





HBuilder X对vue的支持有多强?
HBuilderX中使用vue,如果是打开vue文件,会自动挂载vue语法库。
如果是HTML文件里引用vue框架,需要点右下角的语法提示库,选择vue语法库。
我们更推荐开发者使用vue单文件规范,直接打开vue文件。
注意:如果文件不在项目下,而是单独的文件,无法挂载语法库,请在左侧项目管理器建个项目,打开项目里的文件进行体验。
1.语法高亮
除了vue的普通语法高亮支持,HBuilderX还支持各种表达式语法,以及script和style支持的其他语言如less、scss、stylus、typescript等高亮,无需安装插件。
2.代码提示
2.1 API提示及帮助
提示不止是要全,而且要准。不能把所有词都猜一遍列出来,该有什么就有什么,清晰可信赖。
既要写的快,又要写不错。
除了完善的提示,在代码助手右侧还能看到清晰的帮助描述,对api进行说明,还有vue官网的api链接,点击即可直达vue官网指定页面。非常适合学习参考。
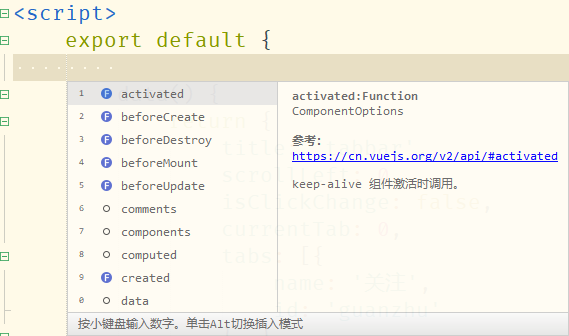
2.2 this的精准识别

2.3 语法提示
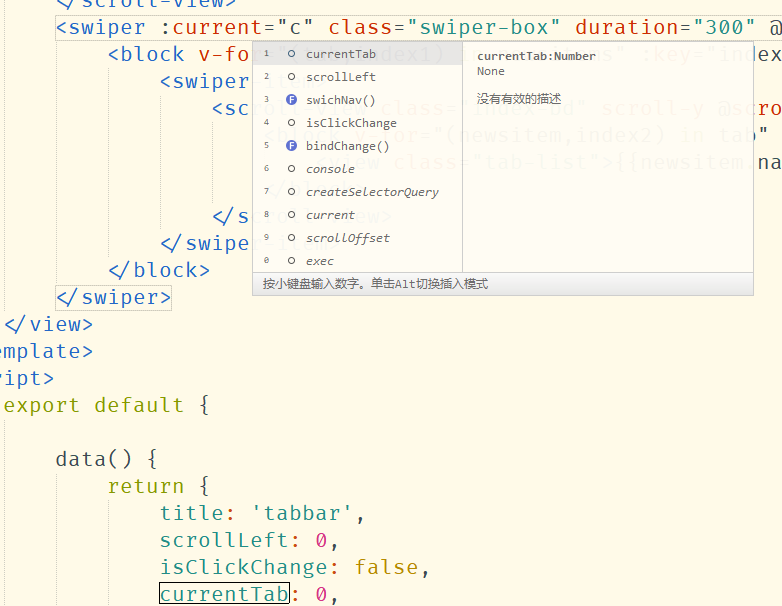
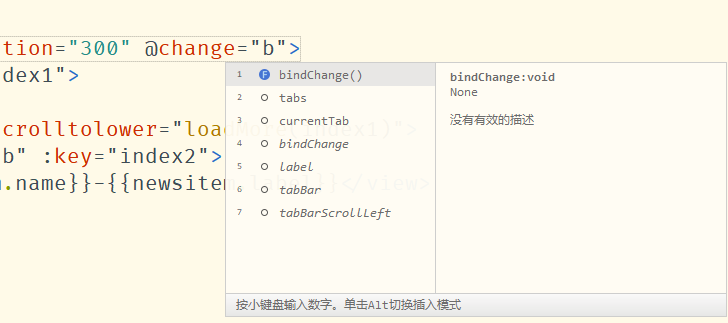
2.4 指令提示

2.5 自定义组件提示
HBuilderX的组件语法提示比其他工具都要强大,组件的标签、属性都可以直接被提示出来。

2.6 doc
HBuilderX支持强大的vue doc,是vue组件开发者的利器,通过类jsdoc的写法,可让你的组件实现全面的代码提示和帮助。详见https://ask.dcloud.net.cn/article/35814

2.7 兼容vscode vetur插件中的vue规范
一些vue的组件库,已经按照vetur规范制作语法提示库,比如Element UI、Onsen UI、Bootstrap Vue等框架。
这些框架npm安装或在HBuilderX新建模板中选择安装,可以直接实现代码提示。如下图
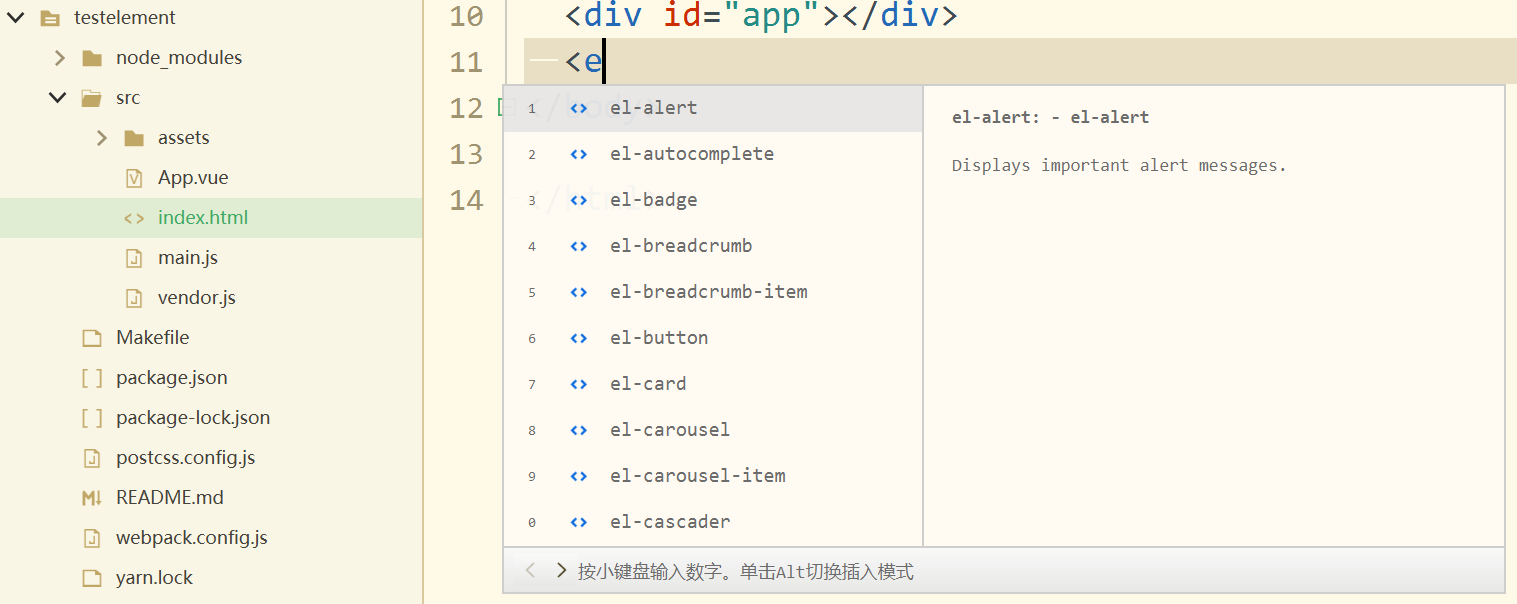
2.8 常用代码块/自定义代码块
敲v,在拉出的代码助手列表里可以看到大量vue代码块。
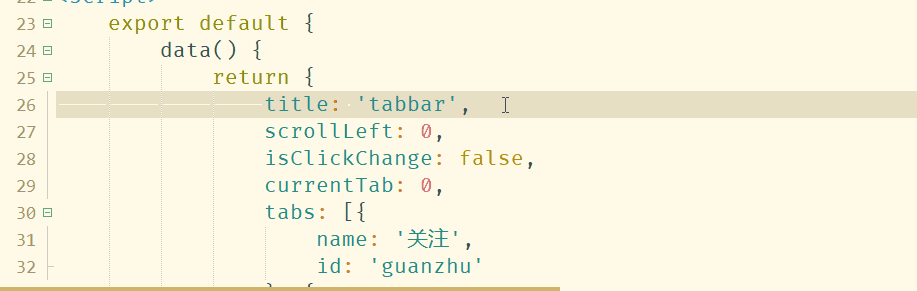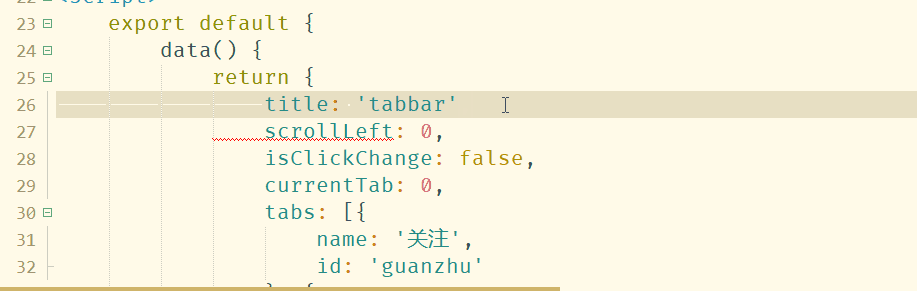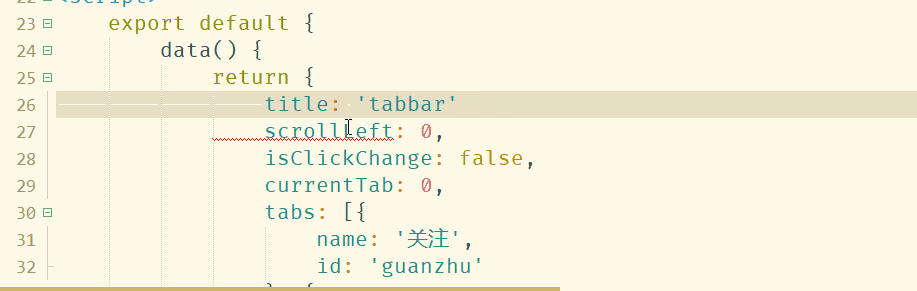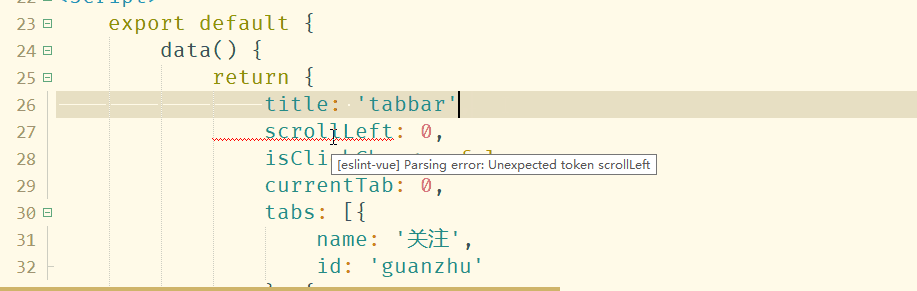
你也可以在工具-代码块设置-vue代码块里自己添加更多代码块。

2.9 vue router
支持提示$router、$route 所有实例方法、属性
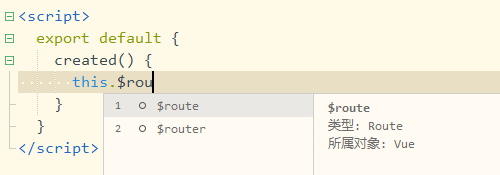

2.10 vuex
支持提示State、Mutation、action等,并支持转到定义


2.11 其他
另外其他开发工具常见的emmet、d.ts,HBuilderX也均良好支持。
3.帮助文档
光标放到api处,按下F1,可直接在右侧打开对应的帮助文档,不用切屏,边看文档边改代码,见下图:
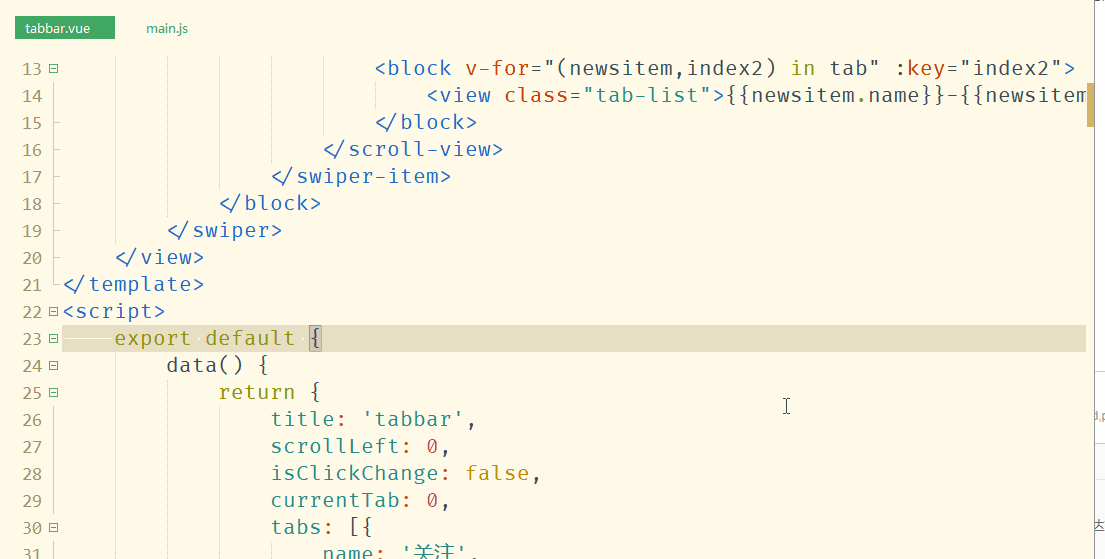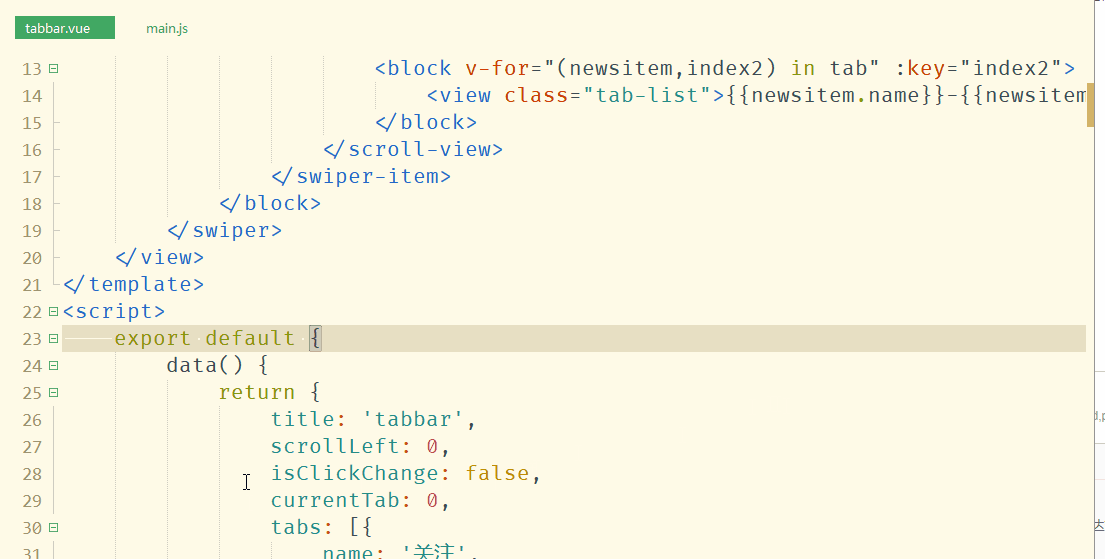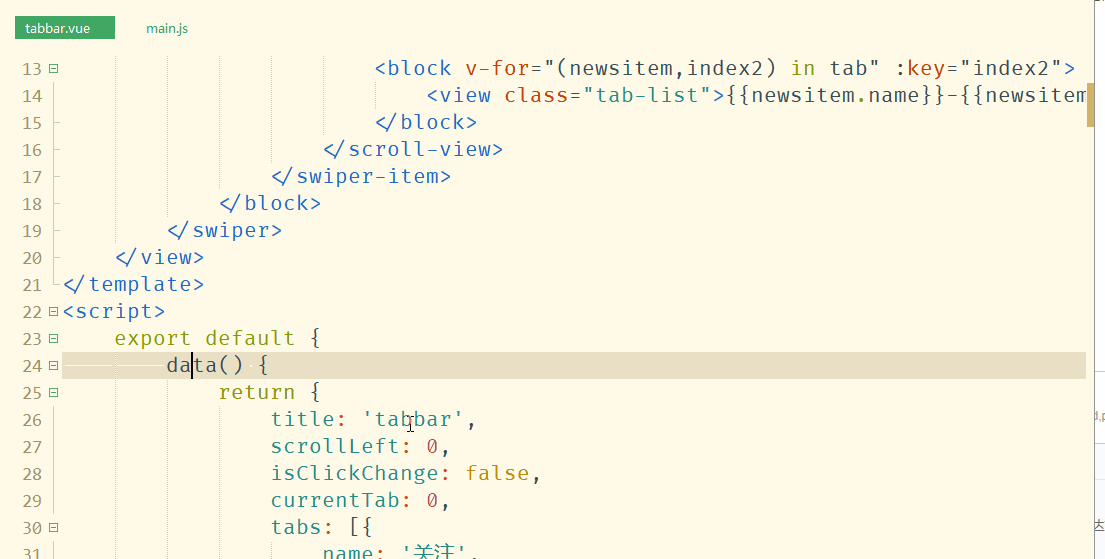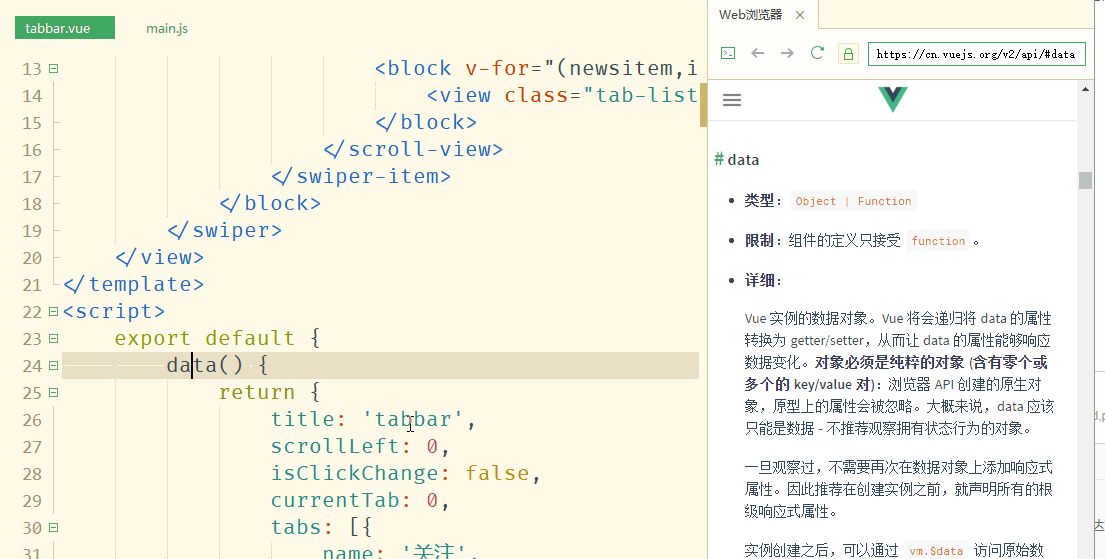
4.转到定义
按下alt+鼠标单击,即可对各种变量、样式、方法的引用溯源,在template、script、style中来回跳转。非常强大而灵活。
按下ctrl+alt+单击,还可在旁边以分栏方式打开定义处,方便并排查看。

5.重构或选择相同语法词
如果你想看某个变量在哪里被引用,或者选中所有变量进行改名,那么点右键->选择相同变量(ctrl+shift+e)。
如下图可见,“list”在文中出现很多相同单词,但只有那几个准确的变量被选中:

详情参考:https://ask.dcloud.net.cn/article/35732
6.语法校验
首先需要在插件管理中安装eslint-plugin-vue,然后点工具-验证本文档语法,或在vue文档保存时也会自动验证。
插件的管理设置如配置快捷键、是否在保存时自动触发,在工具-外部命令-eslint-plugin-vue里的插件配置里,详见http://ask.dcloud.net.cn/article/19599
如果要修改eslint的校验规则,在工具-外部命令-eslint-plugin-vue里的.eslintrc.js。
7. 大纲
选择视图菜单-显示文档结构图,或右键菜单里选择,即可在左侧出现大纲。点击左侧即可快读跳转右侧。

8. 免命令行使用vue
如果你不喜欢配置复杂的node环境,这并不影响你快速进入vue世界。
HBuilderX内置了终端插件和node环境。
在新建界面,可以可视化新建vue项目,而不需要配cli。
在运行菜单里,可以可视化的运行和build。

在引入插件时也无需安装node模块,uni-app插件市场可以可视化的导入插件(仅适用于uni-app),详见uni-app插件市场
HBuilderX中使用vue,如果是打开vue文件,会自动挂载vue语法库。
如果是HTML文件里引用vue框架,需要点右下角的语法提示库,选择vue语法库。
我们更推荐开发者使用vue单文件规范,直接打开vue文件。
注意:如果文件不在项目下,而是单独的文件,无法挂载语法库,请在左侧项目管理器建个项目,打开项目里的文件进行体验。
1.语法高亮
除了vue的普通语法高亮支持,HBuilderX还支持各种表达式语法,以及script和style支持的其他语言如less、scss、stylus、typescript等高亮,无需安装插件。
2.代码提示
2.1 API提示及帮助
提示不止是要全,而且要准。不能把所有词都猜一遍列出来,该有什么就有什么,清晰可信赖。
既要写的快,又要写不错。
除了完善的提示,在代码助手右侧还能看到清晰的帮助描述,对api进行说明,还有vue官网的api链接,点击即可直达vue官网指定页面。非常适合学习参考。
2.2 this的精准识别
2.3 语法提示
2.4 指令提示
2.5 自定义组件提示
HBuilderX的组件语法提示比其他工具都要强大,组件的标签、属性都可以直接被提示出来。
2.6 doc
HBuilderX支持强大的vue doc,是vue组件开发者的利器,通过类jsdoc的写法,可让你的组件实现全面的代码提示和帮助。详见https://ask.dcloud.net.cn/article/35814
2.7 兼容vscode vetur插件中的vue规范
一些vue的组件库,已经按照vetur规范制作语法提示库,比如Element UI、Onsen UI、Bootstrap Vue等框架。
这些框架npm安装或在HBuilderX新建模板中选择安装,可以直接实现代码提示。如下图
2.8 常用代码块/自定义代码块
敲v,在拉出的代码助手列表里可以看到大量vue代码块。
你也可以在工具-代码块设置-vue代码块里自己添加更多代码块。
2.9 vue router
支持提示$router、$route 所有实例方法、属性
2.10 vuex
支持提示State、Mutation、action等,并支持转到定义
2.11 其他
另外其他开发工具常见的emmet、d.ts,HBuilderX也均良好支持。
3.帮助文档
光标放到api处,按下F1,可直接在右侧打开对应的帮助文档,不用切屏,边看文档边改代码,见下图:
4.转到定义
按下alt+鼠标单击,即可对各种变量、样式、方法的引用溯源,在template、script、style中来回跳转。非常强大而灵活。
按下ctrl+alt+单击,还可在旁边以分栏方式打开定义处,方便并排查看。
5.重构或选择相同语法词
如果你想看某个变量在哪里被引用,或者选中所有变量进行改名,那么点右键->选择相同变量(ctrl+shift+e)。
如下图可见,“list”在文中出现很多相同单词,但只有那几个准确的变量被选中:
详情参考:https://ask.dcloud.net.cn/article/35732
6.语法校验
首先需要在插件管理中安装eslint-plugin-vue,然后点工具-验证本文档语法,或在vue文档保存时也会自动验证。
插件的管理设置如配置快捷键、是否在保存时自动触发,在工具-外部命令-eslint-plugin-vue里的插件配置里,详见http://ask.dcloud.net.cn/article/19599
如果要修改eslint的校验规则,在工具-外部命令-eslint-plugin-vue里的.eslintrc.js。
7. 大纲
选择视图菜单-显示文档结构图,或右键菜单里选择,即可在左侧出现大纲。点击左侧即可快读跳转右侧。
8. 免命令行使用vue
如果你不喜欢配置复杂的node环境,这并不影响你快速进入vue世界。
HBuilderX内置了终端插件和node环境。
在新建界面,可以可视化新建vue项目,而不需要配cli。
在运行菜单里,可以可视化的运行和build。
在引入插件时也无需安装node模块,uni-app插件市场可以可视化的导入插件(仅适用于uni-app),详见uni-app插件市场
收起阅读 »大道至简 知易行难 C# 完成WebSocket demo 用GoEasy实现Hello world
uniapp websocket体验demo:https://ext.dcloud.net.cn/plugin?id=1334
在现在Time cost和Labor cost进入项目并占据重要位置的开发理念里,当一款项目的目标、理念以及开发的要求非常明确时,怎样减少时间、人力成本以及降低开发风险以及成为一个项目在开发初期需要确定的重要因素。
大道至简 知易行难,作为一名开发人员站在开发的角度上来讲,怎样去攻克一个技术难题或者需要学习新的语言、技术去应用于新的项目,已经不会是最大的问题,而时间成本以及人力成本会是一个团队以及公司去考虑的侧重点。怎样去减少这些开发成本最终达到同样的期望效果,今天我给大家介绍一款产品:GoEasy, 简单而强大的三方WebSocket。
我为什么会用到GoEasy,最近公司推p2p新项目,在订单提醒这一块因为新项目配备开发人员较少,就算加班也不能在estimated time内完成。经过会议决定使用三方的产品来做这一块。筛选中最后决定选择看起来最简单的GoEasy。
只需要9分钟,从注册到推送实现
1 登录 www.goeasy.io
2 注册账号并登录
3 登录进入后台
我的应用→创建应用→选择地区→获取APP keys
这里选择地区有3个选项可以选择,华东(杭州)、美国东部(弗吉尼亚)、新加坡,根据产品使用用户所在地来选择效果最佳。
点开APP keys 查看
我们会获得2个对应的key,一个只能用来订阅channel来接收消息的Subscribe key和一个既可以发送消息也可以订阅channel来接受消息的Common key。
OK 现在用一个demo来展示,为什么只需要9分钟。
服务器→客户端
这里我用C#来演示,当然 GoEasy适用于任何语言和浏览器。
先用C#写一个Demo
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Net;
using System.IO;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
string postDataStr = "appkey=your app keyXXXXXXXXXXXXXXXXXXXXXXXXXXX";
//appkey
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://rest-hangzhou.goeasy.io/publish");
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded;charset=UTF-8";
request.ContentLength = Encoding.UTF8.GetByteCount(postDataStr);
Stream myRequestStream = request.GetRequestStream();
byte[] data = Encoding.UTF8.GetBytes(postDataStr);
myRequestStream.Write(data, 0, data.Length);
Console.WriteLine(data);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream,
Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
Console.WriteLine(retString);
Console.ReadLine();
myStreamReader.Close();
myResponseStream.Close();
}
}
}
用html 写一个接收端
<html>
<head>
<script type="text/javascript" src="https://cdn-hangzhou.goeasy.io/goeasy.js"></script>
<script type="text/javascript">
var goeasy = new GoEasy({
appkey: 'your app keyXXXXXXXXXXXXXX'
});
goeasy.subscribe({
channel: 'demo',
onMessage: function(message){
//收到消息的第一行,打出日志,以这个时间作为检查的标准
alert('收到:' message.content);
}
});
</script>
</head> </html>
这里我用的是Common key,在实战项目中,接收端使用Common key会存在安全缺陷,建议使用Subscribe key。
还有需要注意的一点就是,CDN host和Rest host 取决于你在创建应用时的选择。
最后从页面接受结果可以看到与C#中demo content推送的内容一致。
同时,我们也可以完成客户端→客户端的推送
发送端
<!DOCTYPE html>
<html>
<html>
<head>
<script type="text/javascript" src="https://cdn-hangzhou.goeasy.io/goeasy.js"></script>
<script type="text/javascript">
var goeasy = new GoEasy({
appkey: 'your app keyXXXXXXXXXXXXXX'
});
function publishMessage() {
var publishMessage = document.getElementById("content").value;
goeasy.publish({
channel: 'demo',
message: publishMessage,
onFailed: function (error) {
alert(error.code " : " error.content);
},
onSuccess: function(){
document.getElementById("content").value='';
}
});
}
</script>
</head>
<body>
<textarea rows="3" cols="20" id="content"> uniapp websocket体验demo:https://ext.dcloud.net.cn/plugin?id=1334
在现在Time cost和Labor cost进入项目并占据重要位置的开发理念里,当一款项目的目标、理念以及开发的要求非常明确时,怎样减少时间、人力成本以及降低开发风险以及成为一个项目在开发初期需要确定的重要因素。
大道至简 知易行难,作为一名开发人员站在开发的角度上来讲,怎样去攻克一个技术难题或者需要学习新的语言、技术去应用于新的项目,已经不会是最大的问题,而时间成本以及人力成本会是一个团队以及公司去考虑的侧重点。怎样去减少这些开发成本最终达到同样的期望效果,今天我给大家介绍一款产品:GoEasy, 简单而强大的三方WebSocket。
我为什么会用到GoEasy,最近公司推p2p新项目,在订单提醒这一块因为新项目配备开发人员较少,就算加班也不能在estimated time内完成。经过会议决定使用三方的产品来做这一块。筛选中最后决定选择看起来最简单的GoEasy。
只需要9分钟,从注册到推送实现
1 登录 www.goeasy.io
2 注册账号并登录
3 登录进入后台
我的应用→创建应用→选择地区→获取APP keys
这里选择地区有3个选项可以选择,华东(杭州)、美国东部(弗吉尼亚)、新加坡,根据产品使用用户所在地来选择效果最佳。
点开APP keys 查看
我们会获得2个对应的key,一个只能用来订阅channel来接收消息的Subscribe key和一个既可以发送消息也可以订阅channel来接受消息的Common key。
OK 现在用一个demo来展示,为什么只需要9分钟。
服务器→客户端
这里我用C#来演示,当然 GoEasy适用于任何语言和浏览器。
先用C#写一个Demo
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Net;
using System.IO;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
string postDataStr = "appkey=your app keyXXXXXXXXXXXXXXXXXXXXXXXXXXX";
//appkey
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://rest-hangzhou.goeasy.io/publish");
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded;charset=UTF-8";
request.ContentLength = Encoding.UTF8.GetByteCount(postDataStr);
Stream myRequestStream = request.GetRequestStream();
byte[] data = Encoding.UTF8.GetBytes(postDataStr);
myRequestStream.Write(data, 0, data.Length);
Console.WriteLine(data);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream,
Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
Console.WriteLine(retString);
Console.ReadLine();
myStreamReader.Close();
myResponseStream.Close();
}
}
}
用html 写一个接收端
<html>
<head>
<script type="text/javascript" src="https://cdn-hangzhou.goeasy.io/goeasy.js"></script>
<script type="text/javascript">
var goeasy = new GoEasy({
appkey: 'your app keyXXXXXXXXXXXXXX'
});
goeasy.subscribe({
channel: 'demo',
onMessage: function(message){
//收到消息的第一行,打出日志,以这个时间作为检查的标准
alert('收到:' message.content);
}
});
</script>
</head> </html>
这里我用的是Common key,在实战项目中,接收端使用Common key会存在安全缺陷,建议使用Subscribe key。
还有需要注意的一点就是,CDN host和Rest host 取决于你在创建应用时的选择。
最后从页面接受结果可以看到与C#中demo content推送的内容一致。
同时,我们也可以完成客户端→客户端的推送
发送端
<!DOCTYPE html>
<html>
<html>
<head>
<script type="text/javascript" src="https://cdn-hangzhou.goeasy.io/goeasy.js"></script>
<script type="text/javascript">
var goeasy = new GoEasy({
appkey: 'your app keyXXXXXXXXXXXXXX'
});
function publishMessage() {
var publishMessage = document.getElementById("content").value;
goeasy.publish({
channel: 'demo',
message: publishMessage,
onFailed: function (error) {
alert(error.code " : " error.content);
},
onSuccess: function(){
document.getElementById("content").value='';
}
});
}
</script>
</head>
<body>
<textarea rows="3" cols="20" id="content"> HBuilderX的nodejs插件配置
HBuilderX支持多种插件,比较重要的一大类插件就是nodejs插件。
市场上存在大量的基于nodejs的工具,包括格式化、语法验证、编译器等等。
这类插件往往使用一个package.json来做插件配置。
在HBuilderX中使用这类插件说明如下。
- 在菜单工具-插件中选择要安装的插件。
- 插件安装后,有时会有三方依赖的module在继续安装,如果npm连不上,可能会安装失败。
- 安装成功后,对文件点右键-外部命令,展开的菜单里会有可用插件菜单。注意如果是语言依赖插件,比如less编译插件,必须对less文件点右键-外部命令,才会出现对应插件。在其他语言文件的右键里不会出现less编译插件。
- 除了命令本身的菜单,插件下还有配置菜单,点击会打开package.json文件,可以在里面设置快捷键、编译路径等,其中的command节点可用于自定义,说明如下:
{
//名称,用于在“工具-运行外部命令”菜单中显示
"name":"Echo",
//需要执行的外部命令及参数:
"command": [
"${programPath}",
"${file}",
"${fileBasename}.css" //以less为例,如果在aa.less文件上执行编译插件,{fileBasename}的值即为aa。
],
"extensions": "less", //设定在何种后缀名的文件中生效。即在非*.less文件的外部命令菜单里不会出现less编译选项。
"key": "ctrl shift r", //快捷键, 可通过此快捷键直接运行此外部命令
"showInParentMenu": false, //是否显示在外部命令顶级菜单,如果该命令较常用且希望点击层次更少,可以使用此选项
"onDidSaveExecution": false //是否在保存时自动触发。如配为true,就会在保存时自动触发
}
//------------外部命令 变量说明------------//
//"command"、"workingDir"中可使用预定义的变量来获取当前文件的路径信息
// - ${file} 当前文件的完整路径,比如 D:\files\test.txt
// - ${fileName} 当前文件的文件名,比如 test.txt
// - ${fileExtension} 当前文件的扩展名,比如 txt
// - ${fileBasename} 当前文件仅包含文件名的部分,比如 test
// - ${fileDir} 当前文件所在目录的完整路径,比如 D:\files
// - ${projectDir} 当前文件所在项目的完整路径,只有当前文件是项目管理器中某个项目下的文件时才起作用
注意以上文件的注释仅作为教程说明,真实的package.json里无法编写注释。
- eslint配置
对于eslint的语法校验插件,外部命令里还会有个.eslintrc.js配置。
打开后里面的文件有教程链接,这个是eslint的官方配置文件,请自定参考其教程配置。 - jsbeautify、jshint配置
jsbeautify格式化插件和jshint语法校验插件属于HBuilderX的内置插件,这些配置文件在HBuilderX的setting里,点菜单工具设置,里面有beautify.和jshint.开头的节点,复制并在右侧用户设置里粘贴,然后修改保存即可生效。 - 插件卸载
HBuilderX的插件均安装在HBuilderX所在目录的plugin目录下,不像很多其他软件安装在user目录下占用大量空间。
插件卸载其实就是删除plugin目录下的文件。
但很多nodejs插件的module文件数量非常多,这确实也是nodejs为人诟病的地方。os一般都有每次删除文件的上限,过多的文件会导致插件卸载失败。此时需要手动去node_modules目录里分批次删除文件。
HBuilderX支持多种插件,比较重要的一大类插件就是nodejs插件。
市场上存在大量的基于nodejs的工具,包括格式化、语法验证、编译器等等。
这类插件往往使用一个package.json来做插件配置。
在HBuilderX中使用这类插件说明如下。
- 在菜单工具-插件中选择要安装的插件。
- 插件安装后,有时会有三方依赖的module在继续安装,如果npm连不上,可能会安装失败。
- 安装成功后,对文件点右键-外部命令,展开的菜单里会有可用插件菜单。注意如果是语言依赖插件,比如less编译插件,必须对less文件点右键-外部命令,才会出现对应插件。在其他语言文件的右键里不会出现less编译插件。
- 除了命令本身的菜单,插件下还有配置菜单,点击会打开package.json文件,可以在里面设置快捷键、编译路径等,其中的command节点可用于自定义,说明如下:
{
//名称,用于在“工具-运行外部命令”菜单中显示
"name":"Echo",
//需要执行的外部命令及参数:
"command": [
"${programPath}",
"${file}",
"${fileBasename}.css" //以less为例,如果在aa.less文件上执行编译插件,{fileBasename}的值即为aa。
],
"extensions": "less", //设定在何种后缀名的文件中生效。即在非*.less文件的外部命令菜单里不会出现less编译选项。
"key": "ctrl shift r", //快捷键, 可通过此快捷键直接运行此外部命令
"showInParentMenu": false, //是否显示在外部命令顶级菜单,如果该命令较常用且希望点击层次更少,可以使用此选项
"onDidSaveExecution": false //是否在保存时自动触发。如配为true,就会在保存时自动触发
}
//------------外部命令 变量说明------------//
//"command"、"workingDir"中可使用预定义的变量来获取当前文件的路径信息
// - ${file} 当前文件的完整路径,比如 D:\files\test.txt
// - ${fileName} 当前文件的文件名,比如 test.txt
// - ${fileExtension} 当前文件的扩展名,比如 txt
// - ${fileBasename} 当前文件仅包含文件名的部分,比如 test
// - ${fileDir} 当前文件所在目录的完整路径,比如 D:\files
// - ${projectDir} 当前文件所在项目的完整路径,只有当前文件是项目管理器中某个项目下的文件时才起作用
注意以上文件的注释仅作为教程说明,真实的package.json里无法编写注释。
- eslint配置
对于eslint的语法校验插件,外部命令里还会有个.eslintrc.js配置。
打开后里面的文件有教程链接,这个是eslint的官方配置文件,请自定参考其教程配置。 - jsbeautify、jshint配置
jsbeautify格式化插件和jshint语法校验插件属于HBuilderX的内置插件,这些配置文件在HBuilderX的setting里,点菜单工具设置,里面有beautify.和jshint.开头的节点,复制并在右侧用户设置里粘贴,然后修改保存即可生效。 - 插件卸载
HBuilderX的插件均安装在HBuilderX所在目录的plugin目录下,不像很多其他软件安装在user目录下占用大量空间。
插件卸载其实就是删除plugin目录下的文件。
但很多nodejs插件的module文件数量非常多,这确实也是nodejs为人诟病的地方。os一般都有每次删除文件的上限,过多的文件会导致插件卸载失败。此时需要手动去node_modules目录里分批次删除文件。
nview在uni-app中实现原生自定义titlebar
uni-app出来了,研究后发现并不是想象的那样以为是nml,新版会支持ios打包。uni-app究竟是什么?实际上就是h5+加入了vue。
为什么能发布小程序,我猜实际上是把源代码的变量,函数,api等经过一系列的替换成小程序的源码。
1、uni-app的titlebar和tabbar是原生的组件,速度非常快。但是titlebar可自定义不强。开始想着在uni-app中webview中实现的html模拟的titlebar
//先隐藏太监式的titlebar
"globalStyle": {
"navigationStyle":"custom"
},2、在切换页面时控制原生自定义的ntitlebar的显示与隐藏。
最好全局创建一个公用的ntitlebar,需要的时候只控制隐藏与显示,并传参数:改变title,显示返回图标,显示菜单图标,显示搜索图标,显示搜索框等)这个还没研究(主要在事件穿透和显示上,肯定能实现,待深入...),即使用下面的创建与销毁都比webview要快不少,感觉完成整个blank页面的切换显示ntitlebar只需10ms左右。在uni-app中webview中实现的titlebar切换显示大概得150ms-300ms左右。
onShow:function(option){
var ntitlebar = new plus.nativeObj.View('test',
{top:'0px',left:'0px',height:'49px',width:'100%',backgroundColor:'#3A3A3A',statusbar:{background:'#333333'}},
[
{tag:'rect',id:'rect',color:'#FF0000',position:{top:'12px',left:'12px',width:'24px',height:'24px'}},
{tag:'font',id:'font',text:'原生控件',textStyles:{size:'18px'}}
]
);
},
onHide:function(option){
this.global.ntitlebar.close();
},uni-app出来了,研究后发现并不是想象的那样以为是nml,新版会支持ios打包。uni-app究竟是什么?实际上就是h5+加入了vue。
为什么能发布小程序,我猜实际上是把源代码的变量,函数,api等经过一系列的替换成小程序的源码。
1、uni-app的titlebar和tabbar是原生的组件,速度非常快。但是titlebar可自定义不强。开始想着在uni-app中webview中实现的html模拟的titlebar
//先隐藏太监式的titlebar
"globalStyle": {
"navigationStyle":"custom"
},2、在切换页面时控制原生自定义的ntitlebar的显示与隐藏。
最好全局创建一个公用的ntitlebar,需要的时候只控制隐藏与显示,并传参数:改变title,显示返回图标,显示菜单图标,显示搜索图标,显示搜索框等)这个还没研究(主要在事件穿透和显示上,肯定能实现,待深入...),即使用下面的创建与销毁都比webview要快不少,感觉完成整个blank页面的切换显示ntitlebar只需10ms左右。在uni-app中webview中实现的titlebar切换显示大概得150ms-300ms左右。
onShow:function(option){
var ntitlebar = new plus.nativeObj.View('test',
{top:'0px',left:'0px',height:'49px',width:'100%',backgroundColor:'#3A3A3A',statusbar:{background:'#333333'}},
[
{tag:'rect',id:'rect',color:'#FF0000',position:{top:'12px',left:'12px',width:'24px',height:'24px'}},
{tag:'font',id:'font',text:'原生控件',textStyles:{size:'18px'}}
]
);
},
onHide:function(option){
this.global.ntitlebar.close();
},
iphonex 沉浸式状态栏适配
沉浸式状态栏时,iphonex做适配时,预留的状态栏的高度不再是20px,应该预留44px:

if(plus.navigator.isImmersedStatusbar()){
var barHeight = plus.device.model == 'iPhoneX' ? 44 : Math.round(plus.navigator.getStatusbarHeight());
}
调整前

调整后

底部主菜单切换高度应调整为83px
调整前

调整后

沉浸式状态栏时,iphonex做适配时,预留的状态栏的高度不再是20px,应该预留44px:
if(plus.navigator.isImmersedStatusbar()){
var barHeight = plus.device.model == 'iPhoneX' ? 44 : Math.round(plus.navigator.getStatusbarHeight());
}
调整前
调整后
底部主菜单切换高度应调整为83px
调整前
调整后
解决了ios云打包位置描述的问题
在manifest.json 文件夹下边
plus->apple,添加
,
"plistcmds":[
"Set :NSContactsUsageDescription 说明读取用户通讯录的原因",
"Set :NSMicrophoneUsageDescription 说明使用麦克风的原因",
"Set :NSPhotoLibraryUsageDescription 上传图片需要访问相册权限",
"Set :NSCameraUsageDescription 上传图片需要访问相机权限",
"Set :NSPhotoLibraryAddUsageDescription 保存图片需要访问相册权限",
"Set :NSLocationWhenInUseDescription 这儿是xcode9之前使用的,估计云打包的时候就是使用的xcode9之前的版本",
"Set :NSLocationWhenInUseUsageDescription xcode9之后",
"Set :NSLocationAlwaysUsageDescription xcode9之后",
"Set :NSLocationAlwaysAndWhenInUseUsageDescription xcode9之后"
]
亲测可用
在manifest.json 文件夹下边
plus->apple,添加
,
"plistcmds":[
"Set :NSContactsUsageDescription 说明读取用户通讯录的原因",
"Set :NSMicrophoneUsageDescription 说明使用麦克风的原因",
"Set :NSPhotoLibraryUsageDescription 上传图片需要访问相册权限",
"Set :NSCameraUsageDescription 上传图片需要访问相机权限",
"Set :NSPhotoLibraryAddUsageDescription 保存图片需要访问相册权限",
"Set :NSLocationWhenInUseDescription 这儿是xcode9之前使用的,估计云打包的时候就是使用的xcode9之前的版本",
"Set :NSLocationWhenInUseUsageDescription xcode9之后",
"Set :NSLocationAlwaysUsageDescription xcode9之后",
"Set :NSLocationAlwaysAndWhenInUseUsageDescription xcode9之后"
]
亲测可用
WebSocket跨域问题解决
uniapp websocket体验demo:https://ext.dcloud.net.cn/plugin?id=1334
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
项目中遇到javascript跨域问题,父页面和子页面要通信,并且父子页面跨域,怎么办?
项目中要保证父子页面通信是点对点,需要在服务端建立对父子页面WebSocket的对应关系,即父页面发的消息只被子页面收到,子页面的消息也只被父页面收到我们做了以下工作,严格保证了
WebSocket通信是点对点:
一是建立WebSocket链接的URL加上时间戳保证通信会话是唯一的;
二是在服务端保证父子页面WebSocket一一对应关系。父子页面的WebSocket在Open时都会向服务端发出消息进行注册,建立Senssion之间的对应关系。然后父子页面就可通过双方约束的通信协议进行通信了。
这里我们写个demo:
var p = document.getElementsByTagName(‘p’)[0];
var io = io.connect(‘http://127.0.0.1:3001’);
io.on(‘data’,function(data){
alert(‘2S后改变数据’);
p.innerHTML = data
});
服务器端
var io = require(‘socket.io’)(server);
io.on(‘connection’,function(client){
client.emit(‘data’,’hello WebSocket from 3001.’);
});
今天就说到这里,希望对大家有所帮助,同时大家如果不想太花时间去做WebSocket这块,可以尝试使用三方WebSocket,类似GoEasy 极光之类的。
这里推荐GoEasy,简单易用 www.goeasy.io 还是免费的,可以尝试一下。
uniapp websocket体验demo:https://ext.dcloud.net.cn/plugin?id=1334
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
项目中遇到javascript跨域问题,父页面和子页面要通信,并且父子页面跨域,怎么办?
项目中要保证父子页面通信是点对点,需要在服务端建立对父子页面WebSocket的对应关系,即父页面发的消息只被子页面收到,子页面的消息也只被父页面收到我们做了以下工作,严格保证了
WebSocket通信是点对点:
一是建立WebSocket链接的URL加上时间戳保证通信会话是唯一的;
二是在服务端保证父子页面WebSocket一一对应关系。父子页面的WebSocket在Open时都会向服务端发出消息进行注册,建立Senssion之间的对应关系。然后父子页面就可通过双方约束的通信协议进行通信了。
这里我们写个demo:
var p = document.getElementsByTagName(‘p’)[0];
var io = io.connect(‘http://127.0.0.1:3001’);
io.on(‘data’,function(data){
alert(‘2S后改变数据’);
p.innerHTML = data
});
服务器端
var io = require(‘socket.io’)(server);
io.on(‘connection’,function(client){
client.emit(‘data’,’hello WebSocket from 3001.’);
});
今天就说到这里,希望对大家有所帮助,同时大家如果不想太花时间去做WebSocket这块,可以尝试使用三方WebSocket,类似GoEasy 极光之类的。
这里推荐GoEasy,简单易用 www.goeasy.io 还是免费的,可以尝试一下。
周报(20180727):uni-app 它来了
热门话题
uni-app 它来了,详见uni-app开始公测!基于vue,一套代码,运行到iOS、Android、微信小程序。
欢迎大家积极参与公测,反馈问题及建议。
问题清单
- 二维码云打包后闪退:云打包的权限问题,按照文中的说明,勾选权限后再打包即可。
- 二维码扫描位置偏移:初始化时机的问题,需要稍微加一点延时。
- mui init初始化预加载preloadPages无效:在一个通过 preload 预加载的页面中,继续使用 preloadPages 进行预加载是不可行的。
- 在实现微信分享功能时出现华为手机安装解析错误问题:包名需要全部小写,部分 SDK 对于包名的校验会更加严格。
- 官方演示feedback.html能改进成多图选择吗?:简单调整下逻辑即可,详见问题最佳回复。
- push本地消息需要配置push模块吗:需要配置模块,SDK 配置信息随便填写一下就行。
- 全面屏手机 splash 被拉伸 该如何适配?:可以使用.9格式的图片来避免拉伸问题,网上找个相应的工具生成。
- 使用云端打包Android应用安装到手机后,mui.toast("xxx")会带应用名称:这个和 ROM 有关,可以用 richtext 方案处理。
- Hbuilder生成app IOS苹果回到桌面时app图标缩小过程有黑色阴影:logo 图不要用圆角。
- 这样把私钥也填写再app中,安全吗:针对此类问题,如果大家有更好的方案和想法,欢迎提出来。
iOS 近期问题
- iOS云打包修改权限提示语:部分权限需要添加提示语,如果按照文档说明填写,云打包后依旧没有生效,请单独发帖详细说明并提供应用的 appid 即 manifest.json->id。这个 appid 是 DCloud 云服务的,而非 AppStore 中 App 的 Appid。
- iOS被拒,消息推送:详见问题中的回复。
云服务
- 云端打包校验应用属主权限:为规范应用管理,云端打包会检验 appid 属主及协作者权限,详见文章。
广告联盟
许多小伙伴一遇到广告,就会认为是 DCloud 广告联盟的,这个锅真的背不了。如果你的应用中出现了非预期的广告,请先仔细阅读《广告误开原因汇总及解决办法》中的说明,确认下广告的来源然后再查找相应的对策。如果不能确认广告的来源,请单独发帖提供截图(这个必须得有)以及 manifest.json->id 等信息,方便协助处理。
- 广告开通状态显示是关闭状态,为什么在打包的时候还是显示开通了广告:之前勾选过就会提示,实际状态以 DCloud 开发者中心应用信息中显示的状态为准。
- 广告收入是不是太少了?:要更多的 App 加入进来,量上去了自然就可能和广告主谈更好的价格。
- 云打包时勾选广告,只有账号通过实名认证且财务信息审核通过,才会显示广告。因此打包时勾选了的不要太过惊慌,还可以登录 DCloud 开发者中心确认一下。
广告不是洪水猛兽,合理地运用是为了带来更好的推广效果及收益。DCloud 不会做恶意捆绑等行为,希望各位小伙伴在这个问题上不要太敏感,有疑惑的地方请发帖咨询。
商务合作,请发送邮件到 marketing@dcloud.io 沟通。
关于社区
使用 DCloud 产品过程中,遇到问题或有不满意的地方,可以在社区发帖交流。提问时,请先阅读《如何正确高效地在社区提问》,按照文章中的说明描述清楚问题,提供必要的信息以及测试 demo。希望大家能够认真对待,尽量不要发“一句话”问题,那样的话别人很难帮助到你。
良好的社区氛围,需要大家共同参与进来。如果你对于社区的建设有自己的想法或建议,欢迎留言或单独发帖陈述。
最后
本周的报告就是这些,希望能对大家有所帮助。同时,也希望更多的小伙伴在社区分享自己的经验心得,交流学习。
祝大家周末愉快。

热门话题
uni-app 它来了,详见uni-app开始公测!基于vue,一套代码,运行到iOS、Android、微信小程序。
欢迎大家积极参与公测,反馈问题及建议。
问题清单
- 二维码云打包后闪退:云打包的权限问题,按照文中的说明,勾选权限后再打包即可。
- 二维码扫描位置偏移:初始化时机的问题,需要稍微加一点延时。
- mui init初始化预加载preloadPages无效:在一个通过 preload 预加载的页面中,继续使用 preloadPages 进行预加载是不可行的。
- 在实现微信分享功能时出现华为手机安装解析错误问题:包名需要全部小写,部分 SDK 对于包名的校验会更加严格。
- 官方演示feedback.html能改进成多图选择吗?:简单调整下逻辑即可,详见问题最佳回复。
- push本地消息需要配置push模块吗:需要配置模块,SDK 配置信息随便填写一下就行。
- 全面屏手机 splash 被拉伸 该如何适配?:可以使用.9格式的图片来避免拉伸问题,网上找个相应的工具生成。
- 使用云端打包Android应用安装到手机后,mui.toast("xxx")会带应用名称:这个和 ROM 有关,可以用 richtext 方案处理。
- Hbuilder生成app IOS苹果回到桌面时app图标缩小过程有黑色阴影:logo 图不要用圆角。
- 这样把私钥也填写再app中,安全吗:针对此类问题,如果大家有更好的方案和想法,欢迎提出来。
iOS 近期问题
- iOS云打包修改权限提示语:部分权限需要添加提示语,如果按照文档说明填写,云打包后依旧没有生效,请单独发帖详细说明并提供应用的 appid 即 manifest.json->id。这个 appid 是 DCloud 云服务的,而非 AppStore 中 App 的 Appid。
- iOS被拒,消息推送:详见问题中的回复。
云服务
- 云端打包校验应用属主权限:为规范应用管理,云端打包会检验 appid 属主及协作者权限,详见文章。
广告联盟
许多小伙伴一遇到广告,就会认为是 DCloud 广告联盟的,这个锅真的背不了。如果你的应用中出现了非预期的广告,请先仔细阅读《广告误开原因汇总及解决办法》中的说明,确认下广告的来源然后再查找相应的对策。如果不能确认广告的来源,请单独发帖提供截图(这个必须得有)以及 manifest.json->id 等信息,方便协助处理。
- 广告开通状态显示是关闭状态,为什么在打包的时候还是显示开通了广告:之前勾选过就会提示,实际状态以 DCloud 开发者中心应用信息中显示的状态为准。
- 广告收入是不是太少了?:要更多的 App 加入进来,量上去了自然就可能和广告主谈更好的价格。
- 云打包时勾选广告,只有账号通过实名认证且财务信息审核通过,才会显示广告。因此打包时勾选了的不要太过惊慌,还可以登录 DCloud 开发者中心确认一下。
广告不是洪水猛兽,合理地运用是为了带来更好的推广效果及收益。DCloud 不会做恶意捆绑等行为,希望各位小伙伴在这个问题上不要太敏感,有疑惑的地方请发帖咨询。
商务合作,请发送邮件到 marketing@dcloud.io 沟通。
关于社区
使用 DCloud 产品过程中,遇到问题或有不满意的地方,可以在社区发帖交流。提问时,请先阅读《如何正确高效地在社区提问》,按照文章中的说明描述清楚问题,提供必要的信息以及测试 demo。希望大家能够认真对待,尽量不要发“一句话”问题,那样的话别人很难帮助到你。
良好的社区氛围,需要大家共同参与进来。如果你对于社区的建设有自己的想法或建议,欢迎留言或单独发帖陈述。
最后
本周的报告就是这些,希望能对大家有所帮助。同时,也希望更多的小伙伴在社区分享自己的经验心得,交流学习。
祝大家周末愉快。
HBuilderX对json的优化有多强
> 本帖文档已集成到: hx产品文档
json是一种对计算机友好,对人不友好的文件格式。
以前都是服务器生成json,前端程序员很少手写json。
但现代前端开发里,json的应用范围越来越多,各种配置文件、js的export里,全是json,写起来让人倍感痛苦,遍地是坑。
比如半角符号错输成全角,比如少了逗号或结尾多了逗号,比如没有语法提示和代码块,比如键值对的选中和复制很低效...
HBuilderX提供了多项优化技巧,达到最好的json编辑体验。学会这些,效率翻倍!
中文符号免干扰输入
在HBuilderX里写json,不用管输入法状态,如果光标位置应该是半角符号,即使你按下全角符号也会自动变成半角。
当然在字符串里,按下全角符号不会被转换半角。
舒畅书写,不用分神,不用紧张。
其实中文符号免干扰输入是HBuilder多年来一直的亮点,不止是json,在html、js、css、vue里都支持中文符号免干扰输入。
我们深切体会中国程序员的痛苦,并动手做出改进。
回车时自动补行尾逗号
不用担心回车时什么时候该输入行尾逗号,什么时候不输入。
HBuilderX会自动识别是否需要逗号,并在回车时把缺失的逗号自动补齐。
保存时自动删除数组或键值对结尾的多余逗号
我们复制一段json时,经常把行尾的逗号也复制过来,但最后一行其实是不能用逗号的,还得记得手动删除。
HBuilderX在保存时会自动清理这些不合法的逗号,无需操心太多。
KeyValue代码块,像写excel那样写键值对
在js的json里敲kv,会出现KeyValue代码块,

回车后生成这样的键值对

此时敲完key的文字,然后按tab,就可以把光标自动转到value那里并选中value,然后继续敲value的内容即可。
不用再被敲冒号逗号打断,专注于写KeyValue内容,就像用excel。
注:此功能在纯json文件中不生效,仅在js中使用json时生效。
智能双击,快速选中数组或键值对
当我们想选中一段数组或键值对,不管是准备复制还是删除,过去都需要拖动。
而拖动选择其实是一个极其低效又损伤手的行为:按下食指鼠标或触摸板,不能松开继续拖动到结尾,这个过程缓慢且食指神经一直紧张。
HBuilderX提供了强大的智能双击来解决这个问题,具体在json中:
- 双击逗号左部,是选中逗号以前的键值对或数组
- 双击逗号右部,是选中逗号以后的键值对或数组
- 双击行尾,选中整行
- 双击括号内侧,选中括号内的内容
- 按下Alt同时双击括号内侧,选中括号内的内容(包含括号)
- 双击引号内侧,选中引号内的内容
- 按下Alt同时双击引号内侧,选中引号内的内容(包含引号)
了解更多智能双击,点HBuilderX的选择菜单。
所有双击都支持搭配Ctrl实现多选
HBuilderX完善的多光标支持让操作效率如虎添翼。快速重复插入
当你想重复插入一段键值对或数组时,最快捷的方式不是复制然后找新位置粘贴,而是使用快速重复插入功能。
windows上是Ctrl+Insert或Ctrl+Shift+r,mac上是Command+Shift+r。语法提示
很多js方法把多个参数合并为一个json对象,那么这些参数的语法提示怎么办?
HBuilderX也有完美的json参数语法提示支持。

如果参数里有回调函数,还可以在回车时自动生成匿名函数,如下:

多想业务,少为形式浪费时间,这是HBuilderX要帮助开发者做到的事。
另外某些特殊的配置文件,比如uni-app里的pages.json,也支持语法提示,以提升编程效率。
保存时自动校验语法
json和js的校验是HBuilderX内置的,都是在保存时会校验语法,每处错误会标记红色波浪线,按F4可跳转到下个错误。
掌握这些技巧,开启你的高效之旅!
> 本帖文档已集成到: hx产品文档
json是一种对计算机友好,对人不友好的文件格式。
以前都是服务器生成json,前端程序员很少手写json。
但现代前端开发里,json的应用范围越来越多,各种配置文件、js的export里,全是json,写起来让人倍感痛苦,遍地是坑。
比如半角符号错输成全角,比如少了逗号或结尾多了逗号,比如没有语法提示和代码块,比如键值对的选中和复制很低效...
HBuilderX提供了多项优化技巧,达到最好的json编辑体验。学会这些,效率翻倍!
中文符号免干扰输入
在HBuilderX里写json,不用管输入法状态,如果光标位置应该是半角符号,即使你按下全角符号也会自动变成半角。
当然在字符串里,按下全角符号不会被转换半角。
舒畅书写,不用分神,不用紧张。
其实中文符号免干扰输入是HBuilder多年来一直的亮点,不止是json,在html、js、css、vue里都支持中文符号免干扰输入。
我们深切体会中国程序员的痛苦,并动手做出改进。
回车时自动补行尾逗号
不用担心回车时什么时候该输入行尾逗号,什么时候不输入。
HBuilderX会自动识别是否需要逗号,并在回车时把缺失的逗号自动补齐。
保存时自动删除数组或键值对结尾的多余逗号
我们复制一段json时,经常把行尾的逗号也复制过来,但最后一行其实是不能用逗号的,还得记得手动删除。
HBuilderX在保存时会自动清理这些不合法的逗号,无需操心太多。
KeyValue代码块,像写excel那样写键值对
在js的json里敲kv,会出现KeyValue代码块,
回车后生成这样的键值对
此时敲完key的文字,然后按tab,就可以把光标自动转到value那里并选中value,然后继续敲value的内容即可。
不用再被敲冒号逗号打断,专注于写KeyValue内容,就像用excel。
注:此功能在纯json文件中不生效,仅在js中使用json时生效。
智能双击,快速选中数组或键值对
当我们想选中一段数组或键值对,不管是准备复制还是删除,过去都需要拖动。
而拖动选择其实是一个极其低效又损伤手的行为:按下食指鼠标或触摸板,不能松开继续拖动到结尾,这个过程缓慢且食指神经一直紧张。
HBuilderX提供了强大的智能双击来解决这个问题,具体在json中:
- 双击逗号左部,是选中逗号以前的键值对或数组
- 双击逗号右部,是选中逗号以后的键值对或数组
- 双击行尾,选中整行
- 双击括号内侧,选中括号内的内容
- 按下Alt同时双击括号内侧,选中括号内的内容(包含括号)
- 双击引号内侧,选中引号内的内容
- 按下Alt同时双击引号内侧,选中引号内的内容(包含引号)
了解更多智能双击,点HBuilderX的选择菜单。
所有双击都支持搭配Ctrl实现多选
HBuilderX完善的多光标支持让操作效率如虎添翼。快速重复插入
当你想重复插入一段键值对或数组时,最快捷的方式不是复制然后找新位置粘贴,而是使用快速重复插入功能。
windows上是Ctrl+Insert或Ctrl+Shift+r,mac上是Command+Shift+r。语法提示
很多js方法把多个参数合并为一个json对象,那么这些参数的语法提示怎么办?
HBuilderX也有完美的json参数语法提示支持。
如果参数里有回调函数,还可以在回车时自动生成匿名函数,如下:
多想业务,少为形式浪费时间,这是HBuilderX要帮助开发者做到的事。
另外某些特殊的配置文件,比如uni-app里的pages.json,也支持语法提示,以提升编程效率。
保存时自动校验语法
json和js的校验是HBuilderX内置的,都是在保存时会校验语法,每处错误会标记红色波浪线,按F4可跳转到下个错误。
掌握这些技巧,开启你的高效之旅!
收起阅读 »【分享】在 5+App 中监听“返回”按钮
5+App 中,以下情况均触发 backbutton 事件。
- Android 物理返回键
- 原生 titleNView 左上角的 backbutton
下面是一个监听 backbutton 的最简示例:
var plusReady = function (callback) {
if (window.plus) {
callback();
} else {
document.addEventListener('plusready', callback);
}
};
plusReady(function () {
var firstBack = 0;
var handleBack = function () {
var currentWebview = plus.webview.currentWebview();
var topWebview = plus.webview.getTopWebview();
var now = Date.now || function () {
return new Date().getTime();
};
currentWebview.canBack(function (evt) {
/**
* 有可后退的历史记录,则后退。
* 否则,关闭当前窗口。
* 如果当前窗口是入口页,那么执行退出的逻辑。
*/
if (currentWebview.id === plus.runtime.appid) {
if (!firstBack) {
firstBack = now();
plus.nativeUI.toast('再按一次退出应用');
setTimeout(function () {
firstBack = 0;
}, 2000);
} else if (now() - firstBack < 2000) {
plus.runtime.quit();
}
} else {
if (evt.canBack) {
history.back();
} else {
currentWebview.close('auto');
}
}
});
};
plus.key.addEventListener('backbutton', handleBack);
});该示例适用于 C/S 结构的 5+App,并且每个窗口都加载这段 JS。
如果是 Vue.js 等构建的 SPA 页面,那么需要根据当前的路径信息,判定是后退还是退出,例如:
// 模式不同,需要取的值也不一样,这里仅做示例,非真实场景。
var path = location.path;
var hash = location.hash;
if (path === '/') {
// 入口页了,执行退出。
plus.runtime.quit();
} else {
// 根据实际需求选择相应的方法
router.go(-1);
history.back();
}参考文档
5+App 中,以下情况均触发 backbutton 事件。
- Android 物理返回键
- 原生 titleNView 左上角的 backbutton
下面是一个监听 backbutton 的最简示例:
var plusReady = function (callback) {
if (window.plus) {
callback();
} else {
document.addEventListener('plusready', callback);
}
};
plusReady(function () {
var firstBack = 0;
var handleBack = function () {
var currentWebview = plus.webview.currentWebview();
var topWebview = plus.webview.getTopWebview();
var now = Date.now || function () {
return new Date().getTime();
};
currentWebview.canBack(function (evt) {
/**
* 有可后退的历史记录,则后退。
* 否则,关闭当前窗口。
* 如果当前窗口是入口页,那么执行退出的逻辑。
*/
if (currentWebview.id === plus.runtime.appid) {
if (!firstBack) {
firstBack = now();
plus.nativeUI.toast('再按一次退出应用');
setTimeout(function () {
firstBack = 0;
}, 2000);
} else if (now() - firstBack < 2000) {
plus.runtime.quit();
}
} else {
if (evt.canBack) {
history.back();
} else {
currentWebview.close('auto');
}
}
});
};
plus.key.addEventListener('backbutton', handleBack);
});该示例适用于 C/S 结构的 5+App,并且每个窗口都加载这段 JS。
如果是 Vue.js 等构建的 SPA 页面,那么需要根据当前的路径信息,判定是后退还是退出,例如:
// 模式不同,需要取的值也不一样,这里仅做示例,非真实场景。
var path = location.path;
var hash = location.hash;
if (path === '/') {
// 入口页了,执行退出。
plus.runtime.quit();
} else {
// 根据实际需求选择相应的方法
router.go(-1);
history.back();
}参考文档
收起阅读 »
微信小程序开发简单吗?有些问题需要知道
对于开发微信小程序来说,很多投资者关注的重点方面要么是价格,要么是质量,不过不管是哪一方面,其实都是和一家好的微信小程序开发公司分布开的,但是对于以后小程序能不能盈利,就需要投资者在开发的时候,避免出现一些问题才行,那么企业想要做微信小程序,需要注意哪些问题呢?下面就跟大家分析解答一下吧。
1、一些软件公司利用低价吸引客户,软件系统不稳定。随着市场上软件开发公司数量越来越多,竞争越来越激烈,于是不少软件公司就打起了价格战。有个别公司竟然打出极低价格包干的宣传口号,这种明显低于市场价的肯定是不可相信的。因为这样的软件开发公司做出来的小程序或软件系统要么是不能满足功能需求的,要么是不稳定的,也就是质量不过关。因为开发一套系统软件是一项复杂的工作,即便对于专业的软件开发公司来说,要花费的人力成本、时间成本等都是很明显的,如果软件报价过低,开发出来的小程序质量可想而知。如果做出来的小程序不能满足您的需求,那么再少的钱也是浪费。
2、搞清楚软件开发公司为您提供的是否是小程序模板。当前市场上有不少第三方平台,大力宣传说自己开发的小程序性价比非常高,号称只要使用这套模板,自己就能根据需求简单设置好自己的微信小程序,价格比市场上其他小程序类低得多。对于没有软件系统开发技术的企业来说很有吸引力,一方面价格不高可以接受,另一方面自己简单操作就能实现功能需求。这里启动科技提醒您的是,很多这样的软件公司,以小程序模板少收费或免费,而代管或维护费非常高,因此对企业来说,实际上是被软件公司间接控制,以后如要调整模板或修改部分功能等,需要支付更高的费用。
3、要警惕小程序开发的另一个陷阱,也就是高价开发却为开发公司作嫁衣。不少小程序开发公司,自己先组建了一个框架平台,然后找其他客户入驻自己的平台后台。这样的小程序,从表面上看不出来有什么异样,实际上是缺乏完整性的,其不能离开开发公司母体而单独开发,也就是说,企业高价开发的微信小程序,只是嫁接在别人的主程序上,所有权并不归自己。
当下,微信小程序开发如此火,要做好小程序开发必须要注意以上讲到的三点。近两年,移动应用开发广受欢迎,特别是微信小程序发展势头非常快,小程序开发需求量大幅增加。不少企业、政府单位等都着手微信小程序开发,也正是在这一形势下,找到一家专业有实力且可靠的软件开发公司是多么的重要。信息来源由微信小程序开发公司燚轩科技整理编辑,如需转载,请注明出处。
对于开发微信小程序来说,很多投资者关注的重点方面要么是价格,要么是质量,不过不管是哪一方面,其实都是和一家好的微信小程序开发公司分布开的,但是对于以后小程序能不能盈利,就需要投资者在开发的时候,避免出现一些问题才行,那么企业想要做微信小程序,需要注意哪些问题呢?下面就跟大家分析解答一下吧。
1、一些软件公司利用低价吸引客户,软件系统不稳定。随着市场上软件开发公司数量越来越多,竞争越来越激烈,于是不少软件公司就打起了价格战。有个别公司竟然打出极低价格包干的宣传口号,这种明显低于市场价的肯定是不可相信的。因为这样的软件开发公司做出来的小程序或软件系统要么是不能满足功能需求的,要么是不稳定的,也就是质量不过关。因为开发一套系统软件是一项复杂的工作,即便对于专业的软件开发公司来说,要花费的人力成本、时间成本等都是很明显的,如果软件报价过低,开发出来的小程序质量可想而知。如果做出来的小程序不能满足您的需求,那么再少的钱也是浪费。
2、搞清楚软件开发公司为您提供的是否是小程序模板。当前市场上有不少第三方平台,大力宣传说自己开发的小程序性价比非常高,号称只要使用这套模板,自己就能根据需求简单设置好自己的微信小程序,价格比市场上其他小程序类低得多。对于没有软件系统开发技术的企业来说很有吸引力,一方面价格不高可以接受,另一方面自己简单操作就能实现功能需求。这里启动科技提醒您的是,很多这样的软件公司,以小程序模板少收费或免费,而代管或维护费非常高,因此对企业来说,实际上是被软件公司间接控制,以后如要调整模板或修改部分功能等,需要支付更高的费用。
3、要警惕小程序开发的另一个陷阱,也就是高价开发却为开发公司作嫁衣。不少小程序开发公司,自己先组建了一个框架平台,然后找其他客户入驻自己的平台后台。这样的小程序,从表面上看不出来有什么异样,实际上是缺乏完整性的,其不能离开开发公司母体而单独开发,也就是说,企业高价开发的微信小程序,只是嫁接在别人的主程序上,所有权并不归自己。
当下,微信小程序开发如此火,要做好小程序开发必须要注意以上讲到的三点。近两年,移动应用开发广受欢迎,特别是微信小程序发展势头非常快,小程序开发需求量大幅增加。不少企业、政府单位等都着手微信小程序开发,也正是在这一形势下,找到一家专业有实力且可靠的软件开发公司是多么的重要。信息来源由微信小程序开发公司燚轩科技整理编辑,如需转载,请注明出处。
收起阅读 »
slide(轮播组件)销毁
slide组件文档中只提及了最基础的部分,实际开发时下拉刷新时需要更新slide,这时就需要销毁slide。
网上资料和文档中都没有提及,在mui源码中找到了destroy()函数。
具体调用方法:gallery.slider().destroy();
slide组件文档中只提及了最基础的部分,实际开发时下拉刷新时需要更新slide,这时就需要销毁slide。
网上资料和文档中都没有提及,在mui源码中找到了destroy()函数。
具体调用方法:gallery.slider().destroy();
