






UniAPP这些天使用心得
用uniApp有一段时间了,给我的第一感受是,第一次对程序开发失去了信心。
不知道是什么鬼才发明了这个东西,搞出来折磨人。
难用不说,经常是出一个错,你根本定位不到错误的位置,更奇葩的是,在游览器能显示正常的东西,在移动端就显示一片空白。
官方出的调试工具,竟然也能有bug,用有bug的调试工具去调试bug,真奇怪。
不得不说,开发uniAPP,真是一件令人沮丧的事,可惜我人微言轻,不能说服领导用flutter。
最后,我只想为我这些天掉的头发说一句,UniAPP,我可去你m的吧
用uniApp有一段时间了,给我的第一感受是,第一次对程序开发失去了信心。
不知道是什么鬼才发明了这个东西,搞出来折磨人。
难用不说,经常是出一个错,你根本定位不到错误的位置,更奇葩的是,在游览器能显示正常的东西,在移动端就显示一片空白。
官方出的调试工具,竟然也能有bug,用有bug的调试工具去调试bug,真奇怪。
不得不说,开发uniAPP,真是一件令人沮丧的事,可惜我人微言轻,不能说服领导用flutter。
最后,我只想为我这些天掉的头发说一句,UniAPP,我可去你m的吧
uniapp中使用sqlite对本地缓存下数据进行处理
先说下我决定用sqlite的条件:
主要是流程处理,需要在无网络的情况下实现,数据量多的时候用h5的缓存完全不够,在看了文档之后选择使用SQLite ,早起在mui的时候使用的indexDB;
因为在社区也没收到具体的,所以写下记录下也和小伙伴分享下,有啥问题可以互相交流下。
该文档中用到的两个点 (SQLite 和vue中的mixin)
我这有两个环境,我先说一个简单;
- 主页菜单进去 到列表界面 从该步骤开始缓存本地数据;
- 从列表点击进入到详情,并在详情操作。有网络正常,无网络时存入表中,当切换到有网情况后,进行提交;
使用SQLite时需要先开权限,在配置文件中,如下图
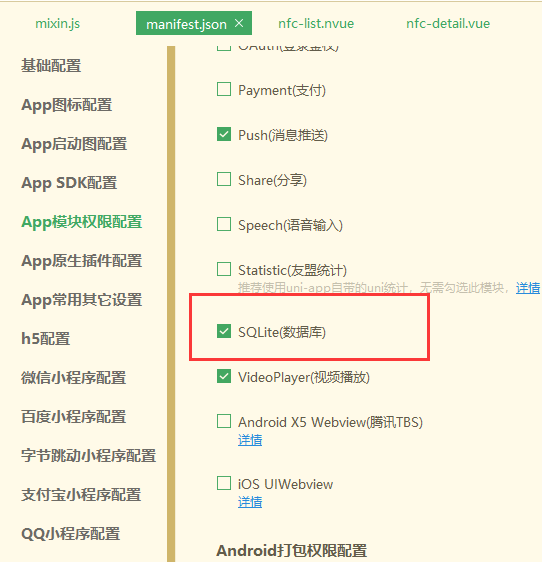
SQLite官方demo ; 在hbuilderX 下新建demo pages/API/sqlite/sqlite 下官方提供的sqlite使用。为了使用方便,我把需要的单独提出来;
该出贴出function 代码,不做具体说明;
function openComDB(name, path, callback) {
plus.sqlite.openDatabase({
name: name,
path: path,
success: function(e) {
// plus.nativeUI.alert('打开数据库成功');
callback(e)
},
fail: function(e) {
// plus.nativeUI.alert("打开数据库失败");
callback(e);
}
})
}
function executeSQL(name, sql, callback) {
plus.sqlite.selectSql({
name: name,
sql: sql,
success: function(e) {
// console.log("查询数据库:" + name + ",表:" + sql + ";的");
// console.log(JSON.stringify(e));
callback(e);
},
fail: function(e) {
console.log("查询数据库失败:" + JSON.stringify(e));
callback(e);
}
})
}
export{
openComDB,
executeSQL
}该出 进入正题;
在需要用到的vue文件下,引入上方function; 路径是自己的;
import {openComDB,executeSQL,dropSQL} from '../../common/env.js'说下简单的思路:
1.进入lists界面,先判断是否有网络,有网络正常调用,无网络时需要判断本地数据库中是否有数据,无数据则第一次进入。有数据需要调用本地数据中的数据;
ps
在有些uni使用上可能会和现在的有点出入,因为这个是早期写的NFC写入的功能,用的nvue的,还是weex的模式下。
贴上部分相关代码
created() {
this.getNetworkType(); //初始化网络当前状态;
uni.onNavigationBarButtonTap((e) => {
//该处是因为的导航栏右边加了两个筛选条件。可以忽略。 不过如果做离线需要筛选的,筛选条件等数据同样需要缓存
if (e.index == 1) {
this.pickType();
} else if (e.index == 0) {
this.pickBuild()
}
})
},
methods: {
getNetworkType() {
//获取网络信息
uni.getNetworkType({
success: res => {
this.netWork = res.networkType;
this.isOpenDB();
}
})
},
isOpenDB() {
console.log('是否打开数据库');
var isOpen = plus.sqlite.isOpenDatabase({
name: 'nfc', //数据库的名字
path: '_doc/nfcList.db' //地址
});
console.log(!isOpen);
if (!isOpen) {
console.log('Unoepned:' + isOpen);
// plus.nativeUI.alert('Unopened!');
this.openDB(); //打開DB
} else {
// plus.nativeUI.alert('Opened!');
this.isNet();
// this.getLocalType();
}
},
openDB() {
//SQLite
openComDB('nfc', '_doc/nfcList.db', res => {
console.log('打开数据库');
this.isNet();
});
},
isNet(){
//网络问题;
if (this.netWork == 'wifi' || this.netWork == '4g') {
//在有网络情况下,会先情况之前的表,为了防止没有及时更新到数据。update我是嫌麻烦,没这样写。就这样暴力写了。
console.log('wifi || 4g ');
this.dropTable("pointLists");
this.dropTable("codeTypeTable");
this.dropTable("codeTable");
this.dropTable("statusTable")
//删了之后创建表
this.createCodeTable();
this.createCodeTypeTable();
this.createBuildTable();
this.createLists();
this.createUpateStatus(); // 离线时更新
//然后把数据插入进去
this.getTabType(); //初始化格式
this.getPonitType(); //获取code。默认值
this.getCodeType(); // 类型下的选择项;
this.getBuilds(); // 获取建筑物数据
} else {
//无网络时;
console.log('初始化无网络');
this.getTabType(); //初始化格式
this.locCodeTypeItem();
this.selBuildFun();
}
//上面贴的drop,create,insert 我会在下面贴出部分代码。不会全部贴.SQL语句不会的建议百度找文档多看下,无非就是增删改查
},
}整个代码贴上太长了,我还是分段写吧;
本身就是个带tab类型的列表。延用nvue 的 weex的形式,未改成uniapp形式,如需参照此处tab,需要看之前的官方demo。 建议用官方新的uniapp模式,我是懒得改。
//初始化
getTabType() {
//初始化列表;
let ary = [];
for (let i = 0; i < this.tabBars.length; i++) {
let aryItem = {
loadingText: "",
data: [],
pageNum: 1
}
ary.push(aryItem);
}
this.newsitems = ary;
if(this.netWork == "wifi" || this.netWork == "4g"){
this.getPointList() //默认加载未处理; 有网络下,正常调用接口
}else{
this.selPointList() //无网络下调用数据库表中的数据;
}
},再有网络调用接口时需要将 数据insert到创建的数据表中;
创建数据库中的表
我的思路是整个app为一个数据库,有各种不同的表。 目前只有nfc中用到了,所以数据库的name 就取名 nfc 了,未进行修改;
现在正儿八经的创建表;
用简单的建筑信息为例;根据自己需要的进行创建表;
createBuildTable() {
//创建建筑物类型表;
var sqlTable = 'create table if not exists buildTable("id" INT(10) NOT NULL UNIQUE,"name" CHAR,"gridCode" CHAR)'
executeSQL('nfc', sqlTable, res => {})
},在有网调用接口时,insert 表;需要与上方创建的完全对应,最后一个不加 “,” 只有不对应就会报错
insertBuildCode() {
for (var i = 0; i < this.builds.length; i++) {
var sqlInsert = "insert into buildTable values('";
sqlInsert += this.builds[i].id + "','";
sqlInsert += this.builds[i].name + "','";
sqlInsert += this.builds[i].gridCode + "'";
sqlInsert += ')';
executeSQL('nfc', sqlInsert, res => {
})
}
this.getLocBuilds() //插入成功后,就可以查看结果。此处用到就直接赋值,没用到,或者别处用到,就在别处调用
},
getLocBuilds() {
executeSQL('nfc', 'select * from buildTable', res => {
console.log("建筑物查询结果");
this.builds = res;
this.selBuildFun()
})
},查看就这样,就写个简单的例子。列表数据比较多。就不放上。如果详情的数据是通过detailById 接口调用,list表的需要将详情的数据加进去。
当整个数据存上后,就是点击list跳转到detail界面。
detail正常的vue文件。
有网络时正常查看,进行提交操作。
无网络时,查看本地数据库的表。
所有创建和插入都是在list进行的,detail.vue中 进行 查看,和更改,如果需要删除 也可。 (因为在list就很有可能是无网络的情况,所以所有的数据都在列表获取到了)
list ---> detail
可以带id ,也可以带json、建议带唯一的id就可以了,可以在detail select 出需要的数据;
我这里是觉着数据已经在list存上了,detail不如直接使用,不管用网络无网络,本身做提交,后台也不会不停的改数据。
比较严谨的可以有网络时候调用详情接口,无网络时在本地查。
查询代码上面贴了列子此处就不放上了。
简单说一下离线提交。会用到VUE的mixin。
离线提交的思路 。在list的时候需要创建 提交的 表 locSubTable(随便起的名字方便后面提到) ,并在最后 加上 flag 字段 (这个自己随意) 类型INT 。因为没有布尔。所以在插入的时候需要用flag 0,1 进行判断是否需要缓存提交。
0 为 false 1 为 true ;
在detail 内,若 是离线时进行提交,在 locSubTable 进行insert 。最后flag 插入 为 0 ;
在无网络切换至 wifi/4g下,查询 locSubTable 表 where flag = 0 的数据。 返回的 res.length = 0 的时候,无离线提交。
ren.length 有数据需要循环提交。接口提交成功之后需要。update locSubTable 中的 flag = 1 。表示缓存的数据已经被成功提交掉。
还需要更新下list 表的数据,将状态从 未处理 update 为 已处理 (此处更改是因为我的列表是tab类型。流程处理后的状态需要及时更新掉。)
写之前是打算贴代码的,写上之后发现不知道从哪里下手贴,只能说下处理的思路。
后面简单说下mixin的使用。是为了在全局监听网络变化,并能在app下进行离线提交。
在社区找到了uniapp是可以支持的。不过好像用的也不多。(此处该贴上官方链接,找到补上)

因为监听网络切换的时候,界面不会只停留在当前页。但是每个页面都写上也太多了,后来在vue的文档中找到了mixin 混入
《当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的选项 》
在写的时候也发现的一些坑,会一起记录下。(如果写完发现太多了那我就是被疫情在家憋惨了,憋成了话痨,尴尬)
再common中新建 mixin.js ; mixin的基础使用,可以在vue官方文档查找。
var isLoc ={
data() {
return {} // 有需要的data,也可以加上,我没有用到。
},
methoad:{
//因为需要在其他地方查数据库,所以依旧在最开始打开数据库
isOpenDB() {
console.log("mixin 中是否打开数据库");
var isOpen = plus.sqlite.isOpenDatabase({
name: 'nfc',
path: '_doc/nfcList.db'
});
console.log("数据库是否打开:" + !isOpen);
if (!isOpen) {
console.log('unopen:' + isOpen)
this.openDB()
}
},
openDB() {
openComDB('nfc', '_doc/nfcList.db', res => {
console.log("mixin:打开数据库");
this.getLocUser()
})
},
selStatusList() {
//查询是否有离线写入,未提交数据; flag == 0 false。
// console.log("切换至网络,查询是否有缓存未提交数据");
executeSQL('nfc', 'select * from statusTable where flag = 0', res => {
// console.log(res)
// console.log(res.length);
for (var i = 0; i < res.length; i++) {
this.submitPointFun(res[i].id); //返回的参数根据实际情况来的。
}
})
},
submitPointFun(curId) { // 提交巡检接口
//提交接口
getData({id: curId},data => { //填自己的接口、本身这个我封了下,按照自己的来。
urlFuc("xxxxxxxx", data, res => {
console.log("当前ID:" + curId + "提交成功");
//返回 成功后, 对列表的数据进行update 。
this.updatePointStatus(curId);
this.updatePointList(curId)
});
});
},
updatePointStatus(curId) {
// 切换至有网络后,提交成功后,更新已提交成功数据 更新巡检点状态
//修改flag = 1 - true ;
var updateSQL = 'update statusTable set flag = 1 where id = ' + curId;
executeSQL('nfc', updateSQL, res => {
console.log("更新数据");
})
},
updatePointList(curId) {
// 状态更改后,更改列表改ID的数据
var updateSQL = 'update pointLists set status = "已关联" where id = ' + curId;
console.log(updateSQL);
executeSQL('nfc', updateSQL, res => {
console.log("更新列表数据")
})
},
},
},
created() {
this.isOpenDB();
uni.onNetworkStatusChange((res) => {
//监听网络
console.log('MIXIN 下监听网络');
// console.log(res.isConnected);
// console.log(res.networkType);
if (res.networkType == 'none') {
console.log('无网络');
// that.seleceByType();
} else if (res.networkType == 'wifi' || res.networkType == '4g') {
console.log('wifi');
//切换到有网络时,需要查看是否有离线数据,并进行提交。
this.selStatusList(); //查询是否有离线数据
this.selLocTaskList();
// that.getNfCList();
}
})
}
}
export {
isLoc
}引用
import {
isLocData
} from '../../common/mixin.js'
export default {
mixins: [isLocData],
data(){}
}
遇到的坑,
最开始想放在app.vue下的。 但是安装后会白屏。后来改到main.vue下。
这是一个比较简单的使用,后面还有一个有点复杂的使用,离线提交的时候上报多选择数据和 图片,备注等信息。 (离线图片的时候,需要注意进程关掉再开,之前的缓存图片地址就没了,会导致离线上传时图片的丢失。所以建议不要手动关掉进程,或者将图片存下来,成功后再删掉。)
之后因为图片临时缓存的问题,我在本地存了,提交成功后,删除本地存的文件。(离线中mixin.js一样)
imageList ,当前图片显示,因为会多张图上传。
var files = [];
console.log(data.length);
var that = this;
//将临时文件存为本地文件,不受进程关闭的影响
for (var i = 0; i < data.length; i++) {
uni.saveFile({
tempFilePath: data[i],
success: img => {
var savedFilePath = img.savedFilePath;
console.log(savedFilePath);
that.imageList.push(savedFilePath)
console.log("tupian ")
console.log(that.imageList)
// files.push(savedFilePath);
// console.log(files);
// console.log(JSON.stringify(files));
}
})
}
成功后记得删除本地
removeSaveFiles(filePath) {
//移除本地存储文件;
console.log("需要删除的地址")
console.log(filePath)
uni.removeSavedFile({
filePath: filePath,
complete: function(res) {
console.log(res);
}
});
},状态也有 未处理,处理中,已结束。多个tabs。用法还是一样的。不做说明了。开始以为就一点点的。没想到会写这么多。
希望有帮助,这个sqlite 也是这次的时候使用过的,之前也没有。毕竟是个前端,搞的时候也问了后台一些思路。可能不是很完美,如果有什么好的建议也可以和我说。
补充说明
有小伙伴在指出
文档中 增删改 使用
void plus.sqlite.executeSql(options); 查询 使用
void plus.sqlite.selectSql(options);
最开始没发现,我封装的 plus.sqlite.selectSql(options); 增删改查都可以使用,也没碰到什么问题。
建议大家按照官方的来使用。
先说下我决定用sqlite的条件:
主要是流程处理,需要在无网络的情况下实现,数据量多的时候用h5的缓存完全不够,在看了文档之后选择使用SQLite ,早起在mui的时候使用的indexDB;
因为在社区也没收到具体的,所以写下记录下也和小伙伴分享下,有啥问题可以互相交流下。
该文档中用到的两个点 (SQLite 和vue中的mixin)
我这有两个环境,我先说一个简单;
- 主页菜单进去 到列表界面 从该步骤开始缓存本地数据;
- 从列表点击进入到详情,并在详情操作。有网络正常,无网络时存入表中,当切换到有网情况后,进行提交;
使用SQLite时需要先开权限,在配置文件中,如下图
SQLite官方demo ; 在hbuilderX 下新建demo pages/API/sqlite/sqlite 下官方提供的sqlite使用。为了使用方便,我把需要的单独提出来;
该出贴出function 代码,不做具体说明;
function openComDB(name, path, callback) {
plus.sqlite.openDatabase({
name: name,
path: path,
success: function(e) {
// plus.nativeUI.alert('打开数据库成功');
callback(e)
},
fail: function(e) {
// plus.nativeUI.alert("打开数据库失败");
callback(e);
}
})
}
function executeSQL(name, sql, callback) {
plus.sqlite.selectSql({
name: name,
sql: sql,
success: function(e) {
// console.log("查询数据库:" + name + ",表:" + sql + ";的");
// console.log(JSON.stringify(e));
callback(e);
},
fail: function(e) {
console.log("查询数据库失败:" + JSON.stringify(e));
callback(e);
}
})
}
export{
openComDB,
executeSQL
}该出 进入正题;
在需要用到的vue文件下,引入上方function; 路径是自己的;
import {openComDB,executeSQL,dropSQL} from '../../common/env.js'说下简单的思路:
1.进入lists界面,先判断是否有网络,有网络正常调用,无网络时需要判断本地数据库中是否有数据,无数据则第一次进入。有数据需要调用本地数据中的数据;
ps
在有些uni使用上可能会和现在的有点出入,因为这个是早期写的NFC写入的功能,用的nvue的,还是weex的模式下。
贴上部分相关代码
created() {
this.getNetworkType(); //初始化网络当前状态;
uni.onNavigationBarButtonTap((e) => {
//该处是因为的导航栏右边加了两个筛选条件。可以忽略。 不过如果做离线需要筛选的,筛选条件等数据同样需要缓存
if (e.index == 1) {
this.pickType();
} else if (e.index == 0) {
this.pickBuild()
}
})
},
methods: {
getNetworkType() {
//获取网络信息
uni.getNetworkType({
success: res => {
this.netWork = res.networkType;
this.isOpenDB();
}
})
},
isOpenDB() {
console.log('是否打开数据库');
var isOpen = plus.sqlite.isOpenDatabase({
name: 'nfc', //数据库的名字
path: '_doc/nfcList.db' //地址
});
console.log(!isOpen);
if (!isOpen) {
console.log('Unoepned:' + isOpen);
// plus.nativeUI.alert('Unopened!');
this.openDB(); //打開DB
} else {
// plus.nativeUI.alert('Opened!');
this.isNet();
// this.getLocalType();
}
},
openDB() {
//SQLite
openComDB('nfc', '_doc/nfcList.db', res => {
console.log('打开数据库');
this.isNet();
});
},
isNet(){
//网络问题;
if (this.netWork == 'wifi' || this.netWork == '4g') {
//在有网络情况下,会先情况之前的表,为了防止没有及时更新到数据。update我是嫌麻烦,没这样写。就这样暴力写了。
console.log('wifi || 4g ');
this.dropTable("pointLists");
this.dropTable("codeTypeTable");
this.dropTable("codeTable");
this.dropTable("statusTable")
//删了之后创建表
this.createCodeTable();
this.createCodeTypeTable();
this.createBuildTable();
this.createLists();
this.createUpateStatus(); // 离线时更新
//然后把数据插入进去
this.getTabType(); //初始化格式
this.getPonitType(); //获取code。默认值
this.getCodeType(); // 类型下的选择项;
this.getBuilds(); // 获取建筑物数据
} else {
//无网络时;
console.log('初始化无网络');
this.getTabType(); //初始化格式
this.locCodeTypeItem();
this.selBuildFun();
}
//上面贴的drop,create,insert 我会在下面贴出部分代码。不会全部贴.SQL语句不会的建议百度找文档多看下,无非就是增删改查
},
}整个代码贴上太长了,我还是分段写吧;
本身就是个带tab类型的列表。延用nvue 的 weex的形式,未改成uniapp形式,如需参照此处tab,需要看之前的官方demo。 建议用官方新的uniapp模式,我是懒得改。
//初始化
getTabType() {
//初始化列表;
let ary = [];
for (let i = 0; i < this.tabBars.length; i++) {
let aryItem = {
loadingText: "",
data: [],
pageNum: 1
}
ary.push(aryItem);
}
this.newsitems = ary;
if(this.netWork == "wifi" || this.netWork == "4g"){
this.getPointList() //默认加载未处理; 有网络下,正常调用接口
}else{
this.selPointList() //无网络下调用数据库表中的数据;
}
},再有网络调用接口时需要将 数据insert到创建的数据表中;
创建数据库中的表
我的思路是整个app为一个数据库,有各种不同的表。 目前只有nfc中用到了,所以数据库的name 就取名 nfc 了,未进行修改;
现在正儿八经的创建表;
用简单的建筑信息为例;根据自己需要的进行创建表;
createBuildTable() {
//创建建筑物类型表;
var sqlTable = 'create table if not exists buildTable("id" INT(10) NOT NULL UNIQUE,"name" CHAR,"gridCode" CHAR)'
executeSQL('nfc', sqlTable, res => {})
},在有网调用接口时,insert 表;需要与上方创建的完全对应,最后一个不加 “,” 只有不对应就会报错
insertBuildCode() {
for (var i = 0; i < this.builds.length; i++) {
var sqlInsert = "insert into buildTable values('";
sqlInsert += this.builds[i].id + "','";
sqlInsert += this.builds[i].name + "','";
sqlInsert += this.builds[i].gridCode + "'";
sqlInsert += ')';
executeSQL('nfc', sqlInsert, res => {
})
}
this.getLocBuilds() //插入成功后,就可以查看结果。此处用到就直接赋值,没用到,或者别处用到,就在别处调用
},
getLocBuilds() {
executeSQL('nfc', 'select * from buildTable', res => {
console.log("建筑物查询结果");
this.builds = res;
this.selBuildFun()
})
},查看就这样,就写个简单的例子。列表数据比较多。就不放上。如果详情的数据是通过detailById 接口调用,list表的需要将详情的数据加进去。
当整个数据存上后,就是点击list跳转到detail界面。
detail正常的vue文件。
有网络时正常查看,进行提交操作。
无网络时,查看本地数据库的表。
所有创建和插入都是在list进行的,detail.vue中 进行 查看,和更改,如果需要删除 也可。 (因为在list就很有可能是无网络的情况,所以所有的数据都在列表获取到了)
list ---> detail
可以带id ,也可以带json、建议带唯一的id就可以了,可以在detail select 出需要的数据;
我这里是觉着数据已经在list存上了,detail不如直接使用,不管用网络无网络,本身做提交,后台也不会不停的改数据。
比较严谨的可以有网络时候调用详情接口,无网络时在本地查。
查询代码上面贴了列子此处就不放上了。
简单说一下离线提交。会用到VUE的mixin。
离线提交的思路 。在list的时候需要创建 提交的 表 locSubTable(随便起的名字方便后面提到) ,并在最后 加上 flag 字段 (这个自己随意) 类型INT 。因为没有布尔。所以在插入的时候需要用flag 0,1 进行判断是否需要缓存提交。
0 为 false 1 为 true ;
在detail 内,若 是离线时进行提交,在 locSubTable 进行insert 。最后flag 插入 为 0 ;
在无网络切换至 wifi/4g下,查询 locSubTable 表 where flag = 0 的数据。 返回的 res.length = 0 的时候,无离线提交。
ren.length 有数据需要循环提交。接口提交成功之后需要。update locSubTable 中的 flag = 1 。表示缓存的数据已经被成功提交掉。
还需要更新下list 表的数据,将状态从 未处理 update 为 已处理 (此处更改是因为我的列表是tab类型。流程处理后的状态需要及时更新掉。)
写之前是打算贴代码的,写上之后发现不知道从哪里下手贴,只能说下处理的思路。
后面简单说下mixin的使用。是为了在全局监听网络变化,并能在app下进行离线提交。
在社区找到了uniapp是可以支持的。不过好像用的也不多。(此处该贴上官方链接,找到补上)
因为监听网络切换的时候,界面不会只停留在当前页。但是每个页面都写上也太多了,后来在vue的文档中找到了mixin 混入
《当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的选项 》
在写的时候也发现的一些坑,会一起记录下。(如果写完发现太多了那我就是被疫情在家憋惨了,憋成了话痨,尴尬)
再common中新建 mixin.js ; mixin的基础使用,可以在vue官方文档查找。
var isLoc ={
data() {
return {} // 有需要的data,也可以加上,我没有用到。
},
methoad:{
//因为需要在其他地方查数据库,所以依旧在最开始打开数据库
isOpenDB() {
console.log("mixin 中是否打开数据库");
var isOpen = plus.sqlite.isOpenDatabase({
name: 'nfc',
path: '_doc/nfcList.db'
});
console.log("数据库是否打开:" + !isOpen);
if (!isOpen) {
console.log('unopen:' + isOpen)
this.openDB()
}
},
openDB() {
openComDB('nfc', '_doc/nfcList.db', res => {
console.log("mixin:打开数据库");
this.getLocUser()
})
},
selStatusList() {
//查询是否有离线写入,未提交数据; flag == 0 false。
// console.log("切换至网络,查询是否有缓存未提交数据");
executeSQL('nfc', 'select * from statusTable where flag = 0', res => {
// console.log(res)
// console.log(res.length);
for (var i = 0; i < res.length; i++) {
this.submitPointFun(res[i].id); //返回的参数根据实际情况来的。
}
})
},
submitPointFun(curId) { // 提交巡检接口
//提交接口
getData({id: curId},data => { //填自己的接口、本身这个我封了下,按照自己的来。
urlFuc("xxxxxxxx", data, res => {
console.log("当前ID:" + curId + "提交成功");
//返回 成功后, 对列表的数据进行update 。
this.updatePointStatus(curId);
this.updatePointList(curId)
});
});
},
updatePointStatus(curId) {
// 切换至有网络后,提交成功后,更新已提交成功数据 更新巡检点状态
//修改flag = 1 - true ;
var updateSQL = 'update statusTable set flag = 1 where id = ' + curId;
executeSQL('nfc', updateSQL, res => {
console.log("更新数据");
})
},
updatePointList(curId) {
// 状态更改后,更改列表改ID的数据
var updateSQL = 'update pointLists set status = "已关联" where id = ' + curId;
console.log(updateSQL);
executeSQL('nfc', updateSQL, res => {
console.log("更新列表数据")
})
},
},
},
created() {
this.isOpenDB();
uni.onNetworkStatusChange((res) => {
//监听网络
console.log('MIXIN 下监听网络');
// console.log(res.isConnected);
// console.log(res.networkType);
if (res.networkType == 'none') {
console.log('无网络');
// that.seleceByType();
} else if (res.networkType == 'wifi' || res.networkType == '4g') {
console.log('wifi');
//切换到有网络时,需要查看是否有离线数据,并进行提交。
this.selStatusList(); //查询是否有离线数据
this.selLocTaskList();
// that.getNfCList();
}
})
}
}
export {
isLoc
}引用
import {
isLocData
} from '../../common/mixin.js'
export default {
mixins: [isLocData],
data(){}
}
遇到的坑,
最开始想放在app.vue下的。 但是安装后会白屏。后来改到main.vue下。
这是一个比较简单的使用,后面还有一个有点复杂的使用,离线提交的时候上报多选择数据和 图片,备注等信息。 (离线图片的时候,需要注意进程关掉再开,之前的缓存图片地址就没了,会导致离线上传时图片的丢失。所以建议不要手动关掉进程,或者将图片存下来,成功后再删掉。)
之后因为图片临时缓存的问题,我在本地存了,提交成功后,删除本地存的文件。(离线中mixin.js一样)
imageList ,当前图片显示,因为会多张图上传。
var files = [];
console.log(data.length);
var that = this;
//将临时文件存为本地文件,不受进程关闭的影响
for (var i = 0; i < data.length; i++) {
uni.saveFile({
tempFilePath: data[i],
success: img => {
var savedFilePath = img.savedFilePath;
console.log(savedFilePath);
that.imageList.push(savedFilePath)
console.log("tupian ")
console.log(that.imageList)
// files.push(savedFilePath);
// console.log(files);
// console.log(JSON.stringify(files));
}
})
}
成功后记得删除本地
removeSaveFiles(filePath) {
//移除本地存储文件;
console.log("需要删除的地址")
console.log(filePath)
uni.removeSavedFile({
filePath: filePath,
complete: function(res) {
console.log(res);
}
});
},状态也有 未处理,处理中,已结束。多个tabs。用法还是一样的。不做说明了。开始以为就一点点的。没想到会写这么多。
希望有帮助,这个sqlite 也是这次的时候使用过的,之前也没有。毕竟是个前端,搞的时候也问了后台一些思路。可能不是很完美,如果有什么好的建议也可以和我说。
补充说明
有小伙伴在指出
文档中 增删改 使用
void plus.sqlite.executeSql(options); 查询 使用
void plus.sqlite.selectSql(options);
最开始没发现,我封装的 plus.sqlite.selectSql(options); 增删改查都可以使用,也没碰到什么问题。
建议大家按照官方的来使用。
收起阅读 »
main.js Vue.prototype 全局变量的挂载与动态赋值
在main.js中,Vue.prototype.$appName = “XXX” 可以用来定义一些我们不常变化的全局属性或者方法的。
但是有时候我们想动态改变它。特别是从远程获取最新的json信息,然后动态更新这个main,js里面定义的东西。
所以在定义、挂载这些变量的时候,可以这样写:
Vue.prototype.$appName = {'value':'XXXX'}
调用的时候,我们用var abc = this.$appName.value 进行调用
然后再从远程获取新的信息时,可以动态更新此值
this.$appName.value = 'YYYY'
在main.js中,Vue.prototype.$appName = “XXX” 可以用来定义一些我们不常变化的全局属性或者方法的。
但是有时候我们想动态改变它。特别是从远程获取最新的json信息,然后动态更新这个main,js里面定义的东西。
所以在定义、挂载这些变量的时候,可以这样写:
Vue.prototype.$appName = {'value':'XXXX'}
调用的时候,我们用var abc = this.$appName.value 进行调用
然后再从远程获取新的信息时,可以动态更新此值
this.$appName.value = 'YYYY'

《重点是:#FFF级的小白用uniapp,50就能做出一个通用社交app》
今儿数据丢了,必须强颜欢笑啊。。。掐指一算,而今迈步刚好50天
回顾历史啊,,,想当天。。。。
50天前,我连js的全拼都记不住,就像脑袋里没那属性,或者是给冒泡了
但是50天后的现在,,,世事变幻莫测,天旋地转,物是人非,哈哈,我有了一个自己写的,能注册、登录、改资料、发布、回复、聚合等等的社交小app!
我要感谢uniApp,感谢builderX,感谢uniCloud,感谢ccTv。。。嗯,连这cctv不用驼峰都觉着别扭。。。
当然,我这离回梦、林举那些高人还有十万八千里路,,,但是,至少现在,嗯,以后app那点事儿可就蒙不了我了哈。。。
毕竟哥也算是个程序员了诶巴扎黑
so,千言万语汇成一句话,uniApp、uniApp、uni——App!
今儿数据丢了,必须强颜欢笑啊。。。掐指一算,而今迈步刚好50天
回顾历史啊,,,想当天。。。。
50天前,我连js的全拼都记不住,就像脑袋里没那属性,或者是给冒泡了
但是50天后的现在,,,世事变幻莫测,天旋地转,物是人非,哈哈,我有了一个自己写的,能注册、登录、改资料、发布、回复、聚合等等的社交小app!
我要感谢uniApp,感谢builderX,感谢uniCloud,感谢ccTv。。。嗯,连这cctv不用驼峰都觉着别扭。。。
当然,我这离回梦、林举那些高人还有十万八千里路,,,但是,至少现在,嗯,以后app那点事儿可就蒙不了我了哈。。。
毕竟哥也算是个程序员了诶巴扎黑
so,千言万语汇成一句话,uniApp、uniApp、uni——App!
收起阅读 »
贡献一个知识点,文档里肯定不会告诉你的东西
where查询和聚合不能一起用。
比如:想连表查询的话只能用match+lookup。
至于为什么,应该是国家机密吧。毕竟连where和聚合不能一起用都要保密。。。这天气真是热了
so,鉴于聚合是民生刚需,所以请大家奔走相告,早用match早超生。
where查询和聚合不能一起用。
比如:想连表查询的话只能用match+lookup。
至于为什么,应该是国家机密吧。毕竟连where和聚合不能一起用都要保密。。。这天气真是热了
so,鉴于聚合是民生刚需,所以请大家奔走相告,早用match早超生。
tailwind.css 对于小程序按钮样式的影响
/* 罪魁祸首 */
/**
* Correct the inability to style clickable types in iOS and Safari.
*/
button,
[type="button"],
[type="reset"],
[type="submit"] {
-webkit-appearance: button;
}
/** 解决方案 */
button, [type="button"], [type="reset"], [type="submit"] {
-moz-appearance: none;
-webkit-appearance: none;
}
tailwind.css 对于小程序按钮样式的影响,前两天发现小程序按钮的默认样式一直去不掉,今天才发现是因为 tailwind.css 导致的。 他有一段上面那样的 css 采用了系统自定义的按钮样式导致你怎么覆盖 button::after 都没有用
/* 罪魁祸首 */
/**
* Correct the inability to style clickable types in iOS and Safari.
*/
button,
[type="button"],
[type="reset"],
[type="submit"] {
-webkit-appearance: button;
}
/** 解决方案 */
button, [type="button"], [type="reset"], [type="submit"] {
-moz-appearance: none;
-webkit-appearance: none;
}
tailwind.css 对于小程序按钮样式的影响,前两天发现小程序按钮的默认样式一直去不掉,今天才发现是因为 tailwind.css 导致的。 他有一段上面那样的 css 采用了系统自定义的按钮样式导致你怎么覆盖 button::after 都没有用
收起阅读 »
基于uni-app的高颜值极速记账小程序
【项目背景】
日常生活中,多少都会有记账的需求。(今天请客花了多少钱?今天工资收了多少?....本月有几张信用卡要还?还款日期、还款金额分别是多少?...)
通常的记账软件,80%都要求下载APP,并且操作较为繁琐。
故开发此小程序,名曰“小熙记账”。熙通“禧”,意为:幸福;吉祥。
记一笔收入,买一份礼物,给自己一个小确幸。
【开发背景】基于uni-app,用最优雅的代码敏捷开发
【产品目标】行云流水般的极速记账体验
【功能列表】
1、极速记账:三秒记账,打完收枪
2、收支统计:按月查统计图
3、多账户管理:储蓄账户、信用账户、其他账户,支持账户之间转账
4、流水查询:查看所有记账流水
5、账目总览:累计、当月收支情况,还款任务列表,近三月大额支出
【产品截图】



【即刻体验】

【项目背景】
日常生活中,多少都会有记账的需求。(今天请客花了多少钱?今天工资收了多少?....本月有几张信用卡要还?还款日期、还款金额分别是多少?...)
通常的记账软件,80%都要求下载APP,并且操作较为繁琐。
故开发此小程序,名曰“小熙记账”。熙通“禧”,意为:幸福;吉祥。
记一笔收入,买一份礼物,给自己一个小确幸。
【开发背景】基于uni-app,用最优雅的代码敏捷开发
【产品目标】行云流水般的极速记账体验
【功能列表】
1、极速记账:三秒记账,打完收枪
2、收支统计:按月查统计图
3、多账户管理:储蓄账户、信用账户、其他账户,支持账户之间转账
4、流水查询:查看所有记账流水
5、账目总览:累计、当月收支情况,还款任务列表,近三月大额支出
【产品截图】
【即刻体验】

图片并排排版、src中使用js等小代码
调用系统相册中图片js:
<script language="javascript">
document.getElementById('img_ho').src = plus.io.resolveLocalFileSystemURL("_www/hengping.jpg");
document.getElementById('img_vo').src = plus.io.resolveLocalFileSystemURL("_www/shuping.jpg");
</script>
并排显示在页面上:
<table><tr>
<td><a href="vo.html" target="_parent" title="点击获取"><img id="img_vo" src="?" onerror="this.src='images/nopic.png';this.οnerrοr=null" border=0/></a></td>
<td><a href="ho.html" target="_parent" title="点击获取"><img id="img_ho" src="?" onerror="this.src='images/nopic.png';this.οnerrοr=null" border=0/></a></td>
</tr></table>调用系统相册中图片js:
<script language="javascript">
document.getElementById('img_ho').src = plus.io.resolveLocalFileSystemURL("_www/hengping.jpg");
document.getElementById('img_vo').src = plus.io.resolveLocalFileSystemURL("_www/shuping.jpg");
</script>
并排显示在页面上:
<table><tr>
<td><a href="vo.html" target="_parent" title="点击获取"><img id="img_vo" src="?" onerror="this.src='images/nopic.png';this.οnerrοr=null" border=0/></a></td>
<td><a href="ho.html" target="_parent" title="点击获取"><img id="img_ho" src="?" onerror="this.src='images/nopic.png';this.οnerrοr=null" border=0/></a></td>
</tr></table>js_to_APP手机不能下载base格式图片的处理
js在pc端正常下载base图片,使用HBuilder生成APP后下载失败,原因是手机浏览器不能直接下载base64位图片的文件,使用plus进行直接转存,代码如下:
image对象为base64对象,调用方法为 saveBasePic(base,"ceshi.jpg"),切记在使用HB生成APP时注意在配置文件中修改runmode为liberate模式,normal测试是有问题的。
"runmode" : "liberate", /应用的首次启动运行模式,可取liberate或normal,liberate模式在第一次启动时将解压应用资源(Android平台File API才可正常访问_www目录)/
function saveBasePic (image,imageName){
var b = new plus.nativeObj.Bitmap();
var path = plus.io.convertLocalFileSystemURL("_www/"+imageName);//将文件短路径转换成本地完整路径
alert(path);
b.loadBase64Data(image,function(){
//alert("创建成功");
b.save("_www/"+imageName,{overwrite:true},function(){
//console.log("保存成功");
plus.gallery.save("_www/"+imageName, function () {
alert( "保存图片到相册成功" );
event_b(true,path);
},function(){
alert( "保存图片到相册失败" );
event_b(false,path);
});
},function(){
alert("保存图片失败!");
event_b(false,path);
});
},function(){
alert("写入文件失败,确认APP是否具有权限!");
event_b(false,path);
});
} js在pc端正常下载base图片,使用HBuilder生成APP后下载失败,原因是手机浏览器不能直接下载base64位图片的文件,使用plus进行直接转存,代码如下:
image对象为base64对象,调用方法为 saveBasePic(base,"ceshi.jpg"),切记在使用HB生成APP时注意在配置文件中修改runmode为liberate模式,normal测试是有问题的。
"runmode" : "liberate", /应用的首次启动运行模式,可取liberate或normal,liberate模式在第一次启动时将解压应用资源(Android平台File API才可正常访问_www目录)/
function saveBasePic (image,imageName){
var b = new plus.nativeObj.Bitmap();
var path = plus.io.convertLocalFileSystemURL("_www/"+imageName);//将文件短路径转换成本地完整路径
alert(path);
b.loadBase64Data(image,function(){
//alert("创建成功");
b.save("_www/"+imageName,{overwrite:true},function(){
//console.log("保存成功");
plus.gallery.save("_www/"+imageName, function () {
alert( "保存图片到相册成功" );
event_b(true,path);
},function(){
alert( "保存图片到相册失败" );
event_b(false,path);
});
},function(){
alert("保存图片失败!");
event_b(false,path);
});
},function(){
alert("写入文件失败,确认APP是否具有权限!");
event_b(false,path);
});
} uniapp数字键盘
插件预览图

使用教程
1.插件代码拷贝
- 下载后把components目录下/digitKeyboard/digitKeyboard.vue文件拷贝到自己项目目录下
2.插件全局配置
- 在项目里main.js中配置如下代码
import digitKeyboard from './components/digitKeyboard/digitKeyboard.vue'
Vue.component('digitKeyboard', digitKeyboard)
3.插件使用
- vue页面使用
<template>
<view>
<!-- 数字键盘 -->
<digitKeyboard v-if="isShowKeyboardWindow" :inputVal="inputVal" :label="label" @cancel="isShowKeyboardWindow = false" @confirm="keyboardConfirm"/>
</view>
</template>
<script>
export default {
data() {
return {
inputVal:'1',
label:'现金支付',
isShowKeyboardWindow:true,//是否显示键盘窗口
};
},
methods:{
keyboardConfirm(val){
console.log(val)
uni.showToast({
title:'当前输入的值:'+val,
icon:'none',
duration:4000
})
}
}
}
</script>
<style lang="less">
</style>
兼容性
uni-app项目中使用都兼容
插件预览图
使用教程
1.插件代码拷贝
- 下载后把components目录下/digitKeyboard/digitKeyboard.vue文件拷贝到自己项目目录下
2.插件全局配置
- 在项目里main.js中配置如下代码
import digitKeyboard from './components/digitKeyboard/digitKeyboard.vue'
Vue.component('digitKeyboard', digitKeyboard)
3.插件使用
- vue页面使用
<template>
<view>
<!-- 数字键盘 -->
<digitKeyboard v-if="isShowKeyboardWindow" :inputVal="inputVal" :label="label" @cancel="isShowKeyboardWindow = false" @confirm="keyboardConfirm"/>
</view>
</template>
<script>
export default {
data() {
return {
inputVal:'1',
label:'现金支付',
isShowKeyboardWindow:true,//是否显示键盘窗口
};
},
methods:{
keyboardConfirm(val){
console.log(val)
uni.showToast({
title:'当前输入的值:'+val,
icon:'none',
duration:4000
})
}
}
}
</script>
<style lang="less">
</style>
兼容性
uni-app项目中使用都兼容
收起阅读 »uni-app编译为小程序的时候报,v-slot 不支持动态插槽名
uni-app编译为小程序的时候报,v-slot 不支持动态插槽名,我记得我写微信小程序的时候slot是支持slot动态切换的呀?h5下正常
uni-app编译为小程序的时候报,v-slot 不支持动态插槽名,我记得我写微信小程序的时候slot是支持slot动态切换的呀?h5下正常
