原森林,心情不自觉的就好一点。
而看久了暗色或刺激性颜色,心情会压抑。
每天看8个小时屏幕不是小事,心情舒畅很重要。
"群体无小事,长期无小事",面对数百万开发者,我们必须下足功夫研究如何保护他们的健康。
结合了众多理论和实验,我们终于打磨出了绿柔主题。
有些产品的设计原则是漂亮优先,HX不是这个原则,是健康优先。HX可能不是最漂亮的编辑器,但肯定是最健康的编辑器。
护手:免拖动选择保护手指关节神经
鼠标手是程序员常见病,在鼠标操作时,什么操作劳损最严重?答案是拖选。
拖选过程是这样:食指按下鼠标左键,神经保持紧张,移动手腕带动鼠标移动,选择内容,松开食指。这个过程中,食指持续按下,相连的肌肉神经一直处于紧绷状态。
如果使用触摸板那更痛苦。
还是"偶尔无大事,长期无小事"的逻辑,偶尔拖选不觉得怎么样,但一天8小时写代码下来,手部劳损主因其实就是拖选。
为了减少拖选,HX提供了快捷键选择、智能双击选择、免选择直接操作等模式。
- 快捷键选择
Ctrl+=是以当前光标为初始点扩大选区,Ctrl+E是选择当前词或相同词,还有众多选择快捷键,具体见菜单-选择。 - 智能双击选择
HX在很多地方双击,会有特殊选择逻辑,在行首、行尾、函数块、等号、逗号、-号、括号、引号、行首列表符、<!-- -->等特殊语法符号处双击,都能快速选择相应内容。
掌握这套智能双击逻辑,即能极大的提高操作效率,又能减少手部劳损。
具体智能双击列表,见菜单选择。强烈建议认真研究掌握智能双击。 - 免选择直接操作
如果没有选内容,直接按Ctrl+C或X进行复制和剪切,可以对光标所在行复制剪切。
Ctrl+Insert重复选区、Ctrl+Shift+X交换选区等很多操作,也都在无选区时自动适配相应行操作。
Ctrl+D删除行、Ctrl+上下移动行、Shift+Del删除到行尾等操作也可以无选择直接操作文本内容。
更多功能见菜单编辑。
作为为开发者提供服务的公司,尤其是我们自己也是开发者,我们最重视的就是高效率和健康。
希望通过我们的努力,可以让中国数百万开发者的开发效率更高,身心更健康。
uni-app nvue沉浸式状态栏(线性渐变色)
<template>
<div class="page-searchList">
<div class="header">
<div class="statusBar" :style="{height:statusBarHeight+'wx'}"></div><!-- 状态栏占位 -->
<div class="info"><text style="font-size: 16wx;">标题栏</text></div>
</div>
<div class="content">
<text style="font-size: 50wx;">{{statusBarHeight}}wx</text> <!-- 打印状态栏高度 -->
</div>
</div>
</template>
<script>
export default {
data: {
statusBarHeight: ''
},
created() {
let _t = this;
setTimeout(() => { //获取状态栏高度,setTimeout后才能调用uni.
uni.getSystemInfo({
success: function(res) {
_t.statusBarHeight = res.statusBarHeight;
console.log(_t.statusBarHeight);
}
});
}, 1);
}
};
</script>
<style>
.page-searchList {
background-color: #8f8f94;
justify-content: center;
align-items: center;
}
.header {
background-image: linear-gradient(to right, #a80077, #66ff00);
width: 750px;
position: fixed;
top: 0;
}
.info {
height: 44wx;
justify-content: center;
align-items: center;
}
</style>
<template>
<div class="page-searchList">
<div class="header">
<div class="statusBar" :style="{height:statusBarHeight+'wx'}"></div><!-- 状态栏占位 -->
<div class="info"><text style="font-size: 16wx;">标题栏</text></div>
</div>
<div class="content">
<text style="font-size: 50wx;">{{statusBarHeight}}wx</text> <!-- 打印状态栏高度 -->
</div>
</div>
</template>
<script>
export default {
data: {
statusBarHeight: ''
},
created() {
let _t = this;
setTimeout(() => { //获取状态栏高度,setTimeout后才能调用uni.
uni.getSystemInfo({
success: function(res) {
_t.statusBarHeight = res.statusBarHeight;
console.log(_t.statusBarHeight);
}
});
}, 1);
}
};
</script>
<style>
.page-searchList {
background-color: #8f8f94;
justify-content: center;
align-items: center;
}
.header {
background-image: linear-gradient(to right, #a80077, #66ff00);
width: 750px;
position: fixed;
top: 0;
}
.info {
height: 44wx;
justify-content: center;
align-items: center;
}
</style>numbox 数字输入框 设置 data-numbox-min 大于 0 按减键到最小值获取不到值的问题
今天用了下 mui 自带的 numbox 数字输入框,发现设置了最小值 data-numbox-min=“1”,然后测试点击减键到最小值时获取不到值,但是 input 的值有正常改变,而减键也正常灰色被 disabled 了,却无法获取到改变后的值。
于是,想了想,还是去分析下 mui.js ,发现了这段代码:
if (self.options.min != null && !isNaN(self.options.min) && val <= parseInt(self.options.min)) {
val = self.options.min;
self.minus.disabled = true;
} else {
self.minus.disabled = false;
}看似这段代码没有问题。val = self.options.min; 是已经等于新值了,而且 val <= parseInt(self.options.min) 时也 self.minus.disabled = true; 正常屏蔽减键了。于是又想了下,是不是 self.minus.disabled = true; 速度太快导致 self.input.value = val; 没有优先获取到值呢?
突发奇想,将 self.minus.disabled = true; 延迟设置:
if (self.options.min != null && !isNaN(self.options.min) && val <= parseInt(self.options.min)) {
val = self.options.min;
setTimeout(function (){
self.minus.disabled = true;
}, 100); //怕没效果,可适时加大延迟时间
} else {
self.minus.disabled = false;
}凭着试一试的心理,然后测试了下,结果...OK!菜鸟的方法,分享给大家。
今天用了下 mui 自带的 numbox 数字输入框,发现设置了最小值 data-numbox-min=“1”,然后测试点击减键到最小值时获取不到值,但是 input 的值有正常改变,而减键也正常灰色被 disabled 了,却无法获取到改变后的值。
于是,想了想,还是去分析下 mui.js ,发现了这段代码:
if (self.options.min != null && !isNaN(self.options.min) && val <= parseInt(self.options.min)) {
val = self.options.min;
self.minus.disabled = true;
} else {
self.minus.disabled = false;
}看似这段代码没有问题。val = self.options.min; 是已经等于新值了,而且 val <= parseInt(self.options.min) 时也 self.minus.disabled = true; 正常屏蔽减键了。于是又想了下,是不是 self.minus.disabled = true; 速度太快导致 self.input.value = val; 没有优先获取到值呢?
突发奇想,将 self.minus.disabled = true; 延迟设置:
if (self.options.min != null && !isNaN(self.options.min) && val <= parseInt(self.options.min)) {
val = self.options.min;
setTimeout(function (){
self.minus.disabled = true;
}, 100); //怕没效果,可适时加大延迟时间
} else {
self.minus.disabled = false;
}凭着试一试的心理,然后测试了下,结果...OK!菜鸟的方法,分享给大家。
收起阅读 »关于离线打包的基本权限问题
本来做的APP不需要很多权限,结果离线打包出来还是提示一堆权限,前前后后调试了一整天,发现lib.5plus.base-release.aar这个基本包居然已经包含了读取通话记录,发送短信,读取联系人,录音,相机等权限,而把项目提交到dcloud的云打包则没这个问题,说实话MUI入门简单,但是很多地方给开发者的印象很不友好,比如hbuider云打包默认选择了加入广告联盟,不小心点错了想退出还得实名认证,退出还有时间限制。。。简直无语,这样的营销和技术只能做三四流APP的技术选型,格局太小。
本来做的APP不需要很多权限,结果离线打包出来还是提示一堆权限,前前后后调试了一整天,发现lib.5plus.base-release.aar这个基本包居然已经包含了读取通话记录,发送短信,读取联系人,录音,相机等权限,而把项目提交到dcloud的云打包则没这个问题,说实话MUI入门简单,但是很多地方给开发者的印象很不友好,比如hbuider云打包默认选择了加入广告联盟,不小心点错了想退出还得实名认证,退出还有时间限制。。。简直无语,这样的营销和技术只能做三四流APP的技术选型,格局太小。
收起阅读 »
郑州app制作公司开发app软件的攻略是什么
郑州app制作公司一般开发一款app的主要技能和开发攻略是什么呢?很多投资者因为不了解app开发流程,所以认为开发报价贵,那么下面就来跟大家详细的讲解一款app开发具体流程和主要技能吧。
1、app开发第一式:要掌握良好的产品技能,和用户体验技能,拥有这些技能之后,才会画出来相关的产品原型,和用户的使用流程,因此也就是说,开发app第一步就是它的产品原型规划与形成。
2、app开发第二式 : 要掌握网页设计的技能,通过第一招制作出来的产品原型,进行app主要功能的效果图设计,和其他主要界面构思与设计。
3、app开发第三式:是策划和产品预估的技能,同样这也是一个不断构思与推敲的过程。在制作app之前,必须要前期进行沟通,初步表明此款app要实现的效果,以及从产品体验和用户体验两方面对制作工期进行评估。
4、app开发第四式:app后台程序开发的技能,在项目评估结束后,就进入研发阶段。经过开发人员的研发。研发的同时还要把申请上线的时间留出来,这样就可以实现开发与运营同步进行。(由于我们今天主要讲的是开发的技能,所以运营不做过多的解释)
5、app开发第五式:app开发测试技能。产品开发基本成型后,我们的app就将正式进入内部测试阶段。只有内部测试合格,并确认没有严重报错之后,才可以开始着手上线公测的相关工作。
6app开发第七式:各大应用市场的提交下载技能,app选定好服务器以后app就可以正式上线。在提交app到各大市场时候值得注意的是,有些平台审核一般情况下需要一个星期左右时间,而大多数应用平台市场一般审核较快,大多需要3天左右的时间即可。
开发一个好的app除了要有强大的资金实力外,还要有产品,设计、策划、开发、测试、分析、提交下载等七项技能,只有熟练掌握这七项技能,我们才能开发出来一个不论功能、界面、还是用户体验都非常完美的app产品。
本文由专业的郑州app开发公司燚轩科技(appsaa.com)整理发布,如需转载请注明出处。
郑州app制作公司一般开发一款app的主要技能和开发攻略是什么呢?很多投资者因为不了解app开发流程,所以认为开发报价贵,那么下面就来跟大家详细的讲解一款app开发具体流程和主要技能吧。
1、app开发第一式:要掌握良好的产品技能,和用户体验技能,拥有这些技能之后,才会画出来相关的产品原型,和用户的使用流程,因此也就是说,开发app第一步就是它的产品原型规划与形成。
2、app开发第二式 : 要掌握网页设计的技能,通过第一招制作出来的产品原型,进行app主要功能的效果图设计,和其他主要界面构思与设计。
3、app开发第三式:是策划和产品预估的技能,同样这也是一个不断构思与推敲的过程。在制作app之前,必须要前期进行沟通,初步表明此款app要实现的效果,以及从产品体验和用户体验两方面对制作工期进行评估。
4、app开发第四式:app后台程序开发的技能,在项目评估结束后,就进入研发阶段。经过开发人员的研发。研发的同时还要把申请上线的时间留出来,这样就可以实现开发与运营同步进行。(由于我们今天主要讲的是开发的技能,所以运营不做过多的解释)
5、app开发第五式:app开发测试技能。产品开发基本成型后,我们的app就将正式进入内部测试阶段。只有内部测试合格,并确认没有严重报错之后,才可以开始着手上线公测的相关工作。
6app开发第七式:各大应用市场的提交下载技能,app选定好服务器以后app就可以正式上线。在提交app到各大市场时候值得注意的是,有些平台审核一般情况下需要一个星期左右时间,而大多数应用平台市场一般审核较快,大多需要3天左右的时间即可。
开发一个好的app除了要有强大的资金实力外,还要有产品,设计、策划、开发、测试、分析、提交下载等七项技能,只有熟练掌握这七项技能,我们才能开发出来一个不论功能、界面、还是用户体验都非常完美的app产品。
本文由专业的郑州app开发公司燚轩科技(appsaa.com)整理发布,如需转载请注明出处。
