





HBuilderX: 底部控制台,右键菜单,支持自定义快捷键 (2.8.0+起)
HBuilderX 2.8.0+版本起,底部控制台,右键菜单,相关操作支持自定义快捷键
如下图所示:

如何自定义快捷键?
点击菜单【工具】【自定义快捷键】,将下列代码拷贝到【用户设置】中。
[
// 底部控制台: 清空控制台
{
"key": "ctrl+shift+1",
"command": "workbench.console.action.clearLog"
},
// 底部控制台: 锁定滚动条
{
"key": "ctrl+shift+2",
"command": "workbench.console.action.lock"
},
// 底部控制台: 全选
{
"key": "ctrl+shift+3",
"command": "workbench.console.action.selectAll"
},
// 底部控制台: 复制
{
"key": "ctrl+shift+4",
"command": "workbench.console.action.copy"
}
]HBuilderX 2.8.0+版本起,底部控制台,右键菜单,相关操作支持自定义快捷键
如下图所示:
如何自定义快捷键?
点击菜单【工具】【自定义快捷键】,将下列代码拷贝到【用户设置】中。
[
// 底部控制台: 清空控制台
{
"key": "ctrl+shift+1",
"command": "workbench.console.action.clearLog"
},
// 底部控制台: 锁定滚动条
{
"key": "ctrl+shift+2",
"command": "workbench.console.action.lock"
},
// 底部控制台: 全选
{
"key": "ctrl+shift+3",
"command": "workbench.console.action.selectAll"
},
// 底部控制台: 复制
{
"key": "ctrl+shift+4",
"command": "workbench.console.action.copy"
}
]出售基于UNIAPP开发的淘宝客APP
该淘客项目基于uniapp nvue开发,体验可达到原生效果(目前市面上很多都是apiCloud 以及 uniapp vue开发的 体验不如nvue流畅),运行流畅。可上架IOS(我自己提交一次过审)
支持IOS13 apple登录、微信登录 获取本机手机号直接登录。
部分页面截图如下:




安卓以及IOS下载地址:https://m3w.cn/cst
付费出售,整包源码打包出售,淘客京东拼多多跟单使用python跟单。可实现1分钟内订单同步到数据库。
后台使用thinkphp5.1
客户端使用 uniapp for nvue
跟单使用python完成。
带 vue h5源码。(因为有部分H5活动页面)
价格 大于 一万。非诚勿扰。
该淘客项目基于uniapp nvue开发,体验可达到原生效果(目前市面上很多都是apiCloud 以及 uniapp vue开发的 体验不如nvue流畅),运行流畅。可上架IOS(我自己提交一次过审)
支持IOS13 apple登录、微信登录 获取本机手机号直接登录。
部分页面截图如下:
安卓以及IOS下载地址:https://m3w.cn/cst
付费出售,整包源码打包出售,淘客京东拼多多跟单使用python跟单。可实现1分钟内订单同步到数据库。
后台使用thinkphp5.1
客户端使用 uniapp for nvue
跟单使用python完成。
带 vue h5源码。(因为有部分H5活动页面)
价格 大于 一万。非诚勿扰。
收起阅读 »CSS 格式化 一行一条 - 2020-06-29
在之前的版本中,参照着 https://ask.dcloud.net.cn/article/628 成功的将css代码修改成了一行,但某次更新后发现又不可以了,好像更新了 beautifier.js 版本
网上有很多写有方法修改的,但有些总是不尽人意,有些真是有些老的方法了
这次在标题中写明日期,注意看哈
先看效果:
```css
@charset "utf-8";
/* CSS Document */
.help_nav {width: 970px;margin: auto;height: 30px;padding-top: 5px;line-height: 30px;color: #555555;}
.help_nav label {color: #999999;}
.main {width: 970px;margin: auto;}
.list_l {width: 715px;float: left;border: 1px solid #dadada;margin-bottom: 20px;}
```
解决方法: 1..............................................................
工具 > 插件配置 > format > jsbeautifyrc.js
module.exports = {
parsers: {
...
},
options: {
"css": {
"newline_between_rules": false,
"selector_separator_newline": false,
"preserve_newlines": false
} }
}
2..............................................................
修改文件:\HBuilderX\plugins\format\node_modules\js-beautify\js\src\css\beautifier.js
比较推荐的方法是注释掉
注释掉:
295行
298行
369行
代码都一样:this._output.add_new_line();
3..............................................................
先Ctrl + A 全选,再Ctrl + Shift + K将代码压缩成一行
再Ctrl + K 后查看效果
有什么疑问,下方留言喽
在之前的版本中,参照着 https://ask.dcloud.net.cn/article/628 成功的将css代码修改成了一行,但某次更新后发现又不可以了,好像更新了 beautifier.js 版本
网上有很多写有方法修改的,但有些总是不尽人意,有些真是有些老的方法了
这次在标题中写明日期,注意看哈
先看效果:
```css
@charset "utf-8";
/* CSS Document */
.help_nav {width: 970px;margin: auto;height: 30px;padding-top: 5px;line-height: 30px;color: #555555;}
.help_nav label {color: #999999;}
.main {width: 970px;margin: auto;}
.list_l {width: 715px;float: left;border: 1px solid #dadada;margin-bottom: 20px;}
```
解决方法: 1..............................................................
工具 > 插件配置 > format > jsbeautifyrc.js
module.exports = {
parsers: {
...
},
options: {
"css": {
"newline_between_rules": false,
"selector_separator_newline": false,
"preserve_newlines": false
} }
}
2..............................................................
修改文件:\HBuilderX\plugins\format\node_modules\js-beautify\js\src\css\beautifier.js
比较推荐的方法是注释掉
注释掉:
295行
298行
369行
代码都一样:this._output.add_new_line();
3..............................................................
先Ctrl + A 全选,再Ctrl + Shift + K将代码压缩成一行
再Ctrl + K 后查看效果
有什么疑问,下方留言喽
收起阅读 »
iOS平台自定义storyboard启动界面
背景
6月30日起,苹果App Store审核要求应用在启动时,不能使用启动图片,必须改为使用Storyboard来制作启动界面。原文参考:https://developer.apple.com/news/?id=03262020b
之前使用静态png图片做启动屏的方式,最大的问题是多尺寸适配,iOS设备目前不同屏幕尺寸太多,为每种屏幕做png图片不是合理解决方案。
Android处理多屏适配问题使用了.9.png,iOS则使用了Storyboard来处理。
什么是Storyboard
Storyboard是Apple提供的一种简化的布局界面,通过xml描述界面,不能编程。
虽然无法制作非常灵活的界面,但满足启动界面是没问题的,比如设定背景色背景图、设定前景文字、图片的位置。
storyboard的优势是启动速度快。在App的真实首页被渲染完成前,可以快速给用户提供一个基于Storyboard的启动屏。
其实5+App、wap2app、uni-app在iOS上,已经在两种情况下使用了Storyboard:
- 如果在manifest里没有选择自定义启动图片,那么默认情况下,打包后App启动时,会出现一个显示着app logo和name的通用启动界面。在iOS上,其实这个界面就是使用Storyboard实现的。
- 如果你的App启用了uni-AD广告服务,那么开屏广告界面,iOS上也是基于Storyboard实现的。
6月30日起,如上线Appstore,iOS只能使用Storyboard做启动图。如果你不想自己做Storyboard文件,就选择上述2种方式。
如果想自定义Storyboard,那么从HBuilderX 2.8起,也提供了自定义storyboard的方式。
如何自定义storyboard
HBuilderX2.8+版本开始支持配置自定义storyboard启动界面。
概要流程是:开发者首先制作storyboard文件,然后将storyboard文件和图片资源打包成zip,然后在HBuilderX 2.8+的项目manifest中选择这个zip,最后打包生效。
第一步:制作storyboard文件
storyboard有两种制作方式:
1. 直接使用附件提供的相对常用的 storyboard 模板,可在这个文件的基础上进行自定义(不需要 Mac 及 XCode,详情请查看附件中的 readme 教程)
此 storyboard 文件适用于各种 iPhone 及 iPad 设备的横竖屏,支持自定义界面元素包括
- 页面背景图片或背景颜色
- 中间显示图片
- 底部显示文字及颜色
注:每一项都是可选的(比如只显示背景图片,只提供背景图片即可)
2. 使用xcode自行制作。xcode提供了可视化的制作storyboard的方式,但依赖于mac电脑。在xcode中制作storyboard的教程请自行网络搜索,请注意下面的注意事项。
HBuilderX需要的自定义storyboard文件格式为zip压缩包,里面要求包含XCode使用的.storyboard文件,以及.stroybard文件中使用的png图,如下图所示:
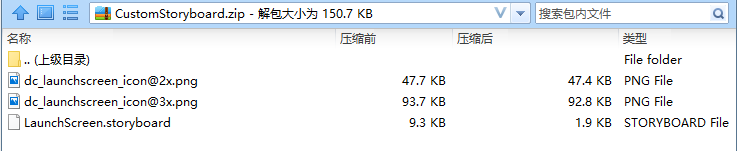
注意事项
- zip压缩包中不要包含目录,直接包含.storyboard和.png文件
- 有且只有一个.storyboard文件
- .storyboard文件可以通过xcode生成,也可以使用任何文本编辑器修改其源码,比如对.storyboard文件点右键,使用HBuilderX打开。它本质是一个xml文件。
- png文件名称中的@2x和@3x是适配不同分辨率的图片,系统会自动根据设备dpi选择,可参考这里
- 为了避免png文件名称与应用中内置的文件名冲突,建议以dc_launchscreen开头
- 制作 storyboard 时,请将图片资源直接拖到放工程中,不要放到 imageset 里面,并且图片命名要保证一定的唯一性可参考附件中的示例
- XCode中创建 storyboard 文件时,页面元素添加约束时一定要相对于
Superview,不然启动图到 loading页面过渡时页面会跳动或者变形

第二步:在HBuilderX的manifest界面中选择 自定义storyboard文件包。
把制作好的storyboard的zip包放置到硬盘中。
HBuilderX中打开项目的manifest.json文件,在“App启动界面配置”页面中勾选“自定义storyboard启动界面”,并选择自定义storyboard的zip包:
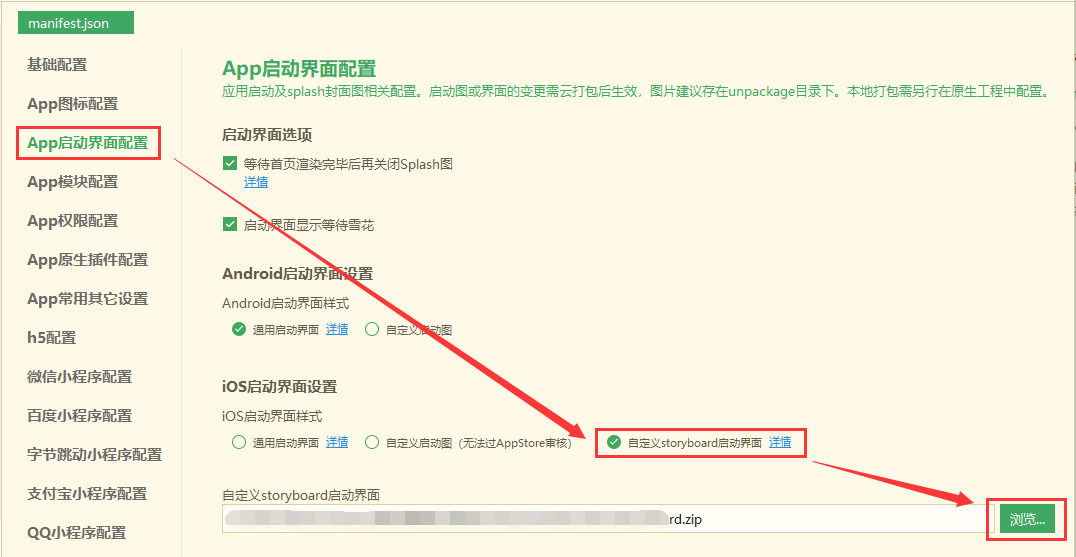
配置后需提交云端打包才能生效
离线打包请参考:iOS平台配置应用启动界面
附件说明
附件CustomStoryboard.zip为自定义sotyboard模板示例,默认效果如下:

此 storyboard 文件适用于各种 iPhone 及 iPad 设备的横竖屏,支持自定义界面元素包括
- 页面背景图片或背景颜色
- 中间显示图片
- 底部显示文字及颜色
注:每一项都是可选的(比如只显示背景图片,按照附件zip文件中的 readme.md 教程进行自定义修改,只提供背景图片即可)
后续
为iOS和Android制作不同的屏幕适配方案,还是比较麻烦。
而通用启动界面虽然双端均支持,且可以上Appstore,但自定义性不足。
后续DCloud会强化通用启动界面的灵活度,允许对背景、前景提供更多自定义性,并确保在iOS、Android双端均支持。
暂时,开发者如觉得自定义storyboard启动界面配置麻烦,也可以在manifest的启动图设置中选择默认的通用启动界面(或在HBuilderX2.8以前的版本删除启动图片配置),也满足App Store审核要求。
温馨提示:请勿在本贴下频繁刷广告,一经发现,直接封号。
附件下载:
背景
6月30日起,苹果App Store审核要求应用在启动时,不能使用启动图片,必须改为使用Storyboard来制作启动界面。原文参考:https://developer.apple.com/news/?id=03262020b
之前使用静态png图片做启动屏的方式,最大的问题是多尺寸适配,iOS设备目前不同屏幕尺寸太多,为每种屏幕做png图片不是合理解决方案。
Android处理多屏适配问题使用了.9.png,iOS则使用了Storyboard来处理。
什么是Storyboard
Storyboard是Apple提供的一种简化的布局界面,通过xml描述界面,不能编程。
虽然无法制作非常灵活的界面,但满足启动界面是没问题的,比如设定背景色背景图、设定前景文字、图片的位置。
storyboard的优势是启动速度快。在App的真实首页被渲染完成前,可以快速给用户提供一个基于Storyboard的启动屏。
其实5+App、wap2app、uni-app在iOS上,已经在两种情况下使用了Storyboard:
- 如果在manifest里没有选择自定义启动图片,那么默认情况下,打包后App启动时,会出现一个显示着app logo和name的通用启动界面。在iOS上,其实这个界面就是使用Storyboard实现的。
- 如果你的App启用了uni-AD广告服务,那么开屏广告界面,iOS上也是基于Storyboard实现的。
6月30日起,如上线Appstore,iOS只能使用Storyboard做启动图。如果你不想自己做Storyboard文件,就选择上述2种方式。
如果想自定义Storyboard,那么从HBuilderX 2.8起,也提供了自定义storyboard的方式。
如何自定义storyboard
HBuilderX2.8+版本开始支持配置自定义storyboard启动界面。
概要流程是:开发者首先制作storyboard文件,然后将storyboard文件和图片资源打包成zip,然后在HBuilderX 2.8+的项目manifest中选择这个zip,最后打包生效。
第一步:制作storyboard文件
storyboard有两种制作方式:
1. 直接使用附件提供的相对常用的 storyboard 模板,可在这个文件的基础上进行自定义(不需要 Mac 及 XCode,详情请查看附件中的 readme 教程)
此 storyboard 文件适用于各种 iPhone 及 iPad 设备的横竖屏,支持自定义界面元素包括
- 页面背景图片或背景颜色
- 中间显示图片
- 底部显示文字及颜色
注:每一项都是可选的(比如只显示背景图片,只提供背景图片即可)
2. 使用xcode自行制作。xcode提供了可视化的制作storyboard的方式,但依赖于mac电脑。在xcode中制作storyboard的教程请自行网络搜索,请注意下面的注意事项。
HBuilderX需要的自定义storyboard文件格式为zip压缩包,里面要求包含XCode使用的.storyboard文件,以及.stroybard文件中使用的png图,如下图所示:
注意事项
- zip压缩包中不要包含目录,直接包含.storyboard和.png文件
- 有且只有一个.storyboard文件
- .storyboard文件可以通过xcode生成,也可以使用任何文本编辑器修改其源码,比如对.storyboard文件点右键,使用HBuilderX打开。它本质是一个xml文件。
- png文件名称中的@2x和@3x是适配不同分辨率的图片,系统会自动根据设备dpi选择,可参考这里
- 为了避免png文件名称与应用中内置的文件名冲突,建议以dc_launchscreen开头
- 制作 storyboard 时,请将图片资源直接拖到放工程中,不要放到 imageset 里面,并且图片命名要保证一定的唯一性可参考附件中的示例
- XCode中创建 storyboard 文件时,页面元素添加约束时一定要相对于
Superview,不然启动图到 loading页面过渡时页面会跳动或者变形
第二步:在HBuilderX的manifest界面中选择 自定义storyboard文件包。
把制作好的storyboard的zip包放置到硬盘中。
HBuilderX中打开项目的manifest.json文件,在“App启动界面配置”页面中勾选“自定义storyboard启动界面”,并选择自定义storyboard的zip包:
配置后需提交云端打包才能生效
离线打包请参考:iOS平台配置应用启动界面
附件说明
附件CustomStoryboard.zip为自定义sotyboard模板示例,默认效果如下:
此 storyboard 文件适用于各种 iPhone 及 iPad 设备的横竖屏,支持自定义界面元素包括
- 页面背景图片或背景颜色
- 中间显示图片
- 底部显示文字及颜色
注:每一项都是可选的(比如只显示背景图片,按照附件zip文件中的 readme.md 教程进行自定义修改,只提供背景图片即可)
后续
为iOS和Android制作不同的屏幕适配方案,还是比较麻烦。
而通用启动界面虽然双端均支持,且可以上Appstore,但自定义性不足。
后续DCloud会强化通用启动界面的灵活度,允许对背景、前景提供更多自定义性,并确保在iOS、Android双端均支持。
暂时,开发者如觉得自定义storyboard启动界面配置麻烦,也可以在manifest的启动图设置中选择默认的通用启动界面(或在HBuilderX2.8以前的版本删除启动图片配置),也满足App Store审核要求。
温馨提示:请勿在本贴下频繁刷广告,一经发现,直接封号。
附件下载:
收起阅读 »App通用启动界面配置说明
此文档将不再维护,请参考新文档:https://uniapp.dcloud.io/tutorial/app-splashscreen
App启动时,因为应用自动需要一定时间,为了避免用户等待白屏,手机OS提供了特殊的启动界面设计,让用户先看到一个简单的界面,然后该界面消失,正式进入应用。
这个界面,即被称为启动界面,也成称为 splash 或 lauch screen。
启动界面原本是一个静态png图片方式。随着移动设备屏幕的多样化,为了让每种屏幕启动时界面都不变形,开发者需要为越来越多的屏幕尺寸制作不同的图片。
这带来很多问题,包括制作复杂、app包体积增大等。
于是Android发明了.9.png方式、iOS发明了storyboard方式,来解决多屏幕尺寸适配问题。
苹果公司的政策更为强硬,从2020年6月30日起,不再接受使用图片作为启动界面,必须使用storyboard,否则无法提交Appstore。
DCloud的App,支持所有Android和iOS的启动界面方式。
同时为了降低门槛,简化开发者为不同手机制作不同启动界面的复杂性,DCloud还提供了通用启动界面,即本文要重点介绍的内容。
首先汇总下DCloud支持的所有启动界面方式:
| 不同启动界面 | 平台支持 | 特点 |
|---|---|---|
| 通用启动界面(即本文重点) | Android、iOS均支持。其中在iOS上通过storyboard实现 | 简单,自定义性弱、可适配不同屏幕 |
| 启动图片方式 | Android支持;iOS可以打包,但从2020年6月30日起,无法提交Appstore | 为了适配不同屏幕尺寸,需要做大量图片 |
| .9.png方式 | 仅Android支持 | 可适配不同屏幕 |
| 自定义storyboard方式 | 仅iOS支持。需HBuilderX2.8+ | 可适配不同屏幕 |
本文重点描述通用启动界面。其他方式,另行参考上表的链接。
通用启动界面是一种简单、可适配不同屏幕的启动界面。
它以app的logo、name为元素,自动生成适配不同屏幕尺寸、适配不同OS要求的启动界面。
通用启动界面有着最低的门槛,仅需要开发者为app在manifest里配好logo和name即可。并且符合任何应用商店的上线规范。它在iOS上就是通过storyboard实现的。
通用启动界面是为了方便开发者而设计的,它不具有很强的灵活性,如果开发者有较强的自定义需求,那么需要在Android上使用.9.png方式、iOS上使用自定义storyboard方式
同时DCloud会在后续适度强化通用启动界面的自定义性,适配更多常见场景。
通用启动界面的设置,在项目的manifest文件的app启动界面设置中。并且是新项目的默认设置,如果开发者未做过启动界面的任何设置,那么启动app时看到的就是通用启动界面。
注意:以下manifest配置需提交云端打包后才能生效
<a id="android" />
Android平台通用启动界面
不配置自定义启动图时,默认会显示通用启动界面,效果如下:

在界面上部显示应用图标(圆形裁剪,外围显示进度),图标下面为应用名称。
配置使用通用启动界面
HBuilderX中打开项目的manifest.json文件,在“App启动界面配置”页面中的“Android启动界面设置”项下勾选“通用启动界面”:

<a id="ios" />
iOS平台通用启动界面
通用启动界面使用storyboard实现,不配置自定义启动图时默认会使用通用启动界面,效果如下:

在界面上部显示应用图标(无裁剪),图标下面为应用名称。
如果应用开启适配暗黑模式/夜间模式/深色模式,则启动界面背景色会自动使用深色,文字颜色自动使用白色。
配置使用通用启动界面
HBuilderX中打开项目的manifest.json文件,在“App启动界面配置”页面中的“iOS启动界面设置”项下勾选“通用启动界面”:
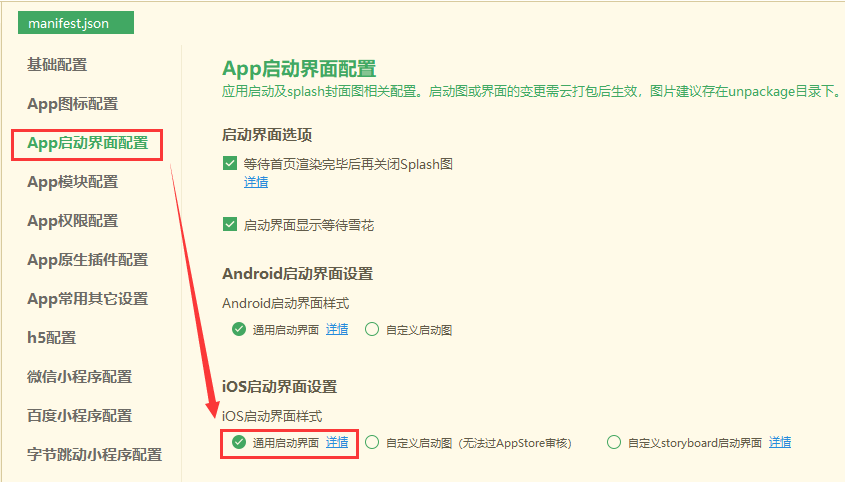
以上界面截图为HBuilderX2.8+。
更低版本的HBuilderX,也支持通用启动界面,只要不配置启动图片,就会按照通用启动界面方式执行。
但自定义storyboard方式仅HBuilderX2.8+才支持。
为满足Appstore强制要求storyboard,开发者可以:
- 使用
通用启动界面,此时任意HBuilderX均支持。 - 使用自定义storyboard启动界面,参考:https://ask.dcloud.net.cn/article/37475,此时需升级至HBuilderX2.8+。
此文档将不再维护,请参考新文档:https://uniapp.dcloud.io/tutorial/app-splashscreen
App启动时,因为应用自动需要一定时间,为了避免用户等待白屏,手机OS提供了特殊的启动界面设计,让用户先看到一个简单的界面,然后该界面消失,正式进入应用。
这个界面,即被称为启动界面,也成称为 splash 或 lauch screen。
启动界面原本是一个静态png图片方式。随着移动设备屏幕的多样化,为了让每种屏幕启动时界面都不变形,开发者需要为越来越多的屏幕尺寸制作不同的图片。
这带来很多问题,包括制作复杂、app包体积增大等。
于是Android发明了.9.png方式、iOS发明了storyboard方式,来解决多屏幕尺寸适配问题。
苹果公司的政策更为强硬,从2020年6月30日起,不再接受使用图片作为启动界面,必须使用storyboard,否则无法提交Appstore。
DCloud的App,支持所有Android和iOS的启动界面方式。
同时为了降低门槛,简化开发者为不同手机制作不同启动界面的复杂性,DCloud还提供了通用启动界面,即本文要重点介绍的内容。
首先汇总下DCloud支持的所有启动界面方式:
| 不同启动界面 | 平台支持 | 特点 |
|---|---|---|
| 通用启动界面(即本文重点) | Android、iOS均支持。其中在iOS上通过storyboard实现 | 简单,自定义性弱、可适配不同屏幕 |
| 启动图片方式 | Android支持;iOS可以打包,但从2020年6月30日起,无法提交Appstore | 为了适配不同屏幕尺寸,需要做大量图片 |
| .9.png方式 | 仅Android支持 | 可适配不同屏幕 |
| 自定义storyboard方式 | 仅iOS支持。需HBuilderX2.8+ | 可适配不同屏幕 |
本文重点描述通用启动界面。其他方式,另行参考上表的链接。
通用启动界面是一种简单、可适配不同屏幕的启动界面。
它以app的logo、name为元素,自动生成适配不同屏幕尺寸、适配不同OS要求的启动界面。
通用启动界面有着最低的门槛,仅需要开发者为app在manifest里配好logo和name即可。并且符合任何应用商店的上线规范。它在iOS上就是通过storyboard实现的。
通用启动界面是为了方便开发者而设计的,它不具有很强的灵活性,如果开发者有较强的自定义需求,那么需要在Android上使用.9.png方式、iOS上使用自定义storyboard方式
同时DCloud会在后续适度强化通用启动界面的自定义性,适配更多常见场景。
通用启动界面的设置,在项目的manifest文件的app启动界面设置中。并且是新项目的默认设置,如果开发者未做过启动界面的任何设置,那么启动app时看到的就是通用启动界面。
注意:以下manifest配置需提交云端打包后才能生效
<a id="android" />
Android平台通用启动界面
不配置自定义启动图时,默认会显示通用启动界面,效果如下:
在界面上部显示应用图标(圆形裁剪,外围显示进度),图标下面为应用名称。
配置使用通用启动界面
HBuilderX中打开项目的manifest.json文件,在“App启动界面配置”页面中的“Android启动界面设置”项下勾选“通用启动界面”:
<a id="ios" />
iOS平台通用启动界面
通用启动界面使用storyboard实现,不配置自定义启动图时默认会使用通用启动界面,效果如下:
在界面上部显示应用图标(无裁剪),图标下面为应用名称。
如果应用开启适配暗黑模式/夜间模式/深色模式,则启动界面背景色会自动使用深色,文字颜色自动使用白色。
配置使用通用启动界面
HBuilderX中打开项目的manifest.json文件,在“App启动界面配置”页面中的“iOS启动界面设置”项下勾选“通用启动界面”:
以上界面截图为HBuilderX2.8+。
更低版本的HBuilderX,也支持通用启动界面,只要不配置启动图片,就会按照通用启动界面方式执行。
但自定义storyboard方式仅HBuilderX2.8+才支持。
为满足Appstore强制要求storyboard,开发者可以:
- 使用
通用启动界面,此时任意HBuilderX均支持。 - 使用自定义storyboard启动界面,参考:https://ask.dcloud.net.cn/article/37475,此时需升级至HBuilderX2.8+。
分享一下关于IOS上架UIWebView机审问题相关处理方式
因为公司使用的是离线打包方式
所以下载的是官方的IOS 离线打包环境
不清楚是因为未更新还是什么,反正最新的SDK包是过不了机审的,必定会提示要你不能使用UIWebView
所以我们的做法是必须去除一切有关UIWebVIew的插件和代码
找了几天 翻遍论坛,试了几个方法后 终于成功过机审并成功上架第一个版本
在此分享下自己的两个做法,不一定有用,也不清楚是因为哪个有用
MiPassport.framework,QHADSDK.framework,qucFrameWorkAll.framework,还有Google开头的几个库,这几个库不能用,要去掉引用
此处要感谢官方 DCloud_IOS_CLP 感谢他的热心回复
另外 还有一个
cd到项目Libs根目录
执行下面语句
find . -type f | grep -e ".a" -e ".framework" | xargs grep -s UIWebView
反正不知道是哪个有用 至少两个试完我成功了。
关键点:不管是库还是插件,都不能有UIWebView相关!!!!!!!!!!!!
因为公司使用的是离线打包方式
所以下载的是官方的IOS 离线打包环境
不清楚是因为未更新还是什么,反正最新的SDK包是过不了机审的,必定会提示要你不能使用UIWebView
所以我们的做法是必须去除一切有关UIWebVIew的插件和代码
找了几天 翻遍论坛,试了几个方法后 终于成功过机审并成功上架第一个版本
在此分享下自己的两个做法,不一定有用,也不清楚是因为哪个有用
MiPassport.framework,QHADSDK.framework,qucFrameWorkAll.framework,还有Google开头的几个库,这几个库不能用,要去掉引用
此处要感谢官方 DCloud_IOS_CLP 感谢他的热心回复
另外 还有一个
cd到项目Libs根目录
执行下面语句
find . -type f | grep -e ".a" -e ".framework" | xargs grep -s UIWebView
反正不知道是哪个有用 至少两个试完我成功了。
关键点:不管是库还是插件,都不能有UIWebView相关!!!!!!!!!!!!
收起阅读 »
uniapp 删除 main.js 的 App.mpType = 'app' 后运行 H5 报错 Cannot read property 'meta' of undefined
前因
当前代码构建微信小程序可正常运行,但是无法运行H5,运行起来提示如下错误
chunk-vendors.js:4427 [Vue warn]: Property or method "keepAliveInclude" is not defined on the instance but referenced during render. Make sure that this property is
chunk-vendors.js:4427 [Vue warn]: Error in render: "TypeError: Cannot read property 'meta' of undefined"刚接触 uniapp,搜了一圈错误信息也没有找到问题所在,于是新建demo组个文件对比发现是 main.js 中我把 App.mpType = 'app' 删除了导致的。
后果
补齐main.js 的 App.mpType = 'app' 即可。
找到原因还是花费了一些时间,故记录一二,以便后者搜索错误提示就可以找到问题~
关于 App.mpType = 'app' 所能找到的说明
小程序页面组件和这个 App.vue 组件的写法和引入方式是一致的,为了区分两者,需要设置mpType值
前因
当前代码构建微信小程序可正常运行,但是无法运行H5,运行起来提示如下错误
chunk-vendors.js:4427 [Vue warn]: Property or method "keepAliveInclude" is not defined on the instance but referenced during render. Make sure that this property is
chunk-vendors.js:4427 [Vue warn]: Error in render: "TypeError: Cannot read property 'meta' of undefined"刚接触 uniapp,搜了一圈错误信息也没有找到问题所在,于是新建demo组个文件对比发现是 main.js 中我把 App.mpType = 'app' 删除了导致的。
后果
补齐main.js 的 App.mpType = 'app' 即可。
找到原因还是花费了一些时间,故记录一二,以便后者搜索错误提示就可以找到问题~
关于 App.mpType = 'app' 所能找到的说明
收起阅读 »小程序页面组件和这个 App.vue 组件的写法和引入方式是一致的,为了区分两者,需要设置mpType值
解耦 pages.json 模块化输出 解决方案
uni-merge-pages
之前有写这样一个库,通过读取 pages.json 文件内容中的 pages、subPackages 选项作为 uni-simple-router 的路由表,再借助 webpack 注入全局变量,完成一些列的操作。然而 此库刚好相反,它可以让你编写 js 模块文件 自动完成 pages.json 写入。妈妈再也不用担心配置混乱的问题啦。上手难度一颗星 阅读完安装后直接[跳入注意事项即可]()
飞机直达
安装
您可以使用 Yarn 或 npm 安装该软件包(选择一个):
Yarn
yarn global add uni-merge-pages nodemonnpm
npm install uni-merge-pages nodemon -g注意事项
- 使用之前请把
pages.json中的所有内容备份到其他文件,避免覆盖文件。HBuilder X创建页面时,即使勾选在 pages.json 中注册也同样无效。插件只认模块化输出的产物。 - 模块化js必须在结尾使用
;这样才能通知到插件更准确的捕捉。 - 目标捕捉内容默认是
const声明,大写变量 包括:PAGES、GLOBALSTYLE、EASYCOM、TABBAR、CONDITION、SUBPACKAGES、PRELOADRULE、PAGESOTHER - 禁止在对象最后一对
key/value后 使用注释,如果需要注释请移步到key/value头部上 - 插件默认包含提取内容仅有7个,
workers默认是没包含的,如果需要写入到pages.json请使用PAGESOTHER包含 pages.json禁止手动往里面添加内容,因为下次热更直接会覆盖。请在模块js下添加。
开始使用
第一步:配置 uni.config.js 文件
在项目根目录或者任何地方新建一个 uni.config.js 文件,简单的配置一下。提供一些必要的选项即可。
// uni.config.js
const {resolve}=require('path');
module.exports = {
publicPath:'', //预设一个公共路径
nodemon:{
watch:[ //监听当前项目根目录下的config文件目录 包括所有文件 默认只提取js文件
resolve(__dirname, './config/*'),
],
}
}以上示例是在当前项目根目录下,如果你是新建在其他地方。那请修改 watch 路径,记住是 绝对路径。然后再通过 cli 传递 --config xxx/xxx/uni-config.js 路径即可。默认读取项目根目录下的 uni-config.js
还想更细腻一点的配置?安排
// uni.config.js
const {resolve}=require('path');
module.exports = {
publicPath:'',
//只提取 这三个文件中的内容作为 pages.json 中的写入物 记住绝对路径 像下面这样
includes: [
resolve(__dirname,'./config/pages.js'),
resolve(__dirname,'./config/tabbar.js'),
],
//插件提取完成后 会通知你 你可以进一步修改内容 并返回给你 插件 记住一定要 next
transformHook:function(pagesStr,extractStr,next){
next(extractStr);
},
nodemon:{
watch:[
resolve(__dirname, './config/*'),
],
// 显示更详细的日志
verbose: true,
}
}第二步:预设执行脚本
有两种方式实现:
第一种在当前项目根目录下执行 npm init -y 编写 scripts 脚本即可
{
"name": "xxxxxx",
"version": "1.0.0",
"description": "",
"main": "main.js",
"dependencies": {},
"devDependencies": {},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build:pages": "uni-merge-cli"
},
"keywords": [],
"author": "",
"license": "ISC"
}需要使用时执行 npm run build:pages 即可。
第二种直接打开 dos cd 到项目根路径下 执行 uni-merge-cli 即可。
第三步:编写默认提取物文件代码
//config/pages.js
const PAGES = [
// #ifdef APP-NVUE
{
path: "pages/index33/index333",
name:'index33'
},
// #endif
{
"path": "index2/index2",
"style": {
"navigationBarTitleText": "uni-app",
}
},
];
export default PAGES;
//config/tabbar.js
const TABBAR = {
"color": "#7A7E83",
"selectedColor": "#3cc51f",
"borderStyle": "black",
"backgroundColor": "#f00",
"list": [{
"pagePath": "pages/component/index",
"iconPath": "static/image/icon_component.png",
"selectedIconPath": "static/image/icon_component_HL.png",
"text": "组件"
}, {
"pagePath": "pages/API/index",
"iconPath": "static/image/icon_API.png",
"selectedIconPath": "static/image/icon_API_HL.png",
"text": "接口"
}]
};
export default TABBAR;如果你没有预设 uni-config.js 中的 rule。请按照上面的配置进行编写,大写声明法 记住在一个声明完成的对象后面加上 ; 以便于插件精准提取。 如果不习惯这样的写法 你可以自己编写 rule 正则来提取即可。 在每个对象最后一个key/value后禁止使用注释,请移步到头部注释
额外参数写入到 pages.json
因为插件默认只有 7 个提取物。 包括:globalStyle、pages、easycom、tabBar、condition、subPackages、preloadRule。而 workers 是没有包含在内的。如果你想写入多个插件没包含的提取物进去,可以这样做。
// xxxx/config/other.js
const PAGESOTHER= {
workers:'workers',
otherConfig:{
name:'hhyang'
}
};默认插件会把 PAGESOTHER 下声明的所有扁平成一个对象,平级的写入到pages.json 中
默认配置项
uni-config.js 中的配置最后会和默认配置进行合并,你可以在 uni-config.js 中编写任何你想要的代码
module.exports={
//预设在 pages 节点下 path 的公共路径
publicPath:'',
// 需要监听的文件目录下所包含的js文件 必须绝对路径 空则读取监听目录下的所有文件
includes: [],
// 提取文件内容的正则规则
rule: {
globalStyle: /(?<=const\s+GLOBALSTYLE\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
pages: /(?<=const\s+PAGES\s*=\s*)\[[\s\S]*?](?=\s*;)/,
easycom: /(?<=const\s+EASYCOM\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
tabBar: /(?<=const\s+TABBAR\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
condition: /(?<=const\s+CONDITION\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
subPackages: /(?<=const\s+SUBPACKAGES\s*=\s*)\[[\s\S]*?](?=\s*;)/,
preloadRule: /(?<=const\s+PRELOADRULE\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
pagesother:/(?<=const\s+PAGESOTHER\s*=\s*)\{[\s\S]*?}(?=\s*;)/
},
// 这些是 nodemon 的所有配置
nodemon:{
"verbose": false,
"execMap": {
"js": "node --harmony"
},
"restartable": "rs",
"ignore": [".git", "node_modules/*"],
"env": {
"NODE_ENV": "production"
},
"ext": "js"
}
}uni-merge-pages
之前有写这样一个库,通过读取 pages.json 文件内容中的 pages、subPackages 选项作为 uni-simple-router 的路由表,再借助 webpack 注入全局变量,完成一些列的操作。然而 此库刚好相反,它可以让你编写 js 模块文件 自动完成 pages.json 写入。妈妈再也不用担心配置混乱的问题啦。上手难度一颗星 阅读完安装后直接[跳入注意事项即可]()
飞机直达
安装
您可以使用 Yarn 或 npm 安装该软件包(选择一个):
Yarn
yarn global add uni-merge-pages nodemonnpm
npm install uni-merge-pages nodemon -g注意事项
- 使用之前请把
pages.json中的所有内容备份到其他文件,避免覆盖文件。HBuilder X创建页面时,即使勾选在 pages.json 中注册也同样无效。插件只认模块化输出的产物。 - 模块化js必须在结尾使用
;这样才能通知到插件更准确的捕捉。 - 目标捕捉内容默认是
const声明,大写变量 包括:PAGES、GLOBALSTYLE、EASYCOM、TABBAR、CONDITION、SUBPACKAGES、PRELOADRULE、PAGESOTHER - 禁止在对象最后一对
key/value后 使用注释,如果需要注释请移步到key/value头部上 - 插件默认包含提取内容仅有7个,
workers默认是没包含的,如果需要写入到pages.json请使用PAGESOTHER包含 pages.json禁止手动往里面添加内容,因为下次热更直接会覆盖。请在模块js下添加。
开始使用
第一步:配置 uni.config.js 文件
在项目根目录或者任何地方新建一个 uni.config.js 文件,简单的配置一下。提供一些必要的选项即可。
// uni.config.js
const {resolve}=require('path');
module.exports = {
publicPath:'', //预设一个公共路径
nodemon:{
watch:[ //监听当前项目根目录下的config文件目录 包括所有文件 默认只提取js文件
resolve(__dirname, './config/*'),
],
}
}以上示例是在当前项目根目录下,如果你是新建在其他地方。那请修改 watch 路径,记住是 绝对路径。然后再通过 cli 传递 --config xxx/xxx/uni-config.js 路径即可。默认读取项目根目录下的 uni-config.js
还想更细腻一点的配置?安排
// uni.config.js
const {resolve}=require('path');
module.exports = {
publicPath:'',
//只提取 这三个文件中的内容作为 pages.json 中的写入物 记住绝对路径 像下面这样
includes: [
resolve(__dirname,'./config/pages.js'),
resolve(__dirname,'./config/tabbar.js'),
],
//插件提取完成后 会通知你 你可以进一步修改内容 并返回给你 插件 记住一定要 next
transformHook:function(pagesStr,extractStr,next){
next(extractStr);
},
nodemon:{
watch:[
resolve(__dirname, './config/*'),
],
// 显示更详细的日志
verbose: true,
}
}第二步:预设执行脚本
有两种方式实现:
第一种在当前项目根目录下执行 npm init -y 编写 scripts 脚本即可
{
"name": "xxxxxx",
"version": "1.0.0",
"description": "",
"main": "main.js",
"dependencies": {},
"devDependencies": {},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build:pages": "uni-merge-cli"
},
"keywords": [],
"author": "",
"license": "ISC"
}需要使用时执行 npm run build:pages 即可。
第二种直接打开 dos cd 到项目根路径下 执行 uni-merge-cli 即可。
第三步:编写默认提取物文件代码
//config/pages.js
const PAGES = [
// #ifdef APP-NVUE
{
path: "pages/index33/index333",
name:'index33'
},
// #endif
{
"path": "index2/index2",
"style": {
"navigationBarTitleText": "uni-app",
}
},
];
export default PAGES;
//config/tabbar.js
const TABBAR = {
"color": "#7A7E83",
"selectedColor": "#3cc51f",
"borderStyle": "black",
"backgroundColor": "#f00",
"list": [{
"pagePath": "pages/component/index",
"iconPath": "static/image/icon_component.png",
"selectedIconPath": "static/image/icon_component_HL.png",
"text": "组件"
}, {
"pagePath": "pages/API/index",
"iconPath": "static/image/icon_API.png",
"selectedIconPath": "static/image/icon_API_HL.png",
"text": "接口"
}]
};
export default TABBAR;如果你没有预设 uni-config.js 中的 rule。请按照上面的配置进行编写,大写声明法 记住在一个声明完成的对象后面加上 ; 以便于插件精准提取。 如果不习惯这样的写法 你可以自己编写 rule 正则来提取即可。 在每个对象最后一个key/value后禁止使用注释,请移步到头部注释
额外参数写入到 pages.json
因为插件默认只有 7 个提取物。 包括:globalStyle、pages、easycom、tabBar、condition、subPackages、preloadRule。而 workers 是没有包含在内的。如果你想写入多个插件没包含的提取物进去,可以这样做。
// xxxx/config/other.js
const PAGESOTHER= {
workers:'workers',
otherConfig:{
name:'hhyang'
}
};默认插件会把 PAGESOTHER 下声明的所有扁平成一个对象,平级的写入到pages.json 中
默认配置项
uni-config.js 中的配置最后会和默认配置进行合并,你可以在 uni-config.js 中编写任何你想要的代码
module.exports={
//预设在 pages 节点下 path 的公共路径
publicPath:'',
// 需要监听的文件目录下所包含的js文件 必须绝对路径 空则读取监听目录下的所有文件
includes: [],
// 提取文件内容的正则规则
rule: {
globalStyle: /(?<=const\s+GLOBALSTYLE\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
pages: /(?<=const\s+PAGES\s*=\s*)\[[\s\S]*?](?=\s*;)/,
easycom: /(?<=const\s+EASYCOM\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
tabBar: /(?<=const\s+TABBAR\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
condition: /(?<=const\s+CONDITION\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
subPackages: /(?<=const\s+SUBPACKAGES\s*=\s*)\[[\s\S]*?](?=\s*;)/,
preloadRule: /(?<=const\s+PRELOADRULE\s*=\s*)\{[\s\S]*?}(?=\s*;)/,
pagesother:/(?<=const\s+PAGESOTHER\s*=\s*)\{[\s\S]*?}(?=\s*;)/
},
// 这些是 nodemon 的所有配置
nodemon:{
"verbose": false,
"execMap": {
"js": "node --harmony"
},
"restartable": "rs",
"ignore": [".git", "node_modules/*"],
"env": {
"NODE_ENV": "production"
},
"ext": "js"
}
}开发一款APP,价格私聊
开发一款APP,价格私聊,做蔬菜水果电商的APP,电13139501613,扣317450836,微anjungang007
开发一款APP,价格私聊,做蔬菜水果电商的APP,电13139501613,扣317450836,微anjungang007
