






【分享】监听subNVue的show和hide事件的方法
使用uniapp做开发,时不时会遇到困难。遇到困难时,可以在Dcloud社区和QQ群提问。但Dcloud官方分配于解答开发者疑问的力量远远不足,大多数提问根本不会得到任何回复。我是个暴脾气,很多时候气得捶足顿胸。但那又怎样呢,不回复就是不回复。
以前,我对这个问题只会抱怨。后来,我想通了:自己对社区并没有太多贡献,凭什么社区无偿为你解答问题?如果每个人都愿意花一点时间,主动在社区发布一些经验分享,或者回复一些他人遇到而自己已有解决方案的问题,那么社区的质量就会提升,下次遇到问题时,在社区搜索答案就更容易命中有效答案了。
所以,从现在开始,以后但凡有些许有价值的经验总结,哪怕价值很小很小,我都会发布到社区。虽然个人的能力非常有限,解决不了很大的问题,只能从小处着手,但兴许对未来的某一个人有用呢?
以下是正文
用subNVue做popup是非常完美的方案。美中不足的是,uniapp的subNVue并未提供show和hide事件,以至用subNVue做的popup,无法进行有效的初始化。
这里提供一个监听subNVue(或popup)的show和hide事件的办法。
具体做法
在subNVue页面的js代码中,在onLoad方法(uni-app编译模式适用。如果是week编译模式,可改为beforeCreate方法)内添加如下js代码:
uni.getCurrentSubNVue().addEventListener("show", function() {
console.log("subNVue子窗体已显示!")
});
uni.getCurrentSubNVue().addEventListener("hide", function() {
console.log("subNVue子窗体已隐藏!")
});完美解决!
使用uniapp做开发,时不时会遇到困难。遇到困难时,可以在Dcloud社区和QQ群提问。但Dcloud官方分配于解答开发者疑问的力量远远不足,大多数提问根本不会得到任何回复。我是个暴脾气,很多时候气得捶足顿胸。但那又怎样呢,不回复就是不回复。
以前,我对这个问题只会抱怨。后来,我想通了:自己对社区并没有太多贡献,凭什么社区无偿为你解答问题?如果每个人都愿意花一点时间,主动在社区发布一些经验分享,或者回复一些他人遇到而自己已有解决方案的问题,那么社区的质量就会提升,下次遇到问题时,在社区搜索答案就更容易命中有效答案了。
所以,从现在开始,以后但凡有些许有价值的经验总结,哪怕价值很小很小,我都会发布到社区。虽然个人的能力非常有限,解决不了很大的问题,只能从小处着手,但兴许对未来的某一个人有用呢?
以下是正文
用subNVue做popup是非常完美的方案。美中不足的是,uniapp的subNVue并未提供show和hide事件,以至用subNVue做的popup,无法进行有效的初始化。
这里提供一个监听subNVue(或popup)的show和hide事件的办法。
具体做法
在subNVue页面的js代码中,在onLoad方法(uni-app编译模式适用。如果是week编译模式,可改为beforeCreate方法)内添加如下js代码:
uni.getCurrentSubNVue().addEventListener("show", function() {
console.log("subNVue子窗体已显示!")
});
uni.getCurrentSubNVue().addEventListener("hide", function() {
console.log("subNVue子窗体已隐藏!")
});完美解决!
收起阅读 »
【分享】在uniapp的nvue和subNVue中添加本地自定义字体/字体图标的方法
使用uniapp做开发,时不时会遇到困难。遇到困难时,可以在Dcloud社区和QQ群提问。但Dcloud官方分配于解答开发者疑问的力量远远不足,大多数提问根本不会得到任何回复。我是个暴脾气,很多时候气得捶足顿胸。但那又怎样呢,不回复就是不回复。
以前,我对这个问题只会抱怨。后来,我想通了:自己对社区并没有太多贡献,凭什么社区无偿为你解答问题?如果每个人都愿意花一点时间,主动在社区发布一些经验分享,或者回复一些他人遇到而自己已有解决方案的问题,那么社区的质量就会提升,下次遇到问题时,在社区搜索答案就更容易命中有效答案了。
所以,从现在开始,以后但凡有些许有价值的经验总结,哪怕价值很小很小,我都会发布到社区。虽然个人的能力非常有限,解决不了很大的问题,只能从小处着手,但兴许对未来的某一个人有用呢?
以下是正文
nvue和subnvue引入自定义自体/自定义图标,不能用CSS方法,而只能用week所规定的方法。具体做法是,在nvue或subnvue页面内,引入如下js代码(uni-app编译模式下,可放置于onLoad函数内;week编译模式下,可放置于beforeCreate函数内。貌似也可以直接放置于“export default {...}”之前)。
const domModule = weex.requireModule('dom')
domModule.addRule('fontFace', {
'fontFamily': "iconfont2",
'src': "url('http://at.alicdn.com/t/font_1469606063_76593.ttf')"
});其中:
- @fontFace 协议名称,不可修改。
- @fontFamily font-family的名称。
- @src 字体地址,url('') 是保留字段,其参数如下:
- http. 从HTTP请求加载, e.g. url('http://at.alicdn.com/t/font_1469606063_76593.ttf')
- https. 从HTTPS请求加载, e.g. url('https://at.alicdn.com/t/font_1469606063_76593.ttf')
- local, Android ONLY. 从assets目录读取, e.g. url('local://foo.ttf'), foo.ttf 是文件名在你的assets目录中.
- file. 从本地文件读取, e.g. url('file://storage/emulated/0/Android/data/com.alibaba.weex/cache/http:__at.alicdn.com_t_font_1469606063_76593.ttf')
- data. 从base64读取, e.g. url('data:font/truetype;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQrD ....'), 上述data字段不全。
问题
问题的难点在于:src的正确写法。http和https写法要求联网加载,如果断网就无法显示,其用户体验肯定不好。local写法只有Android能够采用,iOS无法采用,兼容性差。那么,就只剩下file写法和data写法可用了。
但问题在于,file的正确写法是怎样的?我试了N种办法,都失败了。最后只能采用data写法:先百度“ttf转base64”,把ttf文件上传到网上的“ttf转base64”网页,将生成的data字段复制到上述data字段即可。但问题来了:(1)不放心那些未知网站,担心转码形成的base64有个别字节错误;(2)大段的base64数据影响代码的美观,且会干扰HX的变量提示功能;(3)修改ttf文件(如增删改图标)需要重新转码生成新的base64……总之,很不方便。
理想的写法,还是file写法,url('file://storage/...');
作为小白,在缺乏直接资料的情况下,根本不知道file正确写法是怎样的。而且这种非核心小问题,在Dcloud和QQ群上提问,是不可能得到回复的。在陆续花费了几天的时间后,终于解决了。
具体办法
(1)将自己的ttf文件(如iconfont.ttf),放置于static目录下
(2)在nvue或subnve的js中加入如下代码:
const domModule = weex.requireModule('dom')
domModule.addRule('fontFace', {
'fontFamily': "iconfont2",
'src': 'url("'+"file:/" + plus.io.convertLocalFileSystemURL("_www/static/iconfont.ttf")+'")'
});(3)在需要引入iconfont.ttf中的自定义字体/图标的页面元素的css中添加font-family: iconfont2。这一步千万别忘了。
(4)引用字体。在html中,采用"&#n位十进制unicode码"格式引用自定义字符/字体图标,例如“”;在js中,采用“\u四位十六进制unicode码”格式,例如“\uE005”;而在css中,则采用“\四位十六进制unicode”格式,例如“\E005”。
注意
- plus.io.convertLocalFileSystemURL()函数可以把本地相对路径转换为本地绝对路径。
- 代码中的“file:/”只有一条斜杠,而是不两条。因为,plus.io.convertLocalFileSystemURL()函数获得的本地绝对路径,已经自带了一条斜杠。
- fontFamily的值,即iconfont2可以任意取。但iconfont.ttf文件内部的字体的名称必须足够特殊、不与系统注册的其他字体的名称冲突。
- “font-family: iconfont2;”必须直接放置于具体引用自定义字体的<text>标签的css中,而不能放置于<text>标签的父/祖标签的css中,否则自定义定体将不生效。例如:
<view class="mytext1"> <text class="mytext2">{{text}}</text> </view>data() { return { text: '\uE005' } }.mytext1 { font-family: iconfont2; } .mytext2 { font-family: iconfont2; }
在上述代码中,“.mytext1”由于没有直接作用于<text>标签,因而无效;“.mytext2”由于直接作用于<text>标签,所以有效。
补充:发现了一个巨坑:按照上述方法引用的自定义字体,仅在开发阶段(真机模拟时)有效,云打包之后仍然不能工作。
最新实测有效的建议:
在开发阶段,可采用 'src': 'url("'+"file:/" + plus.io.convertLocalFileSystemURL("_www/static/iconfont.ttf")+'")'这种写法,能在真机模拟时工作;开发完成后,打包时,可采用url('data:font/truetype;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQrD ....')这种写法,在真机运行和打包后都能够工作。在开发阶段,也可采用url('data:font/truetype;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQrD ....')这种写法,但不建议,原因在前文说过:干扰代码开发且不便于修改ttf文件。
另,附一个ttf文件转base64的网站
https://www.zhangxinxu.com/sp/base64.html
生成的base64,复制到HX新页面后,先将头部字符修改为data:font/truetype;charset=utf-8;base64,再复制到代码中。
使用uniapp做开发,时不时会遇到困难。遇到困难时,可以在Dcloud社区和QQ群提问。但Dcloud官方分配于解答开发者疑问的力量远远不足,大多数提问根本不会得到任何回复。我是个暴脾气,很多时候气得捶足顿胸。但那又怎样呢,不回复就是不回复。
以前,我对这个问题只会抱怨。后来,我想通了:自己对社区并没有太多贡献,凭什么社区无偿为你解答问题?如果每个人都愿意花一点时间,主动在社区发布一些经验分享,或者回复一些他人遇到而自己已有解决方案的问题,那么社区的质量就会提升,下次遇到问题时,在社区搜索答案就更容易命中有效答案了。
所以,从现在开始,以后但凡有些许有价值的经验总结,哪怕价值很小很小,我都会发布到社区。虽然个人的能力非常有限,解决不了很大的问题,只能从小处着手,但兴许对未来的某一个人有用呢?
以下是正文
nvue和subnvue引入自定义自体/自定义图标,不能用CSS方法,而只能用week所规定的方法。具体做法是,在nvue或subnvue页面内,引入如下js代码(uni-app编译模式下,可放置于onLoad函数内;week编译模式下,可放置于beforeCreate函数内。貌似也可以直接放置于“export default {...}”之前)。
const domModule = weex.requireModule('dom')
domModule.addRule('fontFace', {
'fontFamily': "iconfont2",
'src': "url('http://at.alicdn.com/t/font_1469606063_76593.ttf')"
});其中:
- @fontFace 协议名称,不可修改。
- @fontFamily font-family的名称。
- @src 字体地址,url('') 是保留字段,其参数如下:
- http. 从HTTP请求加载, e.g. url('http://at.alicdn.com/t/font_1469606063_76593.ttf')
- https. 从HTTPS请求加载, e.g. url('https://at.alicdn.com/t/font_1469606063_76593.ttf')
- local, Android ONLY. 从assets目录读取, e.g. url('local://foo.ttf'), foo.ttf 是文件名在你的assets目录中.
- file. 从本地文件读取, e.g. url('file://storage/emulated/0/Android/data/com.alibaba.weex/cache/http:__at.alicdn.com_t_font_1469606063_76593.ttf')
- data. 从base64读取, e.g. url('data:font/truetype;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQrD ....'), 上述data字段不全。
问题
问题的难点在于:src的正确写法。http和https写法要求联网加载,如果断网就无法显示,其用户体验肯定不好。local写法只有Android能够采用,iOS无法采用,兼容性差。那么,就只剩下file写法和data写法可用了。
但问题在于,file的正确写法是怎样的?我试了N种办法,都失败了。最后只能采用data写法:先百度“ttf转base64”,把ttf文件上传到网上的“ttf转base64”网页,将生成的data字段复制到上述data字段即可。但问题来了:(1)不放心那些未知网站,担心转码形成的base64有个别字节错误;(2)大段的base64数据影响代码的美观,且会干扰HX的变量提示功能;(3)修改ttf文件(如增删改图标)需要重新转码生成新的base64……总之,很不方便。
理想的写法,还是file写法,url('file://storage/...');
作为小白,在缺乏直接资料的情况下,根本不知道file正确写法是怎样的。而且这种非核心小问题,在Dcloud和QQ群上提问,是不可能得到回复的。在陆续花费了几天的时间后,终于解决了。
具体办法
(1)将自己的ttf文件(如iconfont.ttf),放置于static目录下
(2)在nvue或subnve的js中加入如下代码:
const domModule = weex.requireModule('dom')
domModule.addRule('fontFace', {
'fontFamily': "iconfont2",
'src': 'url("'+"file:/" + plus.io.convertLocalFileSystemURL("_www/static/iconfont.ttf")+'")'
});(3)在需要引入iconfont.ttf中的自定义字体/图标的页面元素的css中添加font-family: iconfont2。这一步千万别忘了。
(4)引用字体。在html中,采用"&#n位十进制unicode码"格式引用自定义字符/字体图标,例如“”;在js中,采用“\u四位十六进制unicode码”格式,例如“\uE005”;而在css中,则采用“\四位十六进制unicode”格式,例如“\E005”。
注意
- plus.io.convertLocalFileSystemURL()函数可以把本地相对路径转换为本地绝对路径。
- 代码中的“file:/”只有一条斜杠,而是不两条。因为,plus.io.convertLocalFileSystemURL()函数获得的本地绝对路径,已经自带了一条斜杠。
- fontFamily的值,即iconfont2可以任意取。但iconfont.ttf文件内部的字体的名称必须足够特殊、不与系统注册的其他字体的名称冲突。
- “font-family: iconfont2;”必须直接放置于具体引用自定义字体的<text>标签的css中,而不能放置于<text>标签的父/祖标签的css中,否则自定义定体将不生效。例如:
<view class="mytext1"> <text class="mytext2">{{text}}</text> </view>data() { return { text: '\uE005' } }.mytext1 { font-family: iconfont2; } .mytext2 { font-family: iconfont2; }
在上述代码中,“.mytext1”由于没有直接作用于<text>标签,因而无效;“.mytext2”由于直接作用于<text>标签,所以有效。
补充:发现了一个巨坑:按照上述方法引用的自定义字体,仅在开发阶段(真机模拟时)有效,云打包之后仍然不能工作。
最新实测有效的建议:
在开发阶段,可采用 'src': 'url("'+"file:/" + plus.io.convertLocalFileSystemURL("_www/static/iconfont.ttf")+'")'这种写法,能在真机模拟时工作;开发完成后,打包时,可采用url('data:font/truetype;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQrD ....')这种写法,在真机运行和打包后都能够工作。在开发阶段,也可采用url('data:font/truetype;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQrD ....')这种写法,但不建议,原因在前文说过:干扰代码开发且不便于修改ttf文件。
另,附一个ttf文件转base64的网站
https://www.zhangxinxu.com/sp/base64.html
生成的base64,复制到HX新页面后,先将头部字符修改为data:font/truetype;charset=utf-8;base64,再复制到代码中。
阿里巴巴小程序繁星计划 9月27日有话要说
2019年9月27日,阿里巴巴小程序繁星计划峰会将于杭州云栖小镇召开。这是自今年3月阿里巴巴正式对外宣布全面开启小程序发展战略,阿里云携手支付宝、淘宝、钉钉、高德联合发布“阿里巴巴小程序繁星计划”,面向开发者和生态企业提供总计20亿元补助计划后的再一次重大发声。
目前小程序已成为互联网的新流量入口和新商业赛道。但是如何更好地赋能ISV、企业、开发者生态也成为行业核心问题。因此,本次峰会将重点围绕此话题进行相关解决方案发布,如小程序Serverless产品及扶持政策、商机转化场景案例等,帮助合作伙伴更好地推动小程序生态的升级与发展。
值得一提的是本次峰会还设置了“彩蛋”环节,这也是对阿里巴巴小程序发展历程的重要时刻记录,感兴趣的小程序开发者、企业、ISV一定要到现场共同见证。
<p style="text-align:center">
<p style="text-align:center">如此盛会怎能错过?</p>
<p style="text-align:center">争分夺秒,点击购票</p>
2019年9月27日,阿里巴巴小程序繁星计划峰会将于杭州云栖小镇召开。这是自今年3月阿里巴巴正式对外宣布全面开启小程序发展战略,阿里云携手支付宝、淘宝、钉钉、高德联合发布“阿里巴巴小程序繁星计划”,面向开发者和生态企业提供总计20亿元补助计划后的再一次重大发声。
目前小程序已成为互联网的新流量入口和新商业赛道。但是如何更好地赋能ISV、企业、开发者生态也成为行业核心问题。因此,本次峰会将重点围绕此话题进行相关解决方案发布,如小程序Serverless产品及扶持政策、商机转化场景案例等,帮助合作伙伴更好地推动小程序生态的升级与发展。
值得一提的是本次峰会还设置了“彩蛋”环节,这也是对阿里巴巴小程序发展历程的重要时刻记录,感兴趣的小程序开发者、企业、ISV一定要到现场共同见证。
<p style="text-align:center">
<p style="text-align:center">如此盛会怎能错过?</p>
<p style="text-align:center">争分夺秒,点击购票</p>

iOS上架被拒Guideline 5.1.1条款问题修改
iOS上架被拒Guideline 5.1.1条款问题解决步骤!
Guideline 5.1.1 - Legal - Privacy - Data Collection and Storage
We noticed that your app requests the user’s consent to access their camera/microphone but does not clarify the use of this feature in the permission modal alert.
Next Steps
To resolve this issue, please revise the permission modal alert to specify why the app is requesting access to the user's camera/microphone.
The permission request alert should specify how your app will use this feature to help users understand why your app is requesting access to their personal data.

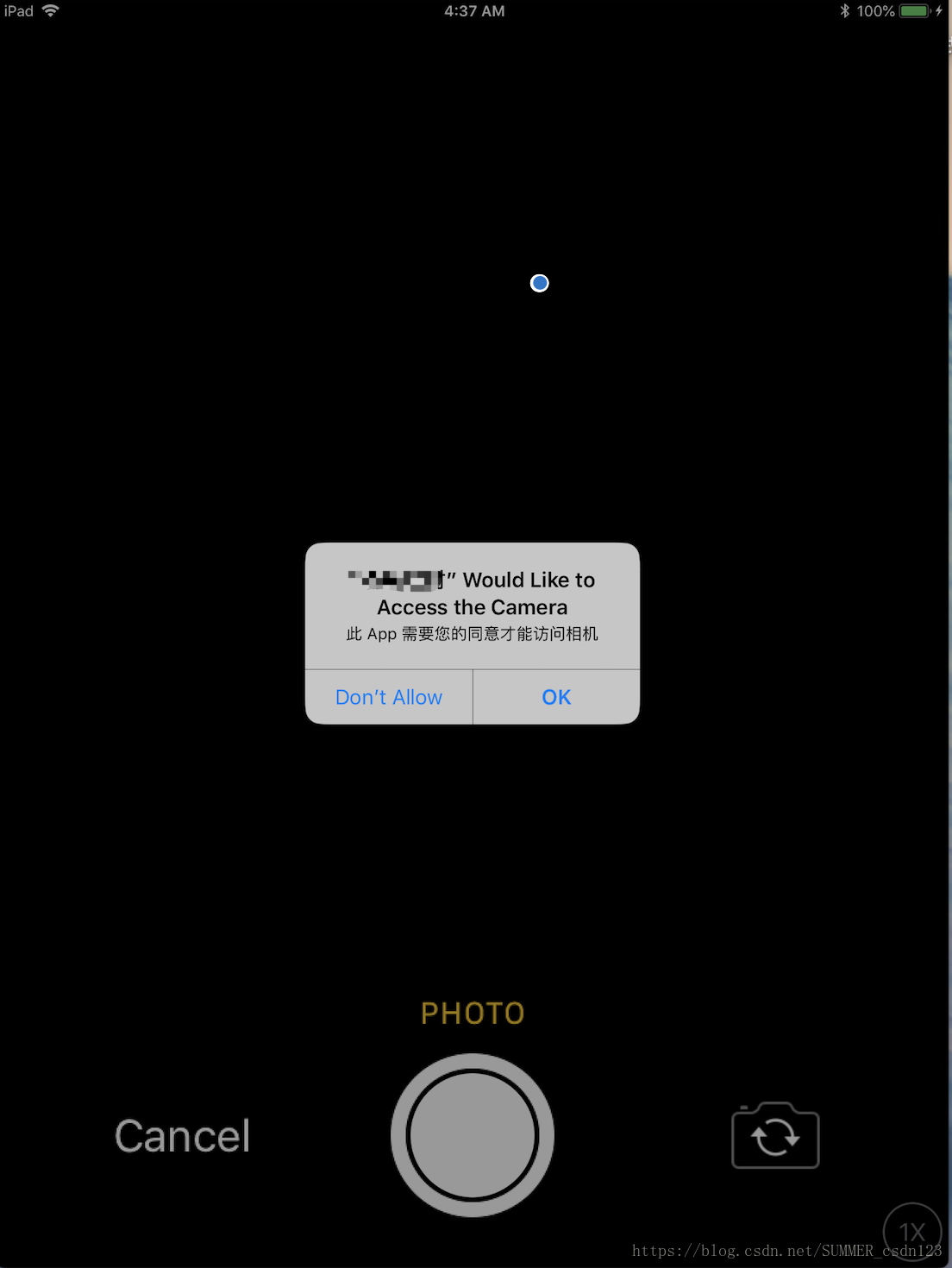
意思就是没有对请求的相关权限进行描述,或者描述的不够准确,比如使用到了定位,相册相机,通讯录等权限,要把为什么使用这些权限做下详细描述!
权限描述举例说明
比如一个外卖应用,获取定位后需要展示附近的美食信息。那么,相应的定位权限描述,应当是类似“获取定位信息用于为用户提供附近的美食信息”这样的描述。
而不应当是,“获取用户当前位置信息”这种没有明确描述定位用处的信息。
下面介绍两个常用Windows开发iOS工具的修改权限说明入口及例子!修改后重新打包上传审核!
HBuilderX开发工具修改入口!
打开manifest.json文件

iOS上架被拒Guideline 5.1.1条款问题解决步骤!
Guideline 5.1.1 - Legal - Privacy - Data Collection and Storage
We noticed that your app requests the user’s consent to access their camera/microphone but does not clarify the use of this feature in the permission modal alert.
Next Steps
To resolve this issue, please revise the permission modal alert to specify why the app is requesting access to the user's camera/microphone.
The permission request alert should specify how your app will use this feature to help users understand why your app is requesting access to their personal data.
意思就是没有对请求的相关权限进行描述,或者描述的不够准确,比如使用到了定位,相册相机,通讯录等权限,要把为什么使用这些权限做下详细描述!
权限描述举例说明
比如一个外卖应用,获取定位后需要展示附近的美食信息。那么,相应的定位权限描述,应当是类似“获取定位信息用于为用户提供附近的美食信息”这样的描述。
而不应当是,“获取用户当前位置信息”这种没有明确描述定位用处的信息。
下面介绍两个常用Windows开发iOS工具的修改权限说明入口及例子!修改后重新打包上传审核!
HBuilderX开发工具修改入口!
打开manifest.json文件
uni 批量上传图片
最近做一个项目,后台是php,碰到一个图片批量上传的问题,搜索过相关文章,发现是一个坑。所以发文分享一下经验,希望碰到同样问题的朋友可以少走些弯路。
其中用到了uni.uploadFile和uni.chooseImage两个api,这两个的具体用法和说明,官方有文档,不再赘述。
与后台约定的post传值key为uploads,内容为包含文件对象的数组
uni.chooseImage选择图片或者拍照,没有碰到问题,获取到返回对象为res,然后作为参数传入上传图片的方法
贴代码:
upimgs(res){
let that=this;
let imgs = res.tempFilePaths.map((value, index) => {
return {
name: "uploads["+index+"]",//注意这一行,uni的hello的示例中,这里为key名+index,这样是无法和使用一个固定key名接多个文件的php接口对接上的改为数组下标形式的字符串就解决这个问题了。其效果等同于在html页面上多个同name文件域同时提交表单。
uri: value
}
});
console.log(JSON.stringify(imgs));
uni.uploadFile({
url:"替换为你的接口地址",
files:imgs,
formData:{},
success: function(data){
//成功的回调函数
}
});
}最近做一个项目,后台是php,碰到一个图片批量上传的问题,搜索过相关文章,发现是一个坑。所以发文分享一下经验,希望碰到同样问题的朋友可以少走些弯路。
其中用到了uni.uploadFile和uni.chooseImage两个api,这两个的具体用法和说明,官方有文档,不再赘述。
与后台约定的post传值key为uploads,内容为包含文件对象的数组
uni.chooseImage选择图片或者拍照,没有碰到问题,获取到返回对象为res,然后作为参数传入上传图片的方法
贴代码:
upimgs(res){
let that=this;
let imgs = res.tempFilePaths.map((value, index) => {
return {
name: "uploads["+index+"]",//注意这一行,uni的hello的示例中,这里为key名+index,这样是无法和使用一个固定key名接多个文件的php接口对接上的改为数组下标形式的字符串就解决这个问题了。其效果等同于在html页面上多个同name文件域同时提交表单。
uri: value
}
});
console.log(JSON.stringify(imgs));
uni.uploadFile({
url:"替换为你的接口地址",
files:imgs,
formData:{},
success: function(data){
//成功的回调函数
}
});
}IOS上架时遇到NSBluetoothAlwaysUsageDescription问题的公告
iOS13修改了蓝牙权限申请描述文字的键名。
然后2019年9月18日,Appstore修改了审核规则,不符合调整的拒绝上线。详见Apple公告
如果开发者使用了蓝牙,需要在manifest.json里配置新描述。
首先更新到HBuilderX2.2.2+版本,打开应用的manifest.json文件,切换到代码视图。
- 如果是5+/wap2app项目,找到 "plus" -> "distribute" -> "apple" -> "privacyDescription" 节点
- 如果是uni-app项目,找到 "app-plus" -> "distribute" -> "ios" -> "privacyDescription" 节点
在"privacyDescription"节点下添加"NSBluetoothAlwaysUsageDescription",给用户说明你的App为什么要使用蓝牙,iOS会把你的原因描述文字弹框给用户,以便用户决定是否给予你的App使用蓝牙的权限。"privacyDescription" : { "NSBluetoothAlwaysUsageDescription" : "描述给用户使用蓝牙的原因(千万不要直接复制这段汉字提交)" }保存manifest后,重新提交云端打包。
如果开发者没有主动使用过蓝牙,但个推sdk老版本会使用蓝牙,也会造成这个问题。
使用HBuilderX 2.2.2+ 版本,重新打包,可避免这个问题。
之前已经升级HBuilderX但仍遇到问题的,请重新打包。
iOS13修改了蓝牙权限申请描述文字的键名。
然后2019年9月18日,Appstore修改了审核规则,不符合调整的拒绝上线。详见Apple公告
如果开发者使用了蓝牙,需要在manifest.json里配置新描述。
首先更新到HBuilderX2.2.2+版本,打开应用的manifest.json文件,切换到代码视图。
- 如果是5+/wap2app项目,找到 "plus" -> "distribute" -> "apple" -> "privacyDescription" 节点
- 如果是uni-app项目,找到 "app-plus" -> "distribute" -> "ios" -> "privacyDescription" 节点
在"privacyDescription"节点下添加"NSBluetoothAlwaysUsageDescription",给用户说明你的App为什么要使用蓝牙,iOS会把你的原因描述文字弹框给用户,以便用户决定是否给予你的App使用蓝牙的权限。"privacyDescription" : { "NSBluetoothAlwaysUsageDescription" : "描述给用户使用蓝牙的原因(千万不要直接复制这段汉字提交)" }保存manifest后,重新提交云端打包。
如果开发者没有主动使用过蓝牙,但个推sdk老版本会使用蓝牙,也会造成这个问题。
使用HBuilderX 2.2.2+ 版本,重新打包,可避免这个问题。
之前已经升级HBuilderX但仍遇到问题的,请重新打包。
收起阅读 »
分享几款不错的MUI框架手机app模板

服装包包手机商城模板
https://www.sucaihuo.com/templates/4490.html
手机app前端开发模板
https://www.sucaihuo.com/templates/3694.html
移动端app下载界面模板
https://www.sucaihuo.com/templates/4367.html
又一款服装商城app模板
https://www.sucaihuo.com/templates/5871.html
红酒酒类商城app模板
https://www.sucaihuo.com/templates/5769.html
服装包包手机商城模板
https://www.sucaihuo.com/templates/4490.html
手机app前端开发模板
https://www.sucaihuo.com/templates/3694.html
移动端app下载界面模板
https://www.sucaihuo.com/templates/4367.html
又一款服装商城app模板
https://www.sucaihuo.com/templates/5871.html
红酒酒类商城app模板
https://www.sucaihuo.com/templates/5769.html
安卓离线打包禁用屏幕旋转
最近发现离线打包出来的app居然会根据手机旋转屏幕,可是我明明已经在manifest.json里配置里只竖屏啊。论坛搜了半天也没发现离线打包怎么禁止屏幕旋转。
看了一下生成本地包打出来的manifest.json,发现orientation属性不见了,推测是这个属性只是给在线打包用的,所以生成离线打包资源时并没有带进去。
于是看了一下安卓工程,发现入口的PandoraEntry里有解析manifest.json的代码
if (var6 != null && var6.has("screenOrientation")) {
JSONArray var7 = var6.optJSONArray("screenOrientation");
if (var7 != null && var7.length() > 0) {
int var8 = this.a(var7);
var1.putExtra("__intetn_orientation__", var8);
}
}那我在编译完的manifest里加进去怎么样呢?。。。。还是不行!原来根本不会执行那段代码
//判断BaseInfo.SyncDebug属性,但是结果为false
if (BaseInfo.SyncDebug) {
this.a(var2);//此次执行解析
}坑啊!无奈只能在编译完的安装包里搜索了,然后发现生成完的安装包PandoraEntryActivity的orientation为2,应该就是这个了!试了一下,果然可以。
做法:手动在AndroidManifest.xml里添加注册,覆盖sdk的注册
<activity android:name="io.dcloud.PandoraEntryActivity"
tools:replace="android:screenOrientation"//指明覆盖原sdk注册的screenOrientation属性
android:screenOrientation="portrait"//设置方向为竖屏
></activity>希望官方完善文档吧,哎~~
最近发现离线打包出来的app居然会根据手机旋转屏幕,可是我明明已经在manifest.json里配置里只竖屏啊。论坛搜了半天也没发现离线打包怎么禁止屏幕旋转。
看了一下生成本地包打出来的manifest.json,发现orientation属性不见了,推测是这个属性只是给在线打包用的,所以生成离线打包资源时并没有带进去。
于是看了一下安卓工程,发现入口的PandoraEntry里有解析manifest.json的代码
if (var6 != null && var6.has("screenOrientation")) {
JSONArray var7 = var6.optJSONArray("screenOrientation");
if (var7 != null && var7.length() > 0) {
int var8 = this.a(var7);
var1.putExtra("__intetn_orientation__", var8);
}
}那我在编译完的manifest里加进去怎么样呢?。。。。还是不行!原来根本不会执行那段代码
//判断BaseInfo.SyncDebug属性,但是结果为false
if (BaseInfo.SyncDebug) {
this.a(var2);//此次执行解析
}坑啊!无奈只能在编译完的安装包里搜索了,然后发现生成完的安装包PandoraEntryActivity的orientation为2,应该就是这个了!试了一下,果然可以。
做法:手动在AndroidManifest.xml里添加注册,覆盖sdk的注册
<activity android:name="io.dcloud.PandoraEntryActivity"
tools:replace="android:screenOrientation"//指明覆盖原sdk注册的screenOrientation属性
android:screenOrientation="portrait"//设置方向为竖屏
></activity>希望官方完善文档吧,哎~~
iOS云打包如何设置通用链接等Capabilities配置
HBuilderX2.3.0开始云端打包支持配置XCode中的Capabilities
如下XCode配置
打开项目的manifest.json文件,在源码视图中进行配置
- 5 APP项目
在"plus" -> "distribute" -> "apple"添加"capabilities"节点 - uni-app项目
在"app-plus" -> "distribute" -> "ios"添加"capabilities"节点
"capabilities": {
"entitlements": { // 合并到工程entitlements文件的数据(json格式)
},
"plists": { // 合并到工程Info.plist文件的数据(json格式)
}
},其中entitlements数据(json)将转换成XCode工程中entitlements文件的数据(字典格式)
plists节点数据将转换成XCode工程中Info.plist文件的数据(字典格式)
<a id="unilink"/>
通用链接(Universal Link)
以下文档已过期,适用于:本地离线打包或者由于某种原因你需要用传统的方式:私有化部署服务器来托管apple-app-site-association文件创建通用链接。
推荐使用:一键生成iOS通用链接
Universal Link是苹果在WWDC 2015上提出的iOS 9的新特性之一。此特性类似于深层链接,并能够方便地通过打开一个Https链接来直接启动您的客户端应用(手机有安装App)。对比起以往所使用的URL Sheme, 这种新特性在实现web-app的无缝链接时能够提供极佳的用户体验。
使用前请阅读苹果官方文档
使用通用链接(Universal Link)必须要有域名,下的配置中将要用到
第一步:开启Associated Domains服务
登录苹果开发者网站,在“Certificates, Identifiers & Profiles”页面选择“Identifiers”中选择对应的App ID,确保开启Associated Domains服务
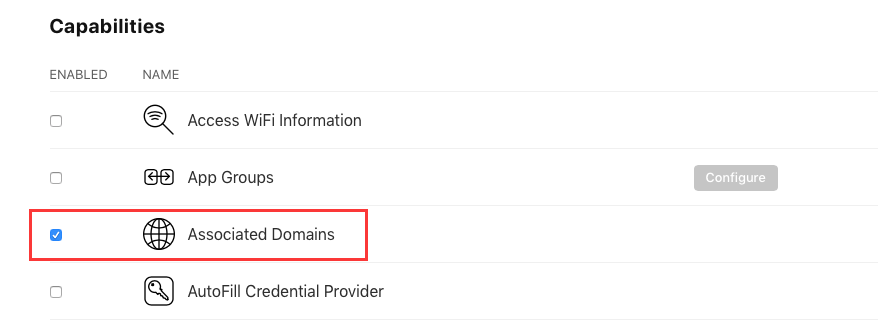
开启Associated Domains服务后需要重新生成profile文件,提交云端打包时使用
第二步:配置Associated Domains(域名)
原生XCode环境配置通用链接域名(本地离线打包配置,使用HBuilderX云端打包跳过)

使用HBuilderX云端打包时在manifest.json中配置域名
在"plus" -> "distribute" -> "apple" -> "capabilities" -> "entitlements"节点(uni-app项目在"app-plus" -> "distribute" -> "ios" -> "capabilities" -> "entitlements")下添加"com.apple.developer.associated-domains"字段,字段值为字符串数组,每个字符串为要关联的域名
"capabilities": {
"entitlements": {
"com.apple.developer.associated-domains": [
"applinks:demo.dcloud.net.cn"
]
}
}其中demo.dcloud.net.cn是应用通用链接的域名(这里不要包含path),请修改为自己应用要使用的域名
保存后提交云端打包生效。
HBuilderX中自带的默认真机运行基座HBuilderX注册的通用链接为:https://demo.dcloud.net.cn/ulink/
第三步:服务器配置apple-app-site-association文件
需要在上面域名对应的服务器上放apple-app-site-association文件。
apple-app-site-association文件配置如下:
{
"applinks": {
"apps": [],
"details": [
{
"appID": "G56NU654TV.io.dcloud.HBuilder",
"paths": [ "/ulink/*"]
}
]
}
}- apps
必须对应一个空的数组 - appID
由前缀和ID两部分组成,可以登录苹果开发者网站,在“Certificates, Identifiers & Profiles”页面选择“Identifiers”中选择对应的App ID查看 - paths
对应域名中的path,用于过滤可以跳转到App的链接,支持通配符*,?以及NOT进行匹配,匹配的优先级是从左至右依次降低
注意:不要直接拷贝使用上面的示例,必须根据自己应用的配置修改
把配置好的apple-app-site-association文件上传到你自己的服务器,确保通过https://demo.dcloud.net.cn/.well-known/apple-app-site-association可访问。
其中demo.dcloud.net.cn为上面配置的域名
应用安装后会通过访问上面的url向系统注册应用的通用链接。
推荐方案:将apple-app-site-association文件部署到,免费的阿里云版unicloud的 前端网页托管
客户端处理通用链接
可通过5+ API的plus.runtime.launcher判断应用启动来源,如果其值为"uniLink"则表示通过通用链接启动应。
这时可通过5+ API的plus.runtime.arguments获取启动参数,通用链接启动的情况将返回完整的通用链接地址。
注意事项
- apple-app-site-association文件不需要.json后缀
- 对apple-app-site-association文件的请求仅在App第一次启动时进行,如果此时网络连接出了问题apple会缓存请求,等有网的时候再去请求,如果没有请求此文件通用连接会失效
- iOS 9.2开始,在相同的domain内Universal Links不生效,必须要跨域才生效
微信配置通用链接参考:https://ask.dcloud.net.cn/article/36445
HBuilderX2.3.0开始云端打包支持配置XCode中的Capabilities
如下XCode配置
打开项目的manifest.json文件,在源码视图中进行配置
- 5 APP项目
在"plus" -> "distribute" -> "apple"添加"capabilities"节点 - uni-app项目
在"app-plus" -> "distribute" -> "ios"添加"capabilities"节点
"capabilities": {
"entitlements": { // 合并到工程entitlements文件的数据(json格式)
},
"plists": { // 合并到工程Info.plist文件的数据(json格式)
}
},其中entitlements数据(json)将转换成XCode工程中entitlements文件的数据(字典格式)
plists节点数据将转换成XCode工程中Info.plist文件的数据(字典格式)
<a id="unilink"/>
通用链接(Universal Link)
以下文档已过期,适用于:本地离线打包或者由于某种原因你需要用传统的方式:私有化部署服务器来托管apple-app-site-association文件创建通用链接。
推荐使用:一键生成iOS通用链接
Universal Link是苹果在WWDC 2015上提出的iOS 9的新特性之一。此特性类似于深层链接,并能够方便地通过打开一个Https链接来直接启动您的客户端应用(手机有安装App)。对比起以往所使用的URL Sheme, 这种新特性在实现web-app的无缝链接时能够提供极佳的用户体验。
使用前请阅读苹果官方文档
使用通用链接(Universal Link)必须要有域名,下的配置中将要用到
第一步:开启Associated Domains服务
登录苹果开发者网站,在“Certificates, Identifiers & Profiles”页面选择“Identifiers”中选择对应的App ID,确保开启Associated Domains服务
开启Associated Domains服务后需要重新生成profile文件,提交云端打包时使用
第二步:配置Associated Domains(域名)
原生XCode环境配置通用链接域名(本地离线打包配置,使用HBuilderX云端打包跳过)
使用HBuilderX云端打包时在manifest.json中配置域名
在"plus" -> "distribute" -> "apple" -> "capabilities" -> "entitlements"节点(uni-app项目在"app-plus" -> "distribute" -> "ios" -> "capabilities" -> "entitlements")下添加"com.apple.developer.associated-domains"字段,字段值为字符串数组,每个字符串为要关联的域名
"capabilities": {
"entitlements": {
"com.apple.developer.associated-domains": [
"applinks:demo.dcloud.net.cn"
]
}
}其中demo.dcloud.net.cn是应用通用链接的域名(这里不要包含path),请修改为自己应用要使用的域名
保存后提交云端打包生效。
HBuilderX中自带的默认真机运行基座HBuilderX注册的通用链接为:https://demo.dcloud.net.cn/ulink/
第三步:服务器配置apple-app-site-association文件
需要在上面域名对应的服务器上放apple-app-site-association文件。
apple-app-site-association文件配置如下:
{
"applinks": {
"apps": [],
"details": [
{
"appID": "G56NU654TV.io.dcloud.HBuilder",
"paths": [ "/ulink/*"]
}
]
}
}- apps
必须对应一个空的数组 - appID
由前缀和ID两部分组成,可以登录苹果开发者网站,在“Certificates, Identifiers & Profiles”页面选择“Identifiers”中选择对应的App ID查看 - paths
对应域名中的path,用于过滤可以跳转到App的链接,支持通配符*,?以及NOT进行匹配,匹配的优先级是从左至右依次降低
注意:不要直接拷贝使用上面的示例,必须根据自己应用的配置修改
把配置好的apple-app-site-association文件上传到你自己的服务器,确保通过https://demo.dcloud.net.cn/.well-known/apple-app-site-association可访问。
其中demo.dcloud.net.cn为上面配置的域名
应用安装后会通过访问上面的url向系统注册应用的通用链接。
推荐方案:将apple-app-site-association文件部署到,免费的阿里云版unicloud的 前端网页托管
客户端处理通用链接
可通过5+ API的plus.runtime.launcher判断应用启动来源,如果其值为"uniLink"则表示通过通用链接启动应。
这时可通过5+ API的plus.runtime.arguments获取启动参数,通用链接启动的情况将返回完整的通用链接地址。
注意事项
- apple-app-site-association文件不需要.json后缀
- 对apple-app-site-association文件的请求仅在App第一次启动时进行,如果此时网络连接出了问题apple会缓存请求,等有网的时候再去请求,如果没有请求此文件通用连接会失效
- iOS 9.2开始,在相同的domain内Universal Links不生效,必须要跨域才生效
微信配置通用链接参考:https://ask.dcloud.net.cn/article/36445
收起阅读 »web-view直接返回父页面的解决方案
在有web-view的页面,如果点击左上角的后退按钮,会返回到web-view中url的上一个页面,而不是回到APP的父页面
采用如下代码,点击左上角后退按钮就可以回到父页面。
onBackPress(options) {
const currentWebview = this.$mp.page.$getAppWebview();
if(currentWebview){
let child=currentWebview.children();
for(let i=0;i<child.length;i++){
currentWebview.remove(child[i]);
}
}
return false;
}
PS:不要采用currentWebview.close(),uniapp下不好用,各种出错
在有web-view的页面,如果点击左上角的后退按钮,会返回到web-view中url的上一个页面,而不是回到APP的父页面
采用如下代码,点击左上角后退按钮就可以回到父页面。
onBackPress(options) {
const currentWebview = this.$mp.page.$getAppWebview();
if(currentWebview){
let child=currentWebview.children();
for(let i=0;i<child.length;i++){
currentWebview.remove(child[i]);
}
}
return false;
}
PS:不要采用currentWebview.close(),uniapp下不好用,各种出错
收起阅读 »
从微信小程序转为uniapp开发注意事项
1、wx:for 改为 v-for (记得标记 :key )
2、wx:key="{{xxx}}" 改为 :key="xxx"
3、class="tab-item {{xx1==index?'aa1':''}}" 改为 :class="[xx1==index?'tab-item aa1':'tab-item']"
4、src="{{xxx}}" 改为 :src= "xxx"
5、src="{{xxx1}}/{{xxx2}}" 改为 :src= "xxx1+xxx2"
6、src="{{xxx1}}/xxx2.png" 改为 :src="xxx1 +'xxx2.png'"
7、scroll-left="{{xxx}}" 改为 :scroll-left="xxx"
8、id="{{index}}" 改为 :id="index"
9、bindtap 改为 @click
10、bind:submit 改为 @submit
11、style="{{xxx:aaa}}" 改为 :style="{xxx:aaa}" 注意xxx是驼峰式命名法
12、lazy-load="{{true}}" 改为 lazy-load="true"
13、this.data.xxx 改为 this.xxx
14、that.setData({ xxx: vvv }) 改为 this.xxx = vvv
1、wx:for 改为 v-for (记得标记 :key )
2、wx:key="{{xxx}}" 改为 :key="xxx"
3、class="tab-item {{xx1==index?'aa1':''}}" 改为 :class="[xx1==index?'tab-item aa1':'tab-item']"
4、src="{{xxx}}" 改为 :src= "xxx"
5、src="{{xxx1}}/{{xxx2}}" 改为 :src= "xxx1+xxx2"
6、src="{{xxx1}}/xxx2.png" 改为 :src="xxx1 +'xxx2.png'"
7、scroll-left="{{xxx}}" 改为 :scroll-left="xxx"
8、id="{{index}}" 改为 :id="index"
9、bindtap 改为 @click
10、bind:submit 改为 @submit
11、style="{{xxx:aaa}}" 改为 :style="{xxx:aaa}" 注意xxx是驼峰式命名法
12、lazy-load="{{true}}" 改为 lazy-load="true"
13、this.data.xxx 改为 this.xxx
14、that.setData({ xxx: vvv }) 改为 this.xxx = vvv
iOS上架被拒 Guideline 3.1.1问题解释
Guideline 3.1.1 - Business - Payments - In-App PurchaseWe noticed that your app uses in-app purchase products to purchase credits or currencies that are not consumed within the app, which is not appropriate for the App Store.
3.1.1问题就是支付方面没有做好。
因为苹果要求虚拟商品必须走IAP也就是苹果支付方式,不能使用支付宝微信支付。
当然实物商品是可以使用支付宝或者微信支付
所以如果遇到这种问题,确实是虚拟类商品比如说游戏的金币,道具等,还是要按规矩走苹果支付,通过隐藏第三方支付,来绕过审核这种方式也不怎么管用,苹果审核会扫代码!
有时可能没有做支付,但使用了支付宝SDK,微信和QQ SDK等,也可能反馈这个问题。
要把含有微信支付或者支付宝支付的注释或者方法名都删掉,耐心跟苹果回复沟通问题!
Guideline 3.1.1 - Business - Payments - In-App PurchaseWe noticed that your app uses in-app purchase products to purchase credits or currencies that are not consumed within the app, which is not appropriate for the App Store.
3.1.1问题就是支付方面没有做好。
因为苹果要求虚拟商品必须走IAP也就是苹果支付方式,不能使用支付宝微信支付。
当然实物商品是可以使用支付宝或者微信支付
所以如果遇到这种问题,确实是虚拟类商品比如说游戏的金币,道具等,还是要按规矩走苹果支付,通过隐藏第三方支付,来绕过审核这种方式也不怎么管用,苹果审核会扫代码!
有时可能没有做支付,但使用了支付宝SDK,微信和QQ SDK等,也可能反馈这个问题。
要把含有微信支付或者支付宝支付的注释或者方法名都删掉,耐心跟苹果回复沟通问题!
收起阅读 »